Clear Sky Science · pl
Tłumaczalna ramowa struktura uczenia głębokiego do wykrywania przemocy w wideo z wykorzystaniem niesuperwizowanego wyboru kluczowych klatek i opartego na uwadze CNN
Dlaczego inteligentniejsze przeglądy wideo mają znaczenie
Miliardy godzin materiału wideo ze strumieni z kamer ulicznych, stadionów i mediów społecznościowych powstają każdego dnia. W tej fali ukryte są krótkie momenty przemocy, które mają kluczowe znaczenie dla policji, zespołów ochrony i platform internetowych. Operatorzy ludzie nie mogą oglądać wszystkiego, a współczesne systemy sztucznej inteligencji oznaczające niebezpieczne sceny często działają jak czarne skrzynki: mogą być skuteczne, ale rzadko pokazują, dlaczego uznały klip za przemocowy. Niniejszy artykuł przedstawia nową ramę AI, która nie tylko szybko i dokładnie wykrywa przemoc, lecz także uwypukla części każdej klatki, które zadecydowały o werdykcie, pomagając ludziom ufać i weryfikować to, co widzi maszyna.
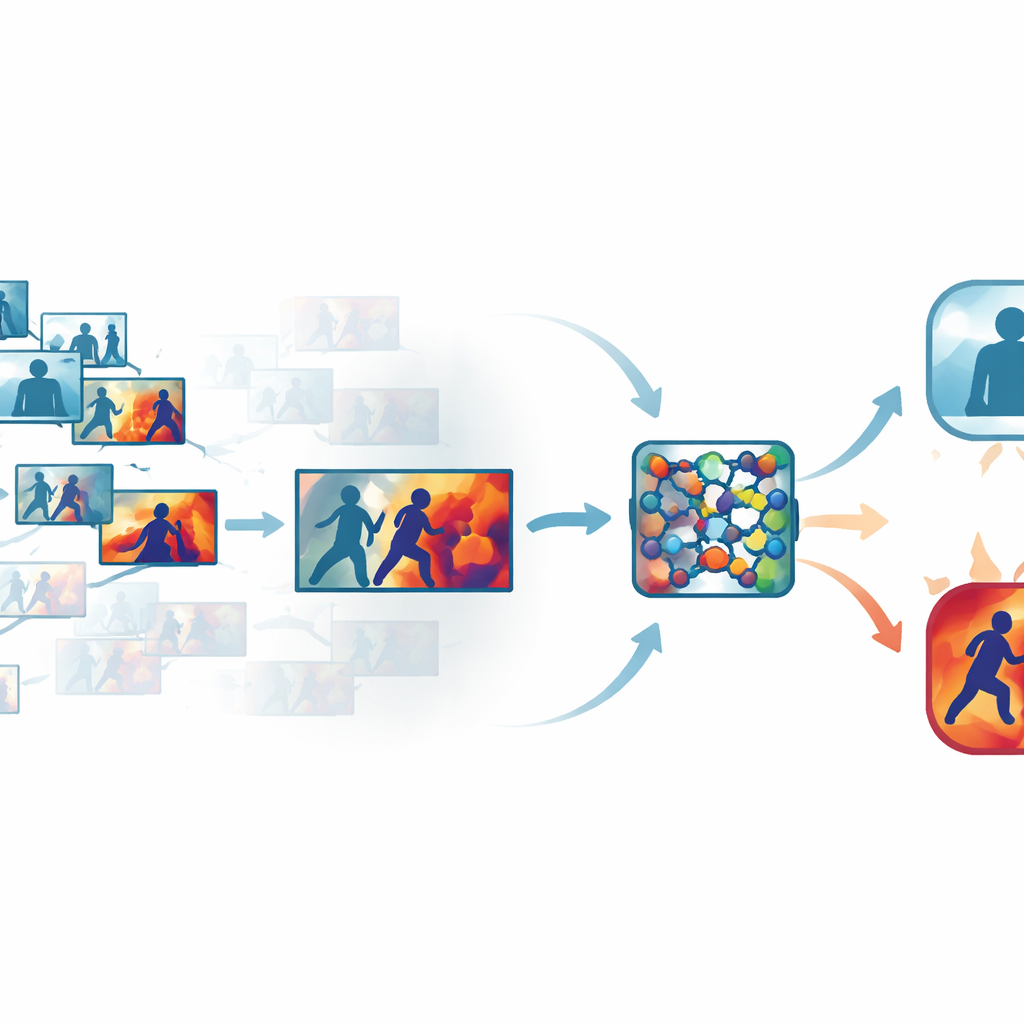
Oczyszczanie z nadmiaru klatek w zatłoczonym wideo
Standardowe nagrania z systemów bezpieczeństwa zawierają wiele niemal identycznych klatek, na przykład długie fragmenty z ludźmi po prostu idącymi lub stojącymi. Przetwarzanie każdej klatki marnuje czas i zasoby obliczeniowe, a jednocześnie nadmierne pomijanie może przeoczyć ułamek sekundy, gdy pada cios. Autorzy rozwiązują ten problem, stosując zautomatyzowany etap wyboru „kluczowych klatek”, który przesiewa każdy klip i zachowuje tylko te klatki, które rzeczywiście różnią się od siebie. Zamiast polegać na prostym próbkowaniu czasowym, system porównuje klatki w wyuczonej przestrzeni wizualnej, gdzie subtelne, ale znaczące zmiany w ruchu lub postawie wyróżniają się. Na kilku publicznych zbiorach danych podejście to zachowywało tylko około jednej trzeciej oryginalnych klatek, jednocześnie zachowując krótkie wybuchy ruchu sygnalizujące przemoc.
Uczenie sieci, gdzie patrzeć
Gdy wybierane są najbardziej informacyjne klatki, trafiają one do zwartej konwolucyjnej sieci neuronowej, powszechnego narzędzia rozpoznawania obrazów. Autorzy dodają do niej moduły uwagi, które działają jak reflektor wewnątrz sieci. Jedna część tego reflektora ocenia, które kanały cech niosą ważne informacje o ruchu i kształcie, podczas gdy inna podkreśla konkretne regiony każdej klatki, gdzie zachodzą interakcje. Zamiast traktować wszystkie piksele i wszystkie wewnętrzne sygnały jako jednakowo istotne, sieć uczy się koncentrować na szybko poruszających się ramionach, ciałach w bliskim kontakcie i innych charakterystycznych wzorcach, jednocześnie marginalizując statyczne tło, zmiany oświetlenia czy drgania kamery. Dzięki temu model staje się zarówno bardziej precyzyjny, jak i bardziej odporny w chaotycznych, rzeczywistych scenach.
Ujawnianie rozumowania maszyny
Aby uniknąć projektu typu czarna skrzynka, rama zawiera warstwę interpretowalności znaną jako Grad-CAM++. Po podjęciu przez sieć decyzji to narzędzie sięga do jej wewnętrznej aktywności i generuje mapę ciepła na każdej klatce, podkreślając obszary, które najbardziej wpłynęły na werdykt „przemocowy” lub „nieprzemocowy”. W klipach przemocowych jasne regiony mają tendencję do grupowania się wokół punktów kontaktu fizycznego i intensywnego ruchu; w spokojnych nagraniach podświetlenia są słabe i rozproszone. Te wizualne wyjaśnienia pomagają operatorom potwierdzić, że system skupia się na znaczących zachowaniach, a nie na nieistotnych wskazówkach, i mogą służyć jako materiał pomocniczy w przeglądzie kryminalistycznym, gdzie zrozumienie, jak algorytm doszedł do wniosku, jest równie ważne jak sam wniosek.
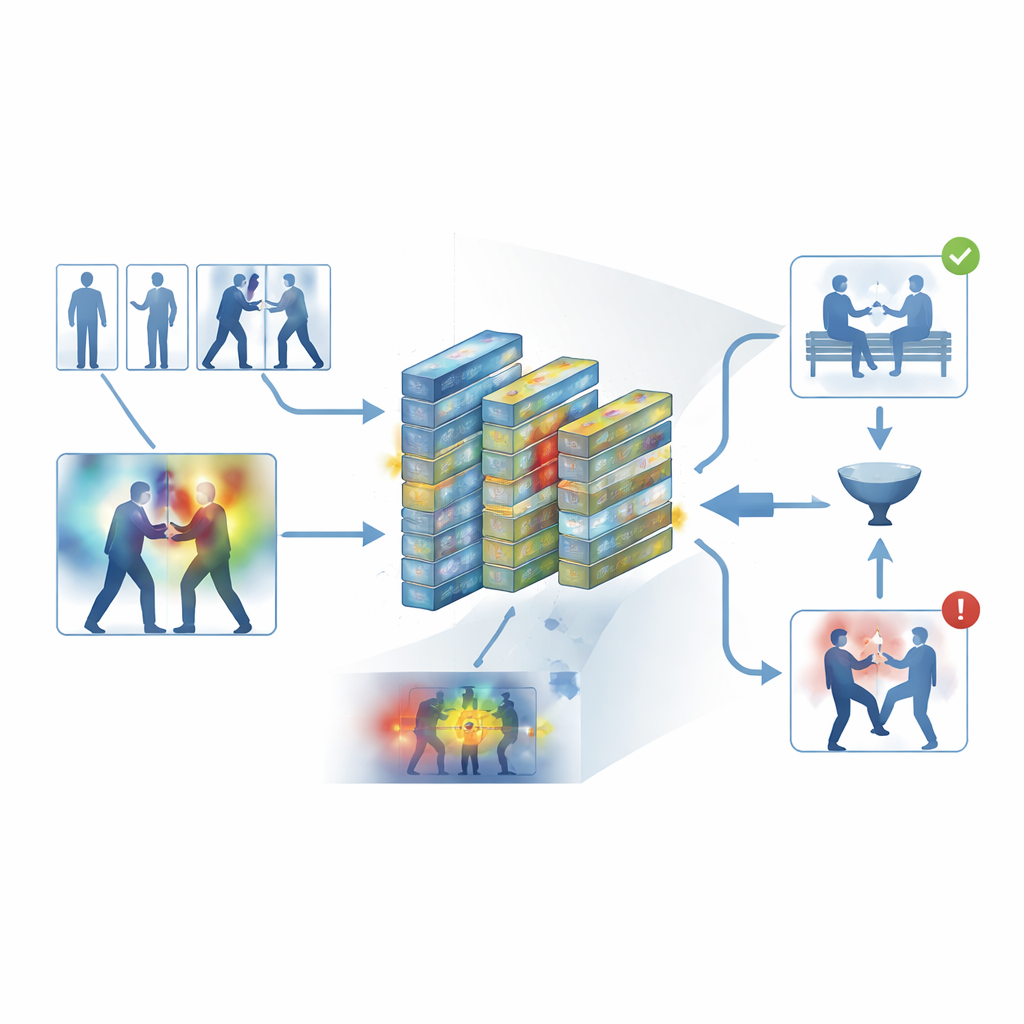
Próba systemu w działaniu
Autorzy trenowali i oceniali swoją ramę na pięciu powszechnie stosowanych zbiorach danych obejmujących zarówno codzienne nagrania, jak i dedykowane materiały z monitoringu, w tym uliczne bójki, mecze hokeja, zatłoczone kampusy oraz długie nagrania z systemów bezpieczeństwa. W tych różnorodnych źródłach system osiągnął średnią dokładność około 95 procent i przetwarzał około 62 klatek na sekundę na nowoczesnym sprzęcie — wystarczająco szybko do monitoringu w czasie rzeczywistym. System konsekwentnie przewyższał kilka silnych bazowych modeli, takich jak sieci konwolucyjne 3D, hybrydy CNN–LSTM i modele wideo oparte na transformatorach, przy jednoczesnym mniejszym zużyciu pamięci. Starannie przeprowadzone eksperymenty wykazały, że zarówno filtr kluczowych klatek, jak i moduły uwagi wnosiły statystycznie istotny wkład w wydajność, a model radził sobie stosunkowo dobrze przy transferze, gdy trenowano go na jednym zbiorze danych, a testowano na innym.
Co to znaczy dla bezpieczniejszego, bardziej przejrzystego monitoringu
Dla osób niebędących specjalistami kluczowy przekaz jest taki, że autorzy zbudowali detektor przemocy w wideo, który jest nie tylko szybki i dokładny, ale też wytłumaczalny. Poprzez usuwanie nadmiarowych klatek, ukierunkowywanie wewnętrznej uwagi na najbardziej istotny ruch oraz wizualizowanie tego, na co „patrzył” model przy podejmowaniu decyzji, system oferuje bardziej przejrzystego partnera dla ludzkich nadzorców. W praktyce może to pomóc centrom bezpieczeństwa i platformom internetowym skanować więcej strumieni przy mniejszej liczbie fałszywych alarmów, przy jednoczesnym umożliwieniu ludziom inspekcji i kwestionowania osądów maszyny. Praca ta wskazuje kierunek dla przyszłych systemów łączących wideo, dźwięk i nowsze modele temporalne, ale jej głównym wkładem jest pokazanie, że efektywność i przejrzystość mogą współistnieć w narzędziach AI zaprojektowanych do ochrony przestrzeni publicznych i platform cyfrowych.
Cytowanie: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Słowa kluczowe: monitoring wideo, wykrywanie przemocy, wytłumaczalna sztuczna inteligencja, CNN oparte na mechanizmie uwagi, bezpieczeństwo publiczne