Clear Sky Science · fr
Regroupement flou multi-vues guidé par ancre pour images hyperspectrales et LiDAR
Voir la Terre plus clairement
Des cultures à la croissance urbaine, les satellites observent désormais notre planète avec un niveau de détail remarquable. Mais différents capteurs perçoivent un même lieu de façons très distinctes : certains enregistrent les nuances de couleur de la végétation, d’autres saisissent la forme exacte des bâtiments et du relief. Cette étude présente une nouvelle manière de regrouper automatiquement les zones terrestres en catégories signifiantes en combinant ces vues contrastées, afin que les machines puissent mieux interpréter notre monde en mutation sans s’appuyer sur des annotations humaines coûteuses.
Pourquoi plusieurs regards valent mieux qu’un
Les missions d’observation de la Terre modernes reposent rarement sur un seul type d’imagerie. Les capteurs hyperspectraux mesurent des dizaines voire des centaines de bandes de couleur, révélant les empreintes chimiques des sols, des cultures et des matériaux artificiels. Les capteurs LiDAR, en revanche, émettent des impulsions laser pour construire une image tridimensionnelle du terrain, capturant la hauteur des bâtiments, les canopées d’arbres et les structures superficielles subtiles. Sur une même parcelle urbaine, les deux capteurs sont alignés pixel par pixel, mais ils codent des informations très différentes. Le défi consiste à regrouper ces pixels en types d’occupation du sol — tels que bâtiments, routes ou vergers — d’une manière qui tire parti des forces de chaque capteur tout en aboutissant à une décision commune et cohérente sur ce qui se trouve au sol. 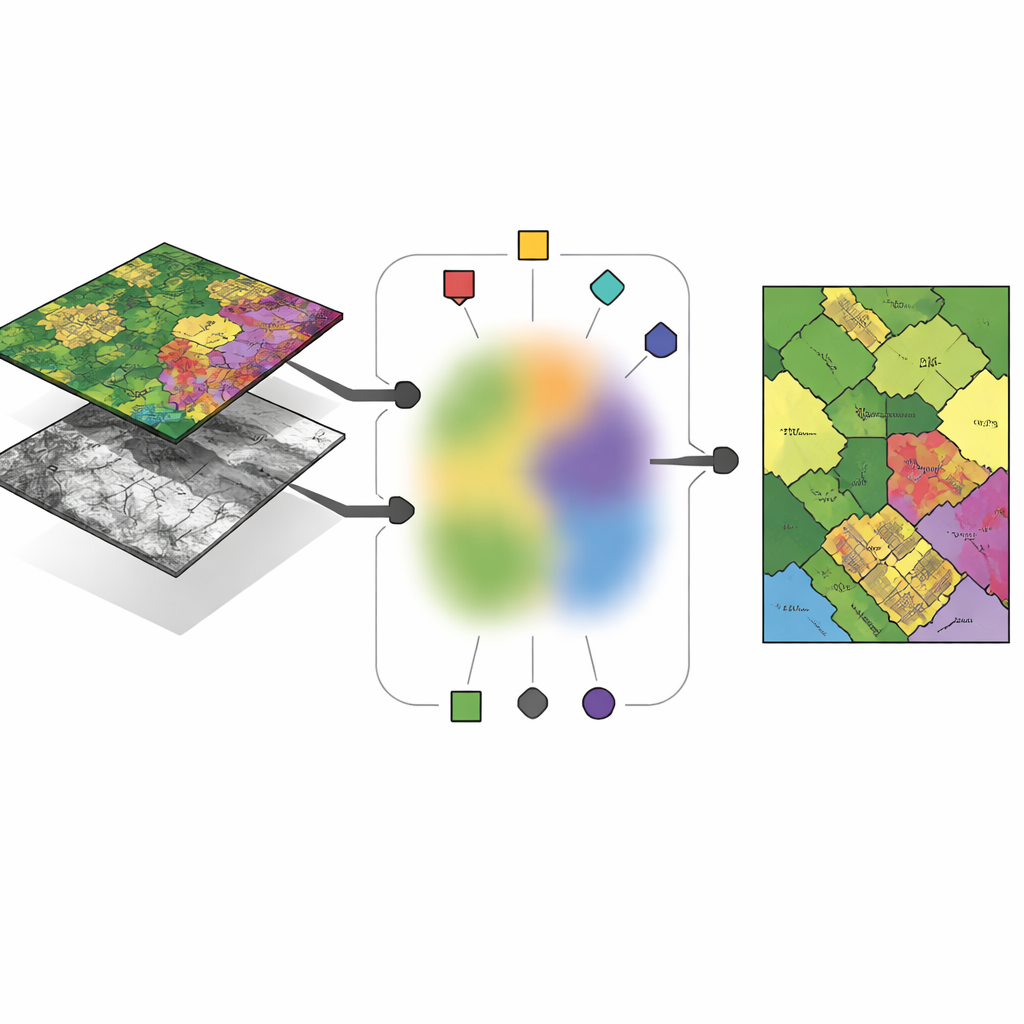
Ancrages : points représentatifs dans un océan de données
Plutôt que de laisser l’algorithme inventer des « centres » totalement libres pour chaque classe et chaque capteur, les auteurs proposent de construire ces centres à partir d’un petit ensemble de pixels soigneusement choisis appelés ancres. Ces ancres jouent le rôle d’exemples typiques qui résument les motifs principaux de chaque image. Chaque centre de cluster dans un capteur donné est exprimé comme un mélange pondéré de ses ancres, ce qui contraint les centres à rester proches de données réelles et observées et évite des solutions instables ou dénuées de sens. Ce choix réduit le nombre de paramètres libres à apprendre et rend les résultats plus faciles à interpréter : un centre de cluster devient « quelque part entre ces quelques pixels ancrés concrets » plutôt qu’un point abstrait flottant dans un espace de grande dimension.
Partager l’appartenance aux groupes entre capteurs
L’idée clé du nouveau cadre, nommé anchor-guided multi-view fuzzy clustering (AMVFC), est de séparer « où se situent les clusters » de « à quel degré chaque pixel leur appartient ». Chaque capteur — hyperspectral et LiDAR — conserve ses propres centres de clusters, adaptés à sa manière particulière de voir le monde, mais tous les capteurs partagent une table unique d’appartenances floues. Cette table partagée enregistre, pour chaque pixel, des degrés d’appartenance souples à chaque groupe d’occupation du sol plutôt qu’une affectation binaire. Étant donné que les deux images sont spatialement alignées, le même pixel dans les deux vues doit partager ces valeurs d’appartenance, liant ainsi les capteurs au niveau de la décision. La méthode ajuste ensuite à tour de rôle les mélanges d’ancres et les appartenances partagées, cherchant à reconstruire au mieux les données de chaque capteur tout en préservant cet accord inter-capteurs.
Approfondir pour capter les motifs non linéaires
Pour mieux gérer les relations complexes et non linéaires dans les données, les auteurs étendent leur approche vers une version profonde appelée ADMVFC. Ici, un autoencodeur convolutionnel partagé compresse d’abord les entrées hyperspectrales et LiDAR en une représentation latente commune. Un adaptateur léger aligne les canaux LiDAR avec les canaux hyperspectraux réduits avant l’encodage, de sorte que les deux modalités alimentent le même réseau. Dans cet espace latent, on applique le même schéma de regroupement flou guidé par ancres : les ancres résument les caractéristiques, les centres de clusters sont des mélanges d’ancres et une table d’appartenances floue partagée relie les modalités. L’entraînement équilibre deux objectifs simultanément — reconstruire fidèlement chaque capteur et trouver un regroupement conjoint dans l’espace latent qui convienne aux deux vues.
Mettre la méthode à l’épreuve
Les chercheurs évaluent AMVFC et sa contrepartie profonde sur trois zones de référence : des parcelles agricoles près de Trente en Italie, des scènes urbaines à Gulfport, Mississippi, et une région urbaine et périurbaine complexe à Houston, Texas. Dans chaque cas, ils combinent des images hyperspectrales avec des données LiDAR correspondantes et comparent leurs méthodes à neuf techniques établies de regroupement multimodal. La version profonde, ADMVFC, offre les meilleures performances globales sur les sites de Trente et Gulfport, atteignant une plus grande précision et une meilleure concordance avec des cartes annotées par des humains tout en restant plus rapide que de nombreux concurrents lourds en graphes. Sur la scène plus complexe de Houston, l’AMVFC plus simple surpasse légèrement son homologue profond, vraisemblablement parce que le réseau profond souffre du déséquilibre extrême du jeu de données entre l’arrière-plan et les pixels annotés. Dans tous les tests, les deux versions évoluent quasiment de façon linéaire avec le nombre d’échantillons, ce qui les rend pratiques pour de grandes collections de télédétection. 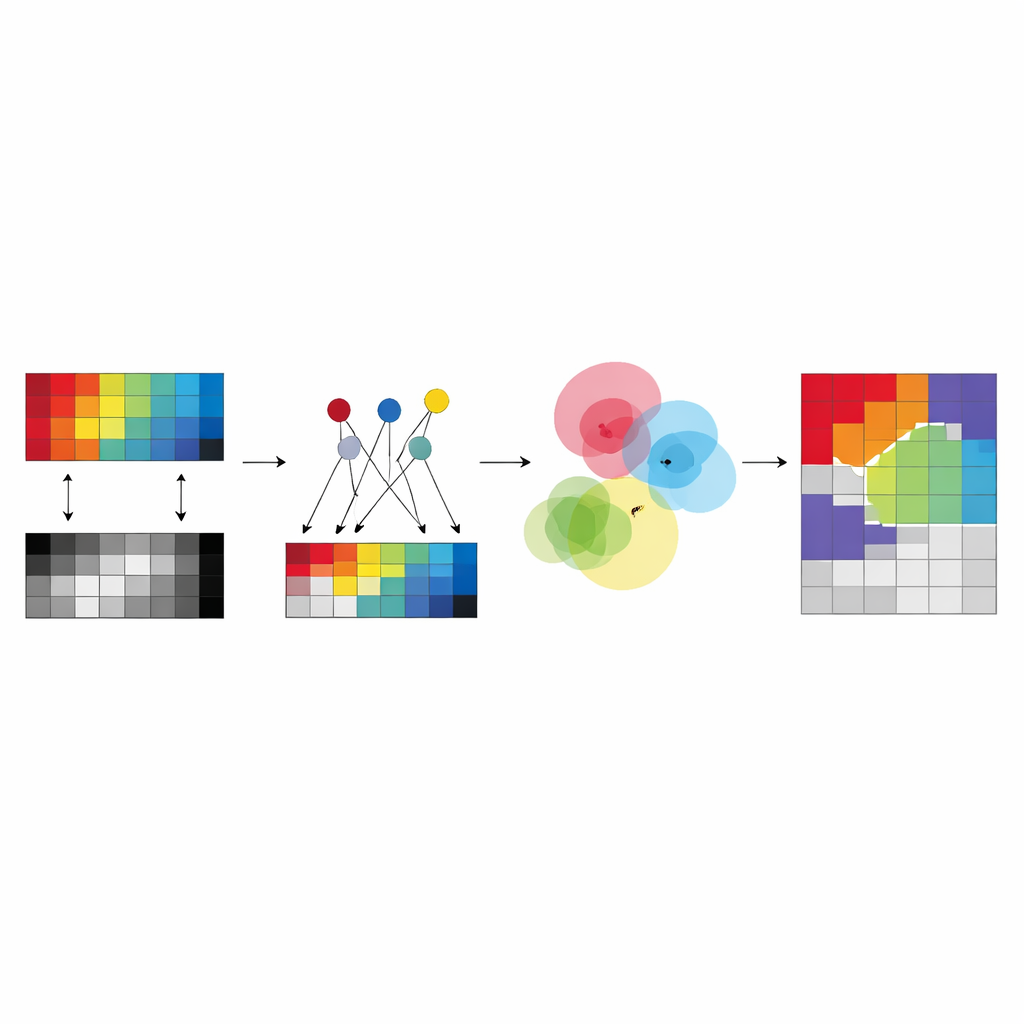
Ce que cela signifie pour la cartographie de la planète
En termes simples, ce travail propose un moyen pour que différents « yeux » satellitaires parviennent à une compréhension commune de ce qu’ils observent sur Terre, sans supervision humaine. En ancrant les centres de clusters dans des pixels réels et en forçant les données hyperspectrales et LiDAR à partager des assignations floues de groupe, les méthodes produisent des cartes d’occupation du sol plus fiables et plus interprétables que de nombreux outils existants. L’extension profonde apporte une puissance supplémentaire sur des scènes modérément complexes, tandis que le modèle initial basé sur les ancres reste robuste lorsque les données sont rares ou bruitées. Ensemble, ils ouvrent la voie à une cartographie automatique de la surface de la planète plus rapide, plus évolutive et plus digne de confiance.
Citation: Xiao, L., Liu, S. & Liu, Y. Anchor-guided multi-view fuzzy clustering for hyperspectral and LiDAR images. Sci Rep 16, 10175 (2026). https://doi.org/10.1038/s41598-026-40213-2
Mots-clés: télédétection, imagerie multimodale, regroupement non supervisé, hyperspectral et LiDAR, cartographie de l’occupation du sol