Clear Sky Science · de
Ein erklärbares Deep-Learning‑Framework zur Erkennung von Gewalt in Videos mittels unbeaufsichtigter Keyframe‑Auswahl und aufmerksamkeitsbasierter CNNs
Warum klügere Video‑Kontrollen wichtig sind
Milliarden Stunden an Videostreams von Straßencams, Stadionaufnahmen und sozialen Medien werden täglich erzeugt. Versteckt in dieser Flut liegen kurze Gewaltausbrüche, die für Polizei, Sicherheitsdienste und Online‑Plattformen von großer Bedeutung sind. Menschen können nicht alles überwachen, und heutige KI‑Systeme, die gefährliche Szenen melden, arbeiten oft wie Black‑Boxes: Sie sind zwar möglicherweise genau, zeigen aber selten, warum sie ein Clip als gewalttätig eingestuft haben. Dieses Paper stellt ein neues KI‑Framework vor, das Gewalt nicht nur schnell und präzise erkennt, sondern auch die Bildbereiche hervorhebt, die die Entscheidung beeinflusst haben, sodass Menschen der Maschine eher vertrauen und ihre Ergebnisse prüfen können.
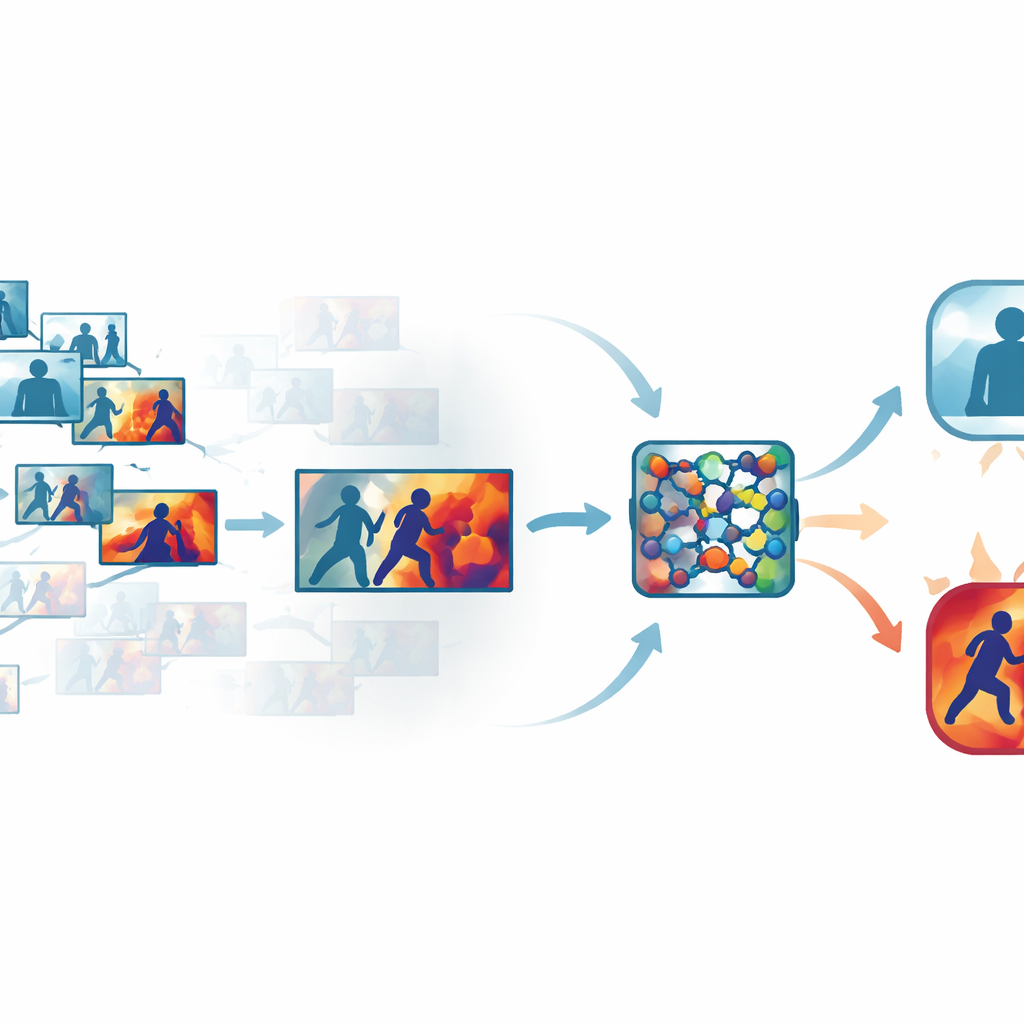
Störendes Material in überfüllten Videos entfernen
Standard‑Überwachungsaufnahmen enthalten viele nahezu identische Frames, etwa lange Abschnitte, in denen Menschen lediglich gehen oder stehen. Jedes Frame zu verarbeiten verschwendet Zeit und Rechenleistung, doch zu viel zu überspringen kann die Millisekunde verpassen, in der ein Schlag ausgeführt wird. Die Autoren begegnen dem mit einer automatisierten Keyframe‑Stufe, die Clips durchsiebt und nur jene Frames behält, die sich wirklich voneinander unterscheiden. Anstatt simple zeitbasierte Abtastung zu verwenden, vergleicht das System Frames in einem gelernten visuellen Raum, in dem subtile, aber aussagekräftige Veränderungen in Bewegung oder Haltung hervortreten. In mehreren öffentlichen Datensätzen reduzierte dieser Ansatz die Anzahl der Frames auf etwa ein Drittel der Originalmenge, während kurzzeitige Bewegungsimpulse, die auf Gewalt hindeuten, erhalten blieben.
Dem Netzwerk beibringen, wo es hinschauen soll
Nachdem die informativsten Frames ausgewählt wurden, werden sie durch ein kompaktes Convolutional Neural Network geschickt, einen gängigen Arbeitspferd der Bilderkennung. Hier ergänzen die Autoren das Modell um Aufmerksamkeitsmodule, die wie ein Scheinwerfer innerhalb des Netzwerks wirken. Ein Teil dieses Scheinwerfers gewichtet, welche Merkmalskanäle wichtige Informationen zu Bewegung und Form tragen, während ein anderer die konkreten Regionen jedes Frames betont, in denen Interaktionen stattfinden. Anstatt alle Pixel und internen Signale gleich zu behandeln, lernt das Netzwerk, sich auf schnell bewegte Arme, eng aneinander liegende Körper und andere typische Muster zu konzentrieren, während statische Hintergründe, Lichtänderungen oder Kamerawackler heruntergewichtet werden. Das macht das Modell sowohl genauer als auch robuster in unordentlichen, realen Szenen.
Die Entscheidungslogik der Maschine sichtbar machen
Um ein Black‑Box‑Design zu vermeiden, integriert das Framework eine Interpretationsschicht, bekannt als Grad‑CAM++. Nachdem das Netzwerk eine Entscheidung getroffen hat, verfolgt dieses Werkzeug die interne Aktivität zurück und erzeugt eine Heatmap über jedem Frame, die Bereiche hervorhebt, die die Entscheidung für „gewalttätig“ oder „nicht gewalttätig“ am stärksten beeinflusst haben. In gewalttätigen Clips konzentrieren sich die hellen Regionen typischerweise um Körperkontaktpunkte und intensive Bewegung; in ruhigen Clips bleiben die Hervorhebungen schwach und diffus. Diese visuellen Erklärungen helfen Bedienern zu bestätigen, dass das System sich auf aussagekräftiges Verhalten und nicht auf irrelevante Hinweise stützt, und können auch als unterstützendes Material in forensischen Prüfungen dienen, bei denen das Verständnis, wie ein Algorithmus zu seiner Schlussfolgerung gelangt ist, ebenso wichtig ist wie die Schlussfolgerung selbst.
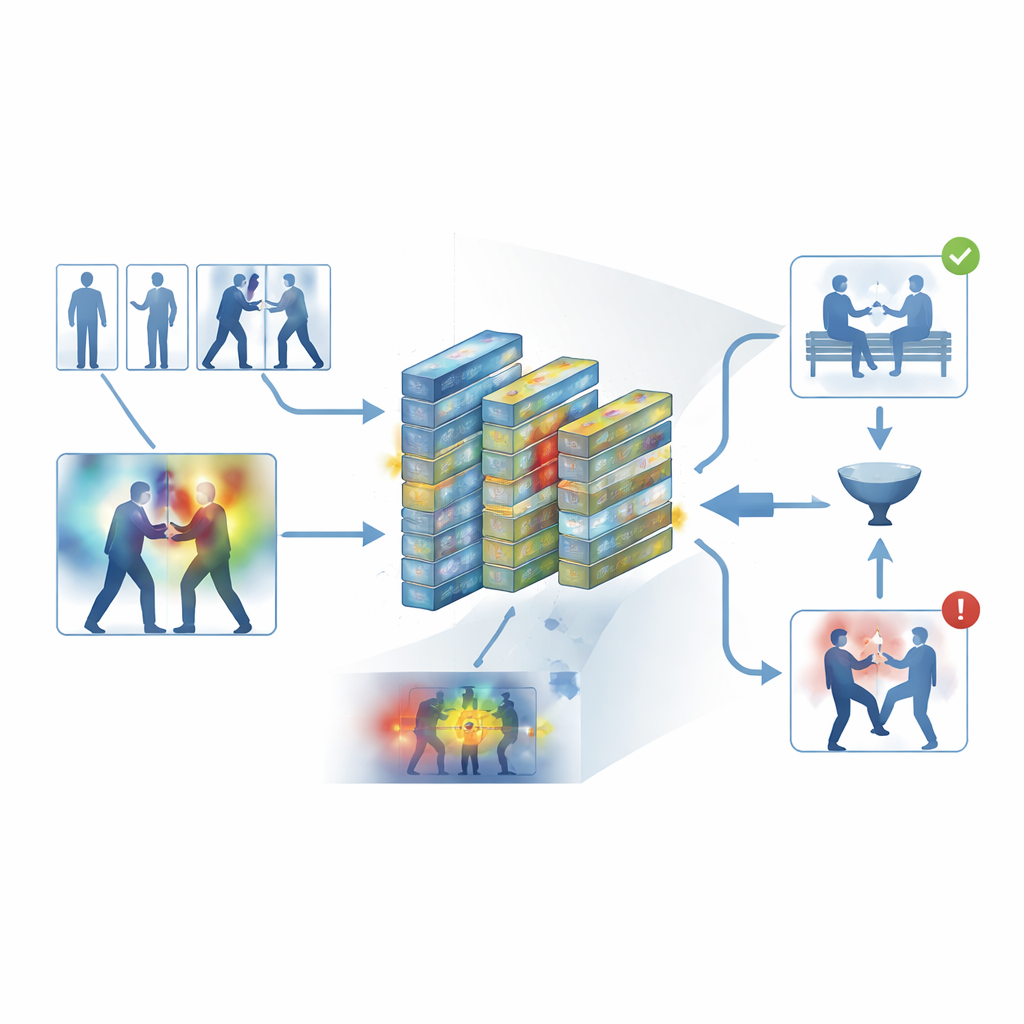
Das System auf die Probe stellen
Die Autoren trainierten und evaluierten ihr Framework auf fünf weit verbreiteten Datensätzen, die sowohl Alltagsaufnahmen als auch spezialisierte Überwachungsaufnahmen abdecken, darunter Straßenkonflikte, Eishockeyspiele, überfüllte Campusbereiche und lange Sicherheitsvideos. Über diese vielfältigen Quellen hinweg erzielte das System eine durchschnittliche Genauigkeit von etwa 95 Prozent und verarbeitete auf moderner Hardware rund 62 Frames pro Sekunde — schnell genug für Echtzeit‑Monitoring. Es übertraf konsequent mehrere starke Baseline‑Modelle, wie 3D‑Convolutional‑Netze, CNN–LSTM‑Hybride und transformerbasierte Videomodelle, bei geringerem Speicherbedarf. Sorgfältige Experimente zeigten, dass sowohl der Keyframe‑Filter als auch die Aufmerksamkeitsmodule statistisch signifikante Beiträge zur Leistung leisteten und dass das Modell beim Transferieren von einem Datensatz auf einen anderen relativ gut generalisierte.
Was das für sicherere, klarere Überwachung bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft, dass die Autoren einen Video‑Gewalt‑Detektor entwickelt haben, der nicht nur schnell und genau, sondern auch erklärbar ist. Indem redundante Frames entfernt, die interne Aufmerksamkeit auf die relevanteste Bewegung fokussiert und anschließend visualisiert wird, worauf das System bei seiner Entscheidung „hingeschaut“ hat, bietet das System einen transparenteren Partner für menschliche Aufseher. Praktisch könnte dies Sicherheitszentren und Online‑Plattformen helfen, mehr Feeds mit weniger Fehlalarmen zu prüfen und zugleich Menschen die Möglichkeit geben, die Urteile der Maschine zu prüfen und zu hinterfragen. Die Arbeit weist auf künftige Systeme hin, die Video, Audio und neuere temporale Modelle kombinieren; ihr Hauptbeitrag besteht jedoch darin zu zeigen, dass Effizienz und Nachvollziehbarkeit in KI‑Werkzeugen, die öffentliche Räume und digitale Plattformen sicherer machen sollen, koexistieren können.
Zitation: Azim, R., Abbas, N., Alkahtani, H.K. et al. An explainable deep learning framework for video violence detection using unsupervised keyframe selection and attention-based CNN. Sci Rep 16, 11098 (2026). https://doi.org/10.1038/s41598-026-40977-7
Schlüsselwörter: Videoüberwachung, Gewaltserkennung, erklärbare KI, aufmerksamkeitsbasiertes CNN, öffentliche Sicherheit