Clear Sky Science · tr
Açıklanabilir bir derin öğrenme çerçevesi: Gözetimsiz ana kare seçimi ve dikkat temelli CNN kullanarak video şiddet tespiti
Neden daha akıllı video denetimleri önemli
Sokak kameralarından, stadyumlardan ve sosyal medyadan her gün milyarlarca saatlik video akışı geliyor. Bu selin içinde, polis, güvenlik ekipleri ve çevrimiçi platformlar için son derece önemli olan kısa şiddet anları gizli. İnsan operatörler her şeyi izleyemez ve tehlikeli sahneleri işaretleyen günümüzün yapay zekâ sistemleri sıklıkla kara kutu gibi çalışır: doğru olabilirler ancak neden bir klibi şiddetli olarak sınıflandırdıklarını nadiren gösterirler. Bu makale, yalnızca şiddeti hızlı ve doğru şekilde tespit etmekle kalmayan, aynı zamanda kararına etki eden her karedeki bölümleri vurgulayarak makinenin gördüğüne insanların güvenmesini ve doğrulamasını kolaylaştıran yeni bir yapay zekâ çerçevesi sunar.
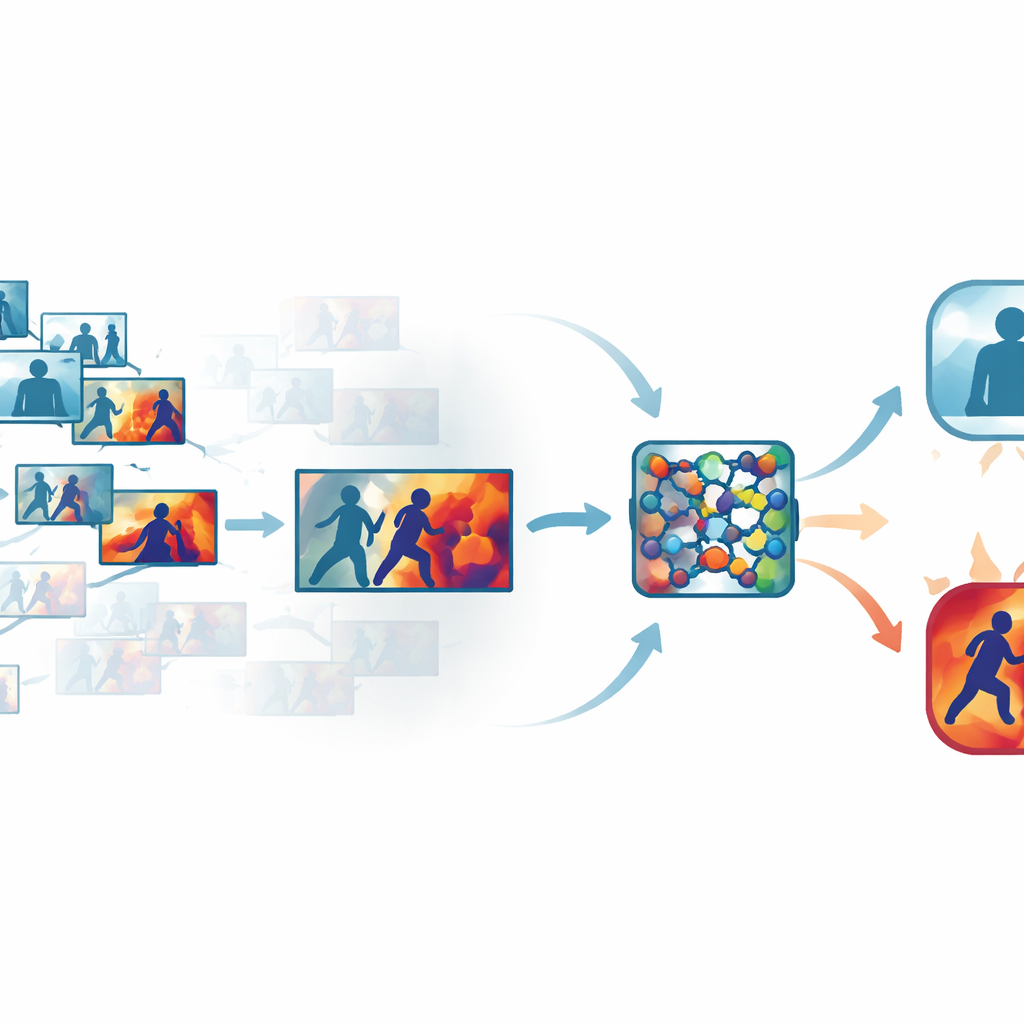
Kalabalık videolardaki gereksizi eleme
Standart güvenlik görüntülerinde, insanlar sadece yürürken veya dururken oluşan birbirinin neredeyse aynısı olan çok sayıda kare bulunur. Her kareyi işlemek zaman ve hesaplama gücü israfıdır; fakat çok fazla atlamak bir yumruğun atıldığı milisaniyeyi kaçırmaya neden olabilir. Yazarlar bunu, her klibi eleyip yalnızca gerçekten birbirinden farklı olan kareleri tutan otomatik bir “ana kare” aşaması kullanarak çözüyor. Zaman temelli basit örneklemeye dayanmak yerine sistem, hareket veya duruşta ince ama anlamlı değişikliklerin öne çıktığı öğrenilmiş bir görsel uzayda kareleri karşılaştırıyor. Birkaç kamu veri kümesi üzerinde bu yaklaşım, kısa hareket patlamalarını korurken orijinal karelerin yalnızca yaklaşık üçte birini tutmayı başardı.
Ağın nereye bakacağını öğretmek
En bilgilendirici kareler seçildikten sonra, bunlar kompakt bir konvolüsyonel sinir ağına gönderilir; bu, yaygın bir görüntü tanıma işçisidir. Burada yazarlar, ağ içinde bir spot ışığı gibi davranan dikkat modülleri ekliyor. Bu spot ışığının bir parçası hangi özellik kanallarının önemli hareket ve şekil bilgisini taşıdığını ağırlıklandırırken, diğeri etkileşimlerin gerçekleştiği kare içi belirli bölgeleri vurguluyor. Tüm pikselleri ve iç sinyalleri eşit derecede önemli kabul etmek yerine, ağ hızlı hareket eden kolları, yakın temasta olan bedenleri ve diğer belirgin desenleri öğrenerek odaklanmayı, statik arka planları, ışık değişimlerini veya kamera sarsıntısını ise geri plana atmayı öğreniyor. Bu, modeli dağınık, gerçek dünya sahnelerinde hem daha doğru hem de daha dayanıklı kılıyor.
Makinenin akıl yürütmesini görünür kılmak
Kara kutu tasarımından kaçınmak için çerçeve, Grad-CAM++ olarak bilinen bir yorumlanabilirlik katmanı içeriyor. Ağ karar verdikten sonra bu araç, içsel etkinliği geriye doğru izleyerek her kare üzerinde bir ısı haritası üretiyor ve “şiddetli” veya “şiddetsiz” hükmüne en çok etki eden bölgeleri vurguluyor. Şiddet içeren kliplerde parlak bölgeler genellikle fiziksel temas noktaları ve yoğun hareket etrafında kümelenirken; sakin kliplerde vurgular zayıf ve dağınık kalıyor. Bu görsel açıklamalar, sistemin ilgisiz ipuçları yerine anlamlı davranışlara mı odaklandığını doğrulamaya yardımcı oluyor ve ayrıca bir algoritmanın sonuca nasıl ulaştığını anlamanın sonucun kendisi kadar önemli olduğu adli incelemede destekleyici materyal olarak kullanılabiliyor.
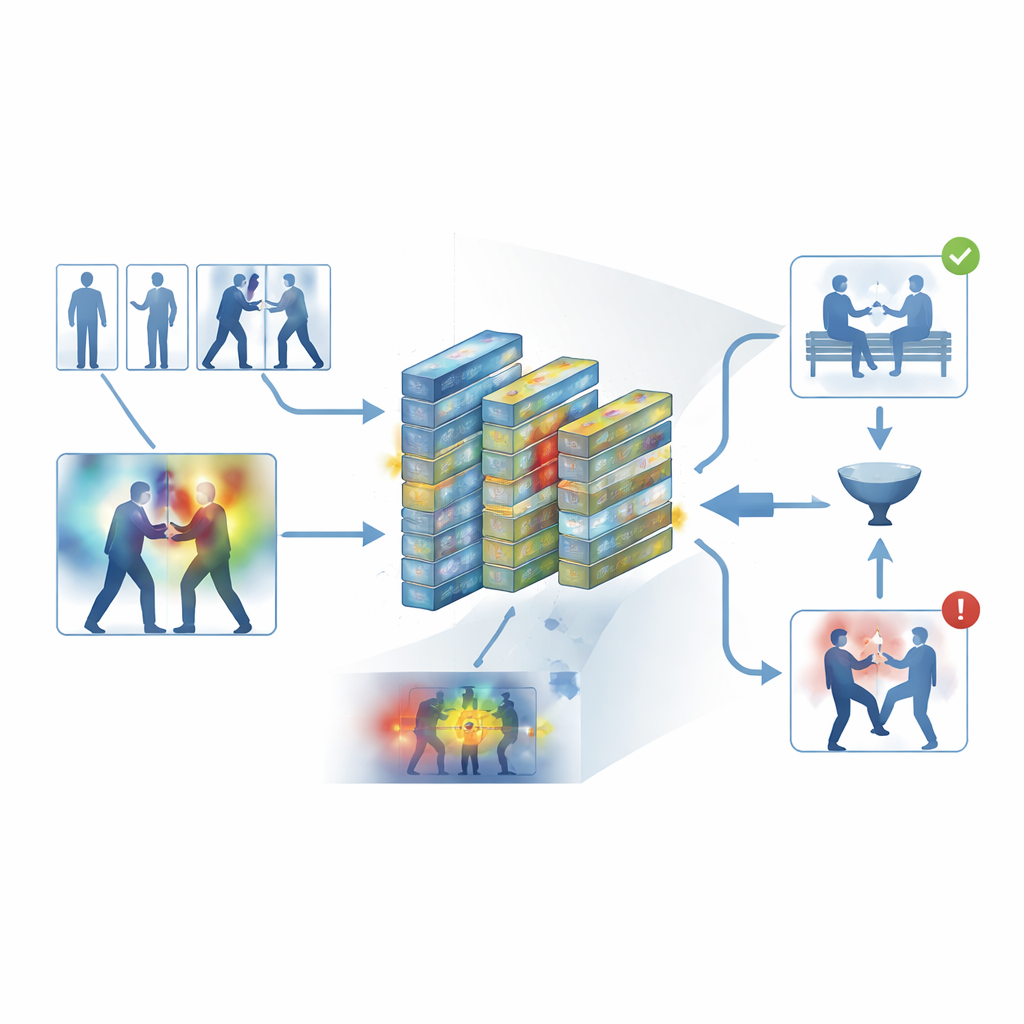
Sistemi teste koymak
Yazarlar çerçevelerini sokak kavgaları, hokey maçları, kalabalık kampüsler ve uzun güvenlik videoları dahil olmak üzere hem günlük kayıtları hem de özel gözetim görüntülerini kapsayan beş yaygın veri kümesi üzerinde eğitti ve değerlendirdi. Bu çeşitli kaynaklarda sistem yaklaşık yüzde 95 ortalama doğruluk elde etti ve modern donanımda saniyede yaklaşık 62 kare işledi—gerçek zamanlı izlemeye yetecek kadar hızlı. Bellek kullanımında daha az yer kaparken 3B konvolüsyonel ağlar, CNN–LSTM melezleri ve dönüştürücü tabanlı video modelleri gibi birkaç güçlü temel yöntemi tutarlı şekilde geride bıraktı. Özenle yapılan deneyler, hem ana kare filtresinin hem de dikkat modüllerinin performansa istatistiksel olarak anlamlı katkılar sağladığını ve modelin bir veri kümesinde eğitilip başka birinde test edildiğinde makul bir aktarım yeteneği gösterdiğini ortaya koydu.
Daha güvenli, daha şeffaf izleme için ne anlama geliyor
Uzman olmayanlar için ana mesaj şudur: Yazarlar yalnızca hızlı ve doğru olmakla kalmayan, aynı zamanda açıklanabilir bir video şiddet algılayıcısı geliştirdiler. Gereksiz kareleri eleyerek, iç dikkatini en ilgili harekete odaklayarak ve ardından her kararı vermek için "neye baktığını" görselleştirerek sistem, insan denetçilere daha şeffaf bir ortak sunuyor. Pratik olarak bu, güvenlik merkezlerinin ve çevrimiçi platformların daha az yanlış alarmla daha fazla akışı taramasına yardımcı olabilirken, insanların makinenin yargılarını incelemesine ve sorgulamasına da olanak tanır. Çalışma, video, ses ve yeni zamansal modelleri birleştiren gelecekteki sistemlere işaret ediyor; ancak ana katkısı, kamu alanlarını ve dijital platformları daha güvenli tutmak üzere tasarlanmış yapay zekâ araçlarında verimlilik ve açıklığın bir arada olabileceğini göstermektedir.
Atıf: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Anahtar kelimeler: video gözetimi, şiddet tespiti, açıklanabilir AI, dikkat temelli CNN, kamu güvenliği