Clear Sky Science · es
Agrupación difusa multivista guiada por anclas para imágenes hiperespectrales y LiDAR
Ver la Tierra con más claridad
Desde la salud de los cultivos hasta el crecimiento urbano, los satélites ahora observan nuestro planeta con un detalle notable. Pero diferentes sensores ven el mismo lugar de maneras muy distintas: unos registran los matices de color de la vegetación, otros capturan la forma precisa de edificios y el terreno. Este estudio presenta una nueva forma de agrupar automáticamente áreas terrestres en categorías significativas combinando estas visiones contrastantes, de modo que las máquinas puedan interpretar mejor nuestro mundo cambiante sin depender de etiquetas costosas creadas por humanos.
Por qué muchos ojos son mejores que uno
Las misiones modernas de observación de la Tierra raramente dependen de un solo tipo de sensor. Los captadores hiperespectrales miden docenas o incluso cientos de bandas de color, revelando huellas químicas del suelo, los cultivos y materiales fabricados por el hombre. Los sensores LiDAR, por contraste, emiten pulsos láser para construir una imagen tridimensional del terreno, capturando alturas de edificios, copas de árboles y estructuras superficiales sutiles. Sobre la misma manzana urbana, ambos sensores están alineados píxel a píxel, pero codifican información muy diferente. El reto es agrupar, o clusterizar, esos píxeles en tipos de cobertura del suelo—como edificios, carreteras u huertos—de una forma que aproveche las fortalezas de cada sensor y, al mismo tiempo, alcance una decisión compartida y coherente sobre lo que hay en el terreno. 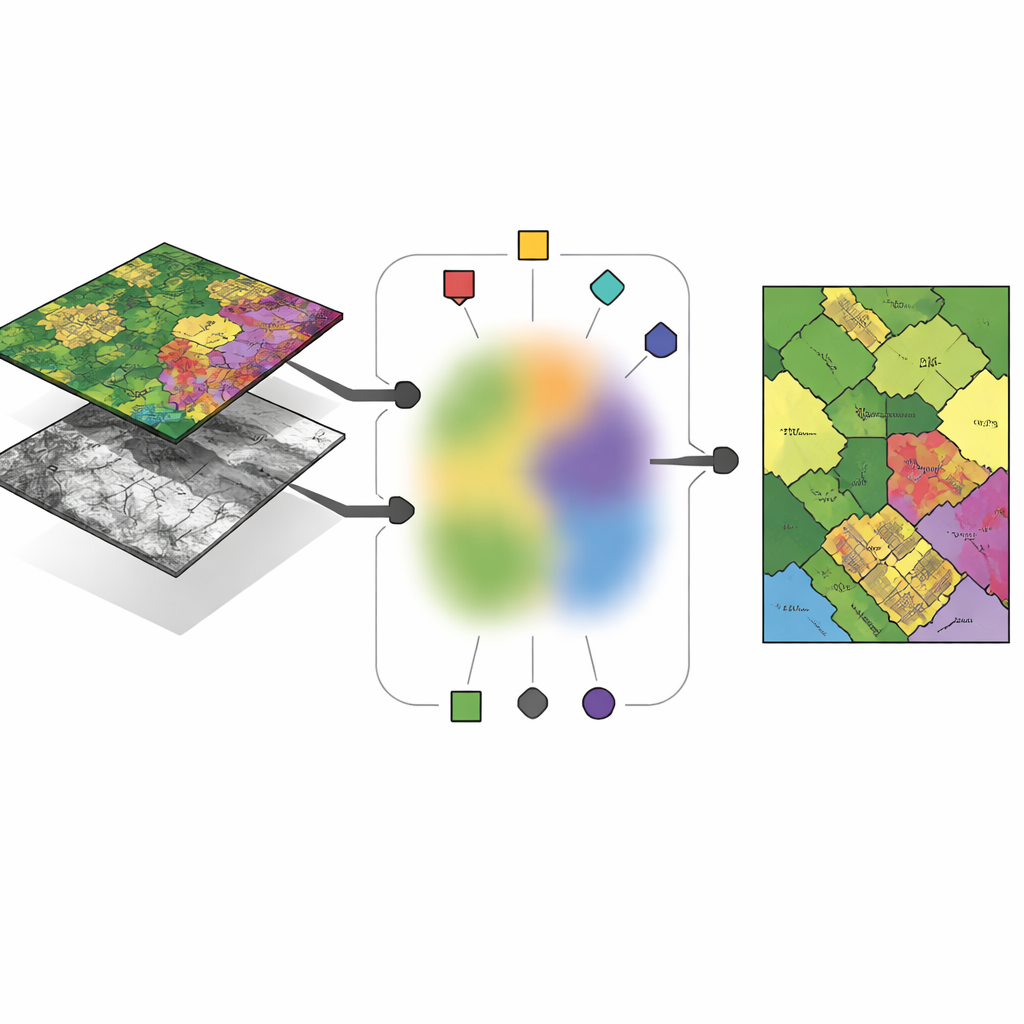
Anclas: puntos representativos en un mar de datos
En lugar de dejar que el algoritmo invente “centros” completamente libres para cada grupo en cada sensor, los autores proponen construir esos centros a partir de un pequeño conjunto de píxeles cuidadosamente seleccionados llamados anclas. Estas anclas actúan como ejemplos típicos que resumen los patrones principales en cada imagen. Cada centro de cluster en un sensor dado se expresa como una mezcla ponderada de sus anclas, lo que obliga a los centros a permanecer cerca de datos reales observados y evita soluciones inestables o sin sentido. Este diseño reduce el número de parámetros libres que el método debe aprender y facilita la interpretación de los resultados: un centro de cluster pasa a ser “algo entre estos pocos píxeles ancla concretos” en lugar de un punto abstracto flotando en un espacio de alta dimensión.
Compartir la pertenencia a grupos entre sensores
La idea clave del nuevo marco, llamado agrupamiento difuso multivista guiado por anclas (AMVFC), es separar “dónde están los clusters” de “con qué fuerza pertenece cada píxel a ellos”. Cada sensor—hiperespectral y LiDAR—mantiene sus propios centros de cluster, adaptados a su manera particular de ver el mundo, pero todos los sensores comparten una única tabla de pertenencias difusas. Esta tabla compartida registra, para cada píxel, grados suaves de pertenencia a cada grupo de cobertura del suelo en lugar de una asignación rígida de sí o no. Dado que las dos imágenes están alineadas espacialmente, el mismo píxel en ambas vistas debe compartir estos valores de pertenencia, uniendo los sensores a nivel de decisión. El método ajusta entonces por turno las mezclas de anclas y las pertenencias compartidas, buscando reconstruir los datos de cada sensor lo más fielmente posible mientras preserva este acuerdo entre sensores.
Profundizando para patrones no lineales
Para manejar mejor relaciones complejas y no lineales en los datos, los autores extienden su enfoque a una versión profunda llamada ADMVFC. Aquí, un autoencoder convolucional compartido primero comprime las entradas hiperespectrales y LiDAR en una representación latente común. Un adaptador ligero alinea los canales LiDAR con los canales hiperespectrales reducidos antes de la codificación, de modo que ambas modalidades alimenten la misma red. En este espacio latente se aplica el mismo esquema de agrupamiento difuso guiado por anclas: las anclas resumen las características, los centros de cluster son mezclas de anclas, y una tabla compartida de pertenencias difusas vincula las modalidades. El entrenamiento equilibra dos objetivos a la vez—reconstruir cada sensor con precisión y encontrar una clusterización conjunta en el espacio latente que encaje con ambas vistas.
Poniendo el método a prueba
Los investigadores evalúan AMVFC y su contraparte profunda en tres áreas de referencia: campos agrícolas cerca de Trento en Italia, escenas urbanas en Gulfport, Mississippi, y una región compleja de ciudad y suburbios en Houston, Texas. En cada caso combinan imágenes hiperespectrales con datos LiDAR coincidentes y comparan sus métodos frente a nueve técnicas multimodales de agrupamiento consolidadas. La versión profunda, ADMVFC, ofrece el mejor rendimiento general en los sitios de Trento y Gulfport, alcanzando mayor precisión y mejor concordancia con mapas etiquetados por humanos, además de ser más rápida que muchos competidores basados en grafos. En la escena más intrincada de Houston, la AMVFC más simple supera ligeramente a su hermana profunda, probablemente porque la red profunda tiene dificultades con el desequilibrio extremo del conjunto de datos entre fondo y píxeles etiquetados. En todas las pruebas, ambas versiones escalan casi de manera lineal con el número de muestras, lo que las hace prácticas para colecciones remotas de gran tamaño. 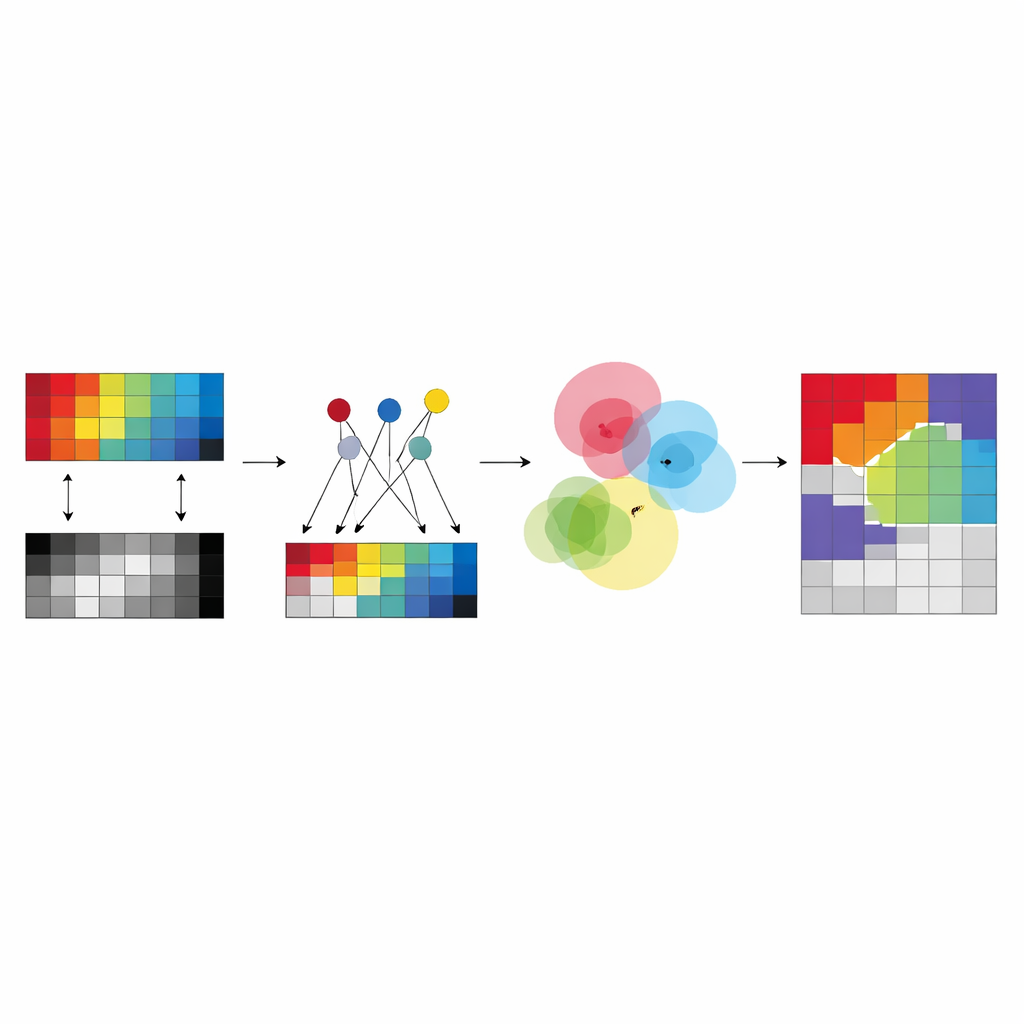
Qué significa esto para cartografiar el planeta
En términos sencillos, este trabajo ofrece una forma para que los distintos “ojos” satelitales lleguen a un entendimiento común de lo que ven en la Tierra, sin requerir supervisión humana. Al anclar los centros de cluster en píxeles reales y obligar a los datos hiperespectrales y LiDAR a compartir asignaciones de grupo difusas, los métodos producen mapas de cobertura del suelo más fiables e interpretables que muchas herramientas existentes. La extensión profunda añade potencia extra en escenas moderadamente complejas, mientras que el modelo original basado en anclas se mantiene robusto cuando los datos son escasos o ruidosos. Juntos, apuntan hacia una cartografía automática de la superficie del planeta más rápida, escalable y confiable.
Cita: Xiao, L., Liu, S. & Liu, Y. Anchor-guided multi-view fuzzy clustering for hyperspectral and LiDAR images. Sci Rep 16, 10175 (2026). https://doi.org/10.1038/s41598-026-40213-2
Palabras clave: teledetección, imágenes multimodales, agrupamiento no supervisado, hiperespectral y LiDAR, cartografía de cobertura del suelo