Clear Sky Science · fr
Un cadre d’apprentissage profond explicable pour la détection de violence dans la vidéo utilisant une sélection non supervisée de keyframes et un CNN basé sur l’attention
Pourquoi des contrôles vidéo plus intelligents comptent
Des milliards d’heures de flux vidéo provenant de caméras de rue, de stades et des réseaux sociaux sont générées chaque jour. Dans cette masse se cachent de brefs instants de violence qui importent énormément pour la police, les équipes de sécurité et les plateformes en ligne. Les opérateurs humains ne peuvent pas tout surveiller, et les systèmes d’intelligence artificielle actuels qui signalent des scènes dangereuses fonctionnent souvent comme des boîtes noires : ils peuvent être précis, mais montrent rarement pourquoi ils ont jugé un extrait violent. Cet article présente un nouveau cadre d’IA qui non seulement détecte la violence rapidement et avec précision, mais met aussi en évidence les parties de chaque image qui ont motivé sa décision, aidant ainsi les personnes à faire confiance et à vérifier ce que la machine perçoit.
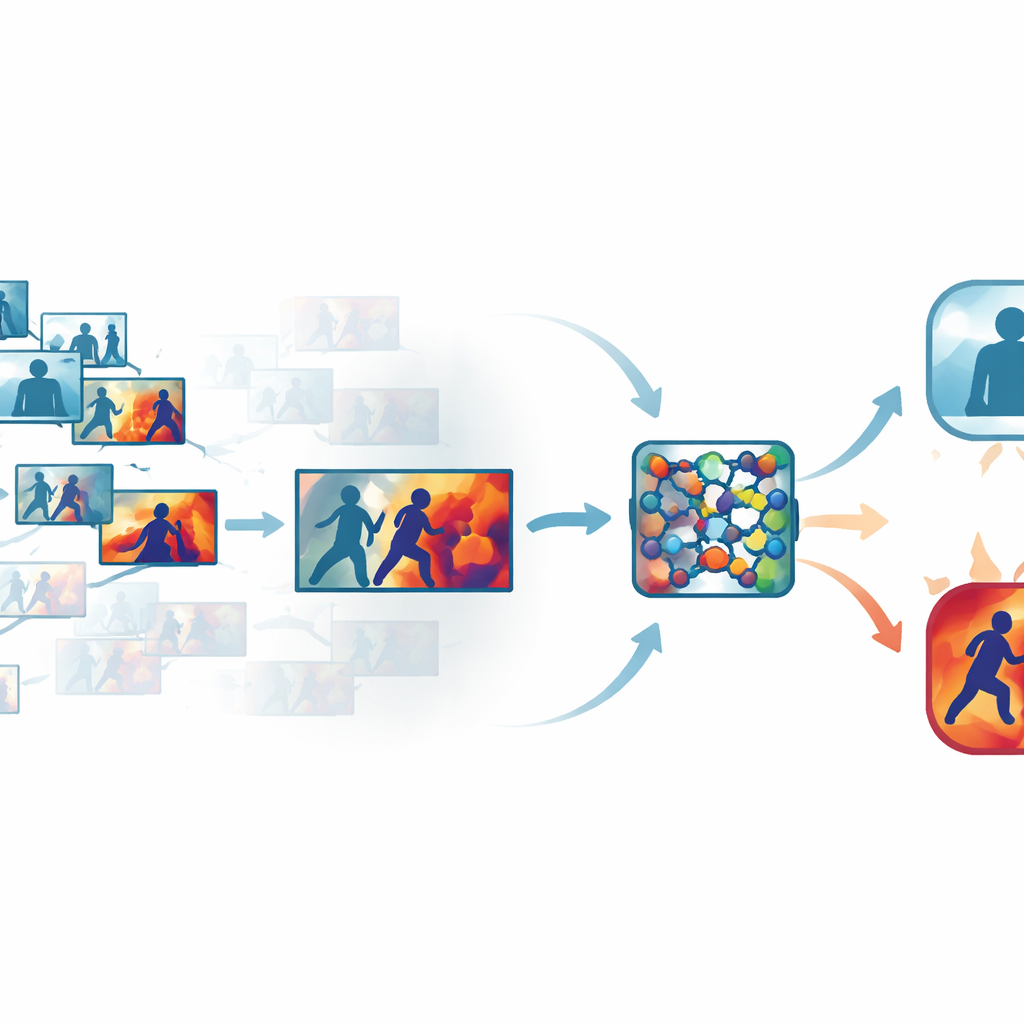
Éliminer le superflu dans les vidéos encombrées
Les séquences de surveillance classiques contiennent de nombreuses images presque identiques, comme de longues plages de personnes qui marchent ou restent immobiles. Traiter chaque image fait perdre du temps et des ressources informatiques, mais en sauter trop peut rater la fraction de seconde où un coup est porté. Les auteurs s’attaquent à ce problème en utilisant une étape automatisée de sélection de « keyframes » qui filtre chaque extrait et ne conserve que les images réellement différentes les unes des autres. Plutôt que de s’appuyer sur un échantillonnage temporel simple, le système compare les images dans un espace visuel appris, où les changements subtils mais significatifs de mouvement ou de posture ressortent. Sur plusieurs jeux de données publics, cette approche n’a conservé qu’environ un tiers des images d’origine tout en préservant les brèves manifestations de mouvement qui signalent la violence.
Apprendre à un réseau où regarder
Une fois les images les plus informatives choisies, elles sont envoyées dans un réseau neuronal convolutif compact, un outil courant de reconnaissance d’images. Ici, les auteurs ajoutent des modules d’attention qui agissent comme un projecteur à l’intérieur du réseau. Une partie de ce projecteur pondère les canaux de caractéristiques qui véhiculent des informations importantes sur le mouvement et la forme, tandis qu’une autre met l’accent sur les régions spécifiques de chaque image où se déroulent des interactions. Au lieu de considérer tous les pixels et tous les signaux internes comme également importants, le réseau apprend à se concentrer sur des bras qui bougent rapidement, des corps en contact étroit et d’autres motifs révélateurs, tout en atténuant l’importance des arrière-plans statiques, des changements d’éclairage ou des secousses de caméra. Cela rend le modèle à la fois plus précis et plus robuste dans des scènes réelles et encombrées.
Rendre visible le raisonnement de la machine
Pour éviter une conception en boîte noire, le cadre intègre une couche d’interprétabilité connue sous le nom de Grad-CAM++. Après que le réseau a pris une décision, cet outil remonte son activité interne pour produire une carte thermique sur chaque image, mettant en relief les zones qui ont le plus influencé le verdict « violent » ou « non violent ». Dans les extraits violents, les régions lumineuses ont tendance à se concentrer autour des points de contact physique et des mouvements intenses ; dans les extraits calmes, les mises en évidence restent faibles et diffuses. Ces explications visuelles aident les opérateurs à confirmer que le système se base sur des comportements significatifs plutôt que sur des indices non pertinents, et peuvent aussi servir de support lors d’expertises médico-légales, où comprendre comment un algorithme est parvenu à sa conclusion est aussi important que la conclusion elle-même.
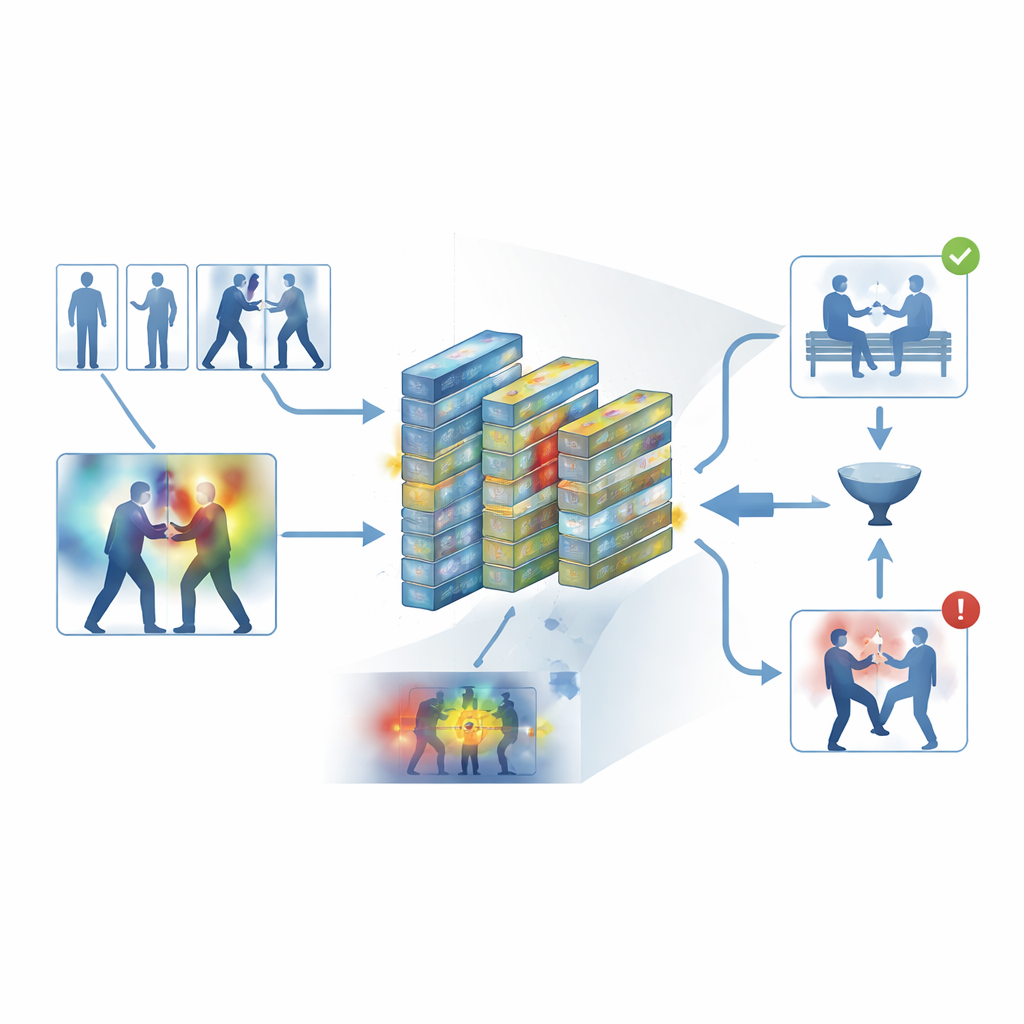
Mettre le système à l’épreuve
Les auteurs ont entraîné et évalué leur cadre sur cinq jeux de données largement utilisés couvrant à la fois des enregistrements de la vie quotidienne et des vidéos de surveillance dédiées, incluant des altercations de rue, des matchs de hockey, des campus bondés et de longues vidéos de sécurité. Sur ces sources diverses, le système a atteint une précision moyenne d’environ 95 % et a traité environ 62 images par seconde sur du matériel moderne — assez rapide pour une surveillance en temps réel. Il a systématiquement surpassé plusieurs références solides, telles que les réseaux convolutionnels 3D, les hybrides CNN–LSTM et les modèles vidéo basés sur des transformers, tout en consommant moins de mémoire. Des expériences soignées ont montré que tant le filtre de keyframes que les modules d’attention apportaient des contributions statistiquement significatives aux performances, et que le modèle se transférait raisonnablement bien lorsqu’il était entraîné sur un jeu de données et testé sur un autre.
Ce que cela signifie pour une surveillance plus sûre et plus transparente
Pour les non-spécialistes, le message clé est que les auteurs ont construit un détecteur de violence vidéo qui est non seulement rapide et précis, mais aussi explicable. En éliminant les images redondantes, en concentrant son attention interne sur les mouvements les plus pertinents, puis en visualisant ce qu’il « a regardé » pour rendre chaque décision, le système propose un partenaire plus transparent pour les superviseurs humains. En pratique, cela pourrait aider les centres de sécurité et les plateformes en ligne à analyser davantage de flux avec moins de fausses alertes, tout en permettant aux personnes d’inspecter et de contester les jugements de la machine. Ce travail ouvre la voie à de futurs systèmes combinant vidéo, audio et modèles temporels plus récents, mais sa contribution principale est de démontrer que l’efficacité et la clarté peuvent coexister dans des outils d’IA conçus pour rendre les espaces publics et les plateformes numériques plus sûrs.
Citation: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Mots-clés: surveillance vidéo, détection de violence, IA explicable, CNN basé sur l’attention, sécurité publique