Clear Sky Science · zh
用于高光谱与 LiDAR 图像的锚点引导多视角模糊聚类
更清晰地观测地球
从作物健康到城市扩张,卫星现在以惊人的细节监视着我们的星球。但不同传感器对同一地点的观测方式大相径庭:有的记录植被的细微颜色变化,另一些则捕捉建筑与地形的精确形状。本研究提出了一种新的自动方法,通过结合这些对比鲜明的视角,将地面区域分组成有意义的类别,从而使机器能够在不依赖昂贵人工标注的情况下,更好地理解我们不断变化的世界。
众眼胜于一眼
现代陆地观测任务很少只依赖一种成像器。高光谱成像仪测量数十乃至数百个波段,揭示土壤、农作物和人造材料的化学指纹。相比之下,LiDAR 通过发射激光脉冲构建地面的三维图景,捕捉建筑高度、树冠和细微的表面结构。在同一街区内,两类传感器像素级对齐,但编码的信息截然不同。挑战在于将这些像素聚类或分组为地物类型——例如建筑、道路或果园——以一种既利用各传感器优势又能达成共享、一致判定的方法进行。
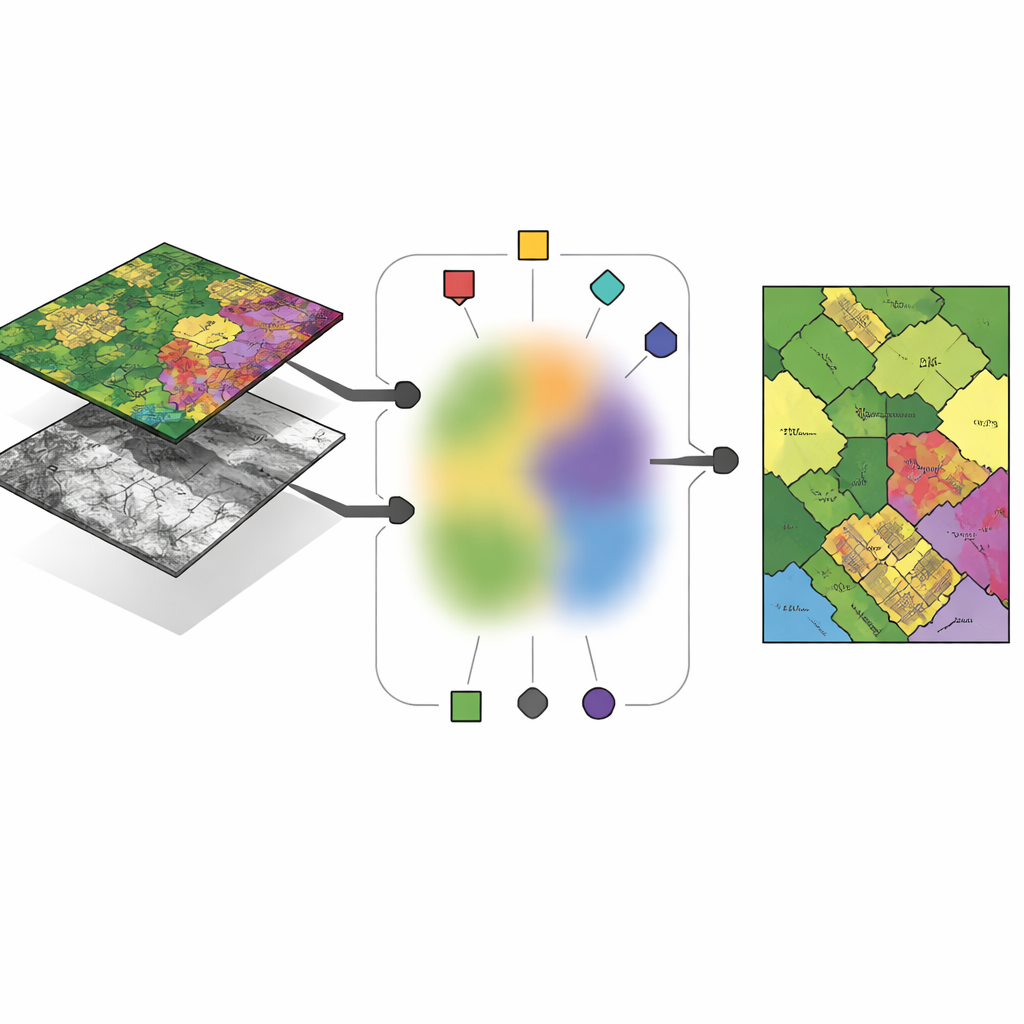
锚点:数据海洋中的代表性点
作者并不让算法在每个传感器中随意创建完全自由的“簇心”。相反,他们提出用一小批精心挑选的像素作为锚点来构建这些簇心。锚点像典型样本,概括每幅图像的主要模式。每个传感器中的簇心被表示为其锚点的加权混合,这迫使簇心贴近真实观测数据,避免出现不稳定或无意义的解。该设计减少了方法需要学习的自由参数,使结果更易解释:簇心变成“位于这几枚具体锚点之间”的组合,而不再是漂浮在高维空间中的抽象点。
在传感器间共享群组隶属度
这一新框架(称为锚点引导的多视角模糊聚类,AMVFC)的关键思想是将“簇的位置”与“每个像素属于簇的强度”分开表述。每个传感器——高光谱与 LiDAR——保留自己的簇心,以适应其独特的观测方式,但所有传感器共享一张模糊隶属度表。该共享表记录每个像素对各地物组的软隶属度,而非硬性的一对一标注。由于两幅图像在空间上对齐,同一像素在两种视图中必须共享这些隶属值,从决策层将传感器联系起来。方法随后交替调整锚点混合与共享隶属度,力求在保持跨传感器一致性的同时,尽可能准确地重建每个传感器的数据。
为非线性模式向更深处延展
为更好地处理数据中的复杂非线性关系,作者将方法扩展为一个深度版本,称为 ADMVFC。在该版本中,共享的卷积自编码器首先将高光谱和 LiDAR 输入压缩到共同的潜在表征中。一个轻量级适配器在编码前将 LiDAR 通道与降维后的高光谱通道对齐,使两种模态可以进入同一网络。在该潜在空间中,应用相同的锚点引导模糊聚类方案:锚点概括特征,簇心为锚点的混合,共享的模糊隶属表将模态联系在一起。训练时同时平衡两项目标——准确重建每个传感器与在潜在空间中为两种视图找到联合聚类。
将方法付诸检验
研究者在三个基准区域上评估了 AMVFC 及其深度对应版本:意大利特伦托附近的农田、密西西比州格尔夫波特的城市场景,以及德州休斯顿的复杂城市与郊区混合区。每个案例中,他们将高光谱图像与配套的 LiDAR 数据结合,并将方法与九种已建立的多模态聚类技术进行比较。深度版本 ADMVFC 在特伦托与格尔夫波特站点上整体表现最佳,取得更高的精度并与人工标注图更一致,同时比许多依赖图计算的竞争方法更快。在更为复杂的休斯顿场景中,较为简单的 AMVFC 略胜于其深度兄弟,这很可能是因为深度网络在背景与标注像素极度不平衡的数据集上表现欠佳。所有测试中,两种版本的计算复杂度均近似随样本数线性增长,使其可在大规模遥感集合中实用。
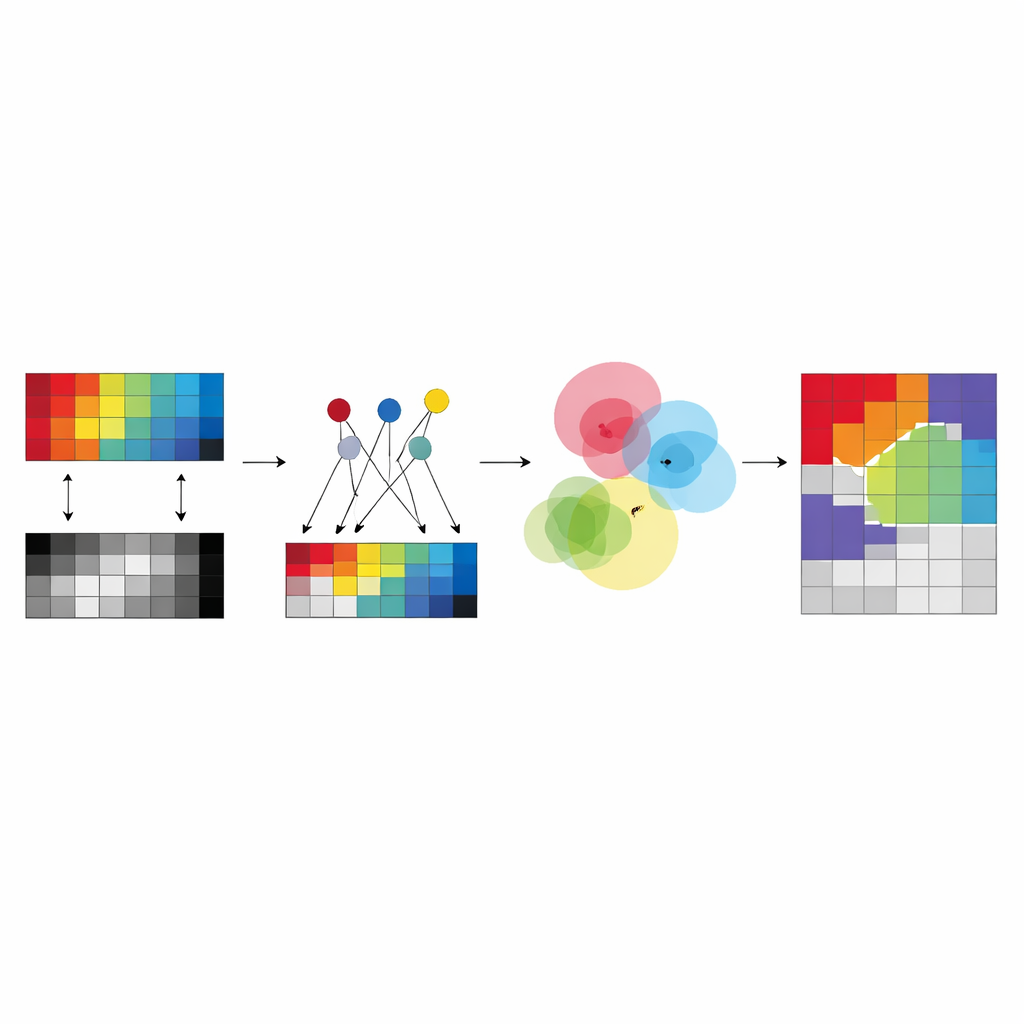
对地球制图的意义
简而言之,这项工作为不同卫星“之眼”在无需人工监督的情况下达成对地物的共同理解提供了路径。通过将簇心锚定于真实锚点像素并强制高光谱与 LiDAR 数据共享模糊群组隶属,所提出的方法比许多现有工具能生成更可靠、可解释的地物图。深度扩展在中等复杂场景中增添了额外能力,而原始的基于锚点模型在数据稀缺或噪声较多时仍保持稳健。两者共同指向更快速、更可扩展且更值得信赖的自动地表制图未来。
引用: Xiao, L., Liu, S. & Liu, Y. Anchor-guided multi-view fuzzy clustering for hyperspectral and LiDAR images. Sci Rep 16, 10175 (2026). https://doi.org/10.1038/s41598-026-40213-2
关键词: 遥感, 多模态成像, 无监督聚类, 高光谱与 LiDAR, 地物制图