Clear Sky Science · en
Anchor-guided multi-view fuzzy clustering for hyperspectral and LiDAR images
Seeing the Earth More Clearly
From crop health to city growth, satellites now watch our planet in remarkable detail. But different sensors see the same place in very different ways: some record subtle colors of vegetation, others capture the exact shape of buildings and terrain. This study introduces a new way to automatically group land areas into meaningful categories by combining these contrasting views, so that machines can make better sense of our changing world without relying on expensive human-made labels.
Why Many Eyes Are Better Than One
Modern Earth-observation missions rarely rely on a single type of camera. Hyperspectral imagers measure dozens or even hundreds of color bands, revealing chemical fingerprints of soil, crops and man‑made materials. LiDAR sensors, by contrast, fire laser pulses to build a three‑dimensional picture of the ground, capturing building heights, tree canopies and subtle surface structure. Over the same city block, both sensors are aligned pixel by pixel, but they encode very different information. The challenge is to cluster, or group, these pixels into land-cover types—such as buildings, roads or orchards—in a way that uses the strengths of each sensor yet still reaches a shared, consistent decision about what is on the ground. 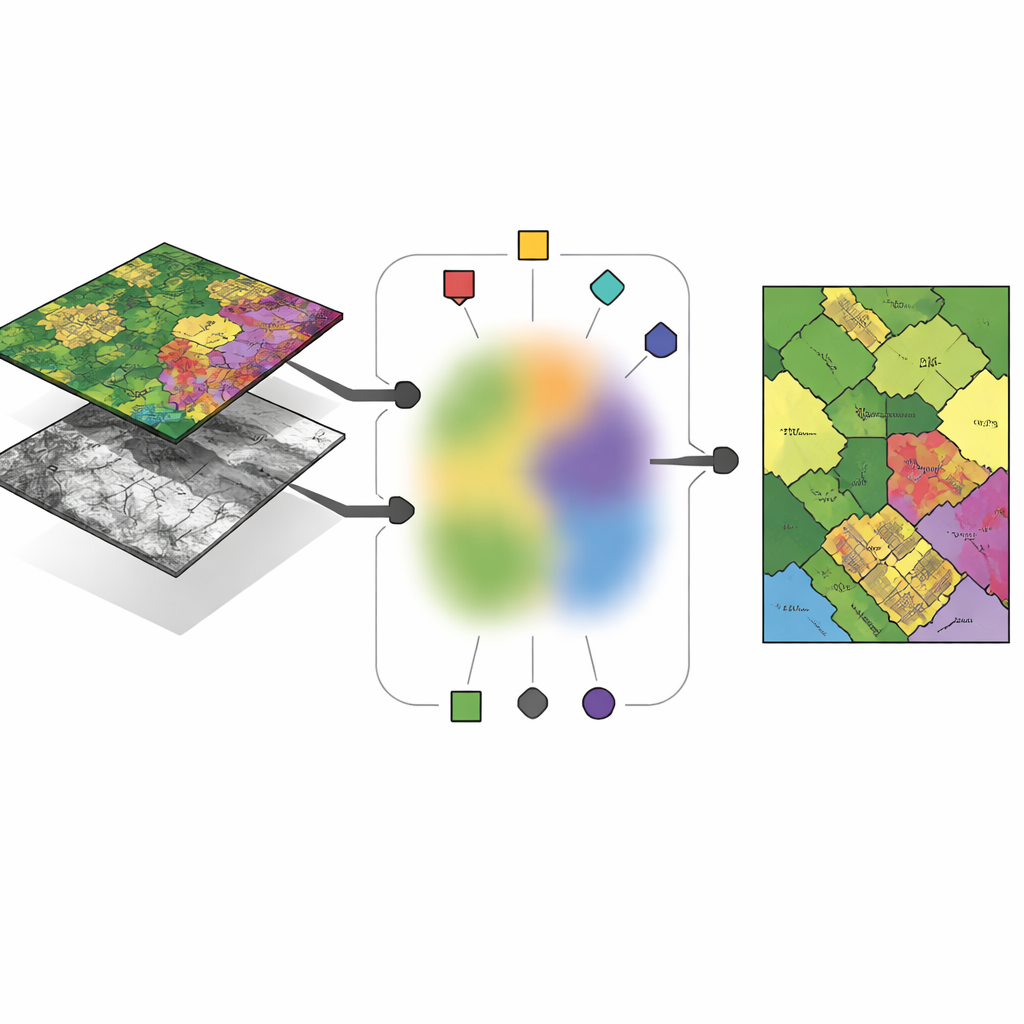
Anchors: Representative Points in a Sea of Data
Instead of letting the algorithm invent completely free “centers” for each cluster in each sensor, the authors propose to build these centers from a small set of carefully chosen pixels called anchors. These anchors act like typical examples that summarize the main patterns in each image. Every cluster center in a given sensor is expressed as a weighted mixture of its anchors, which forces the centers to stay close to real, observed data and avoids unstable or meaningless solutions. This design reduces the number of free parameters the method must learn and makes the results easier to interpret: a cluster center becomes “somewhere between these few concrete anchor pixels” rather than an abstract point floating in a high‑dimensional space.
Sharing Group Membership Across Sensors
The key idea of the new framework, called anchor-guided multi-view fuzzy clustering (AMVFC), is to separate “where the clusters are” from “how strongly each pixel belongs to them.” Each sensor—hyperspectral and LiDAR—keeps its own cluster centers, tailored to its particular way of seeing the world, but all sensors share a single table of fuzzy memberships. This shared table records, for every pixel, soft degrees of belonging to each land-cover group rather than a hard yes‑or‑no assignment. Because the two images are spatially aligned, the same pixel in both views must share these membership values, tying the sensors together at the decision level. The method then adjusts the anchor mixtures and the shared memberships in turn, seeking to reconstruct each sensor’s data as accurately as possible while preserving this cross‑sensor agreement.
Going Deeper for Nonlinear Patterns
To better handle complex, nonlinear relationships in the data, the authors extend their approach into a deep version called ADMVFC. Here, a shared convolutional autoencoder first compresses both hyperspectral and LiDAR inputs into a common latent representation. A lightweight adapter aligns the LiDAR channels with the reduced hyperspectral channels before encoding, so that both modalities feed into the same network. In this latent space, the same anchor-guided fuzzy clustering scheme is applied: anchors summarize the features, cluster centers are mixtures of anchors, and a shared fuzzy membership table ties the modalities together. Training balances two goals at once—reconstructing each sensor accurately and finding a joint clustering in the latent space that fits both views.
Putting the Method to the Test
The researchers evaluate AMVFC and its deep counterpart on three benchmark areas: agricultural fields near Trento in Italy, urban scenes in Gulfport, Mississippi, and a complex city-and-suburb region in Houston, Texas. In each case, they combine hyperspectral images with matching LiDAR data and compare their methods against nine established multimodal clustering techniques. The deep version, ADMVFC, delivers the best overall performance on the Trento and Gulfport sites, achieving higher accuracy and better agreement with human-labeled maps while remaining faster than many graph-heavy competitors. On the more intricate Houston scene, the simpler AMVFC slightly outperforms its deep sibling, likely because the deep network struggles with the dataset’s extreme imbalance between background and labeled pixels. Across all tests, both versions scale nearly linearly with the number of samples, making them practical for large remote-sensing collections. 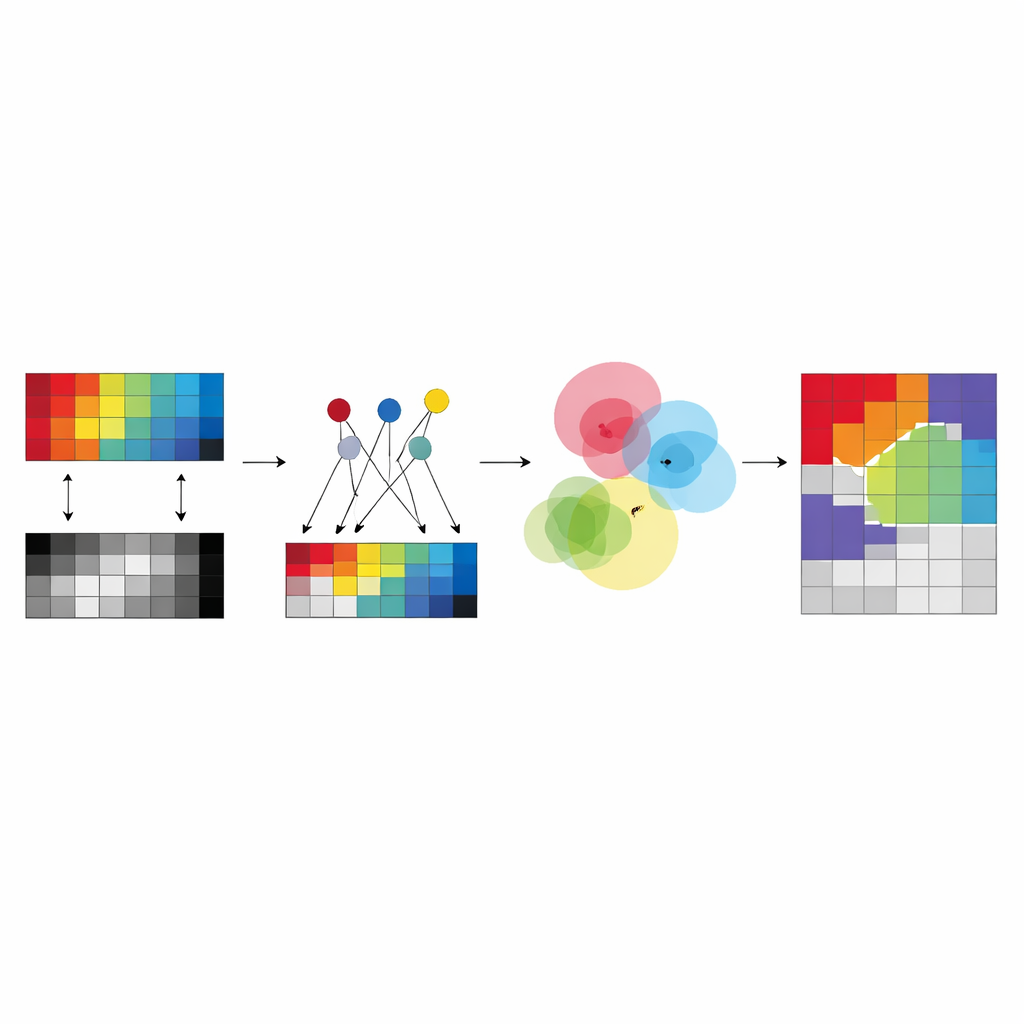
What This Means for Mapping the Planet
In plain terms, this work offers a way for different satellite “eyes” to reach a common understanding of what they see on Earth, without requiring human supervision. By grounding cluster centers in real anchor pixels and forcing hyperspectral and LiDAR data to share fuzzy group assignments, the methods produce more reliable, interpretable land-cover maps than many existing tools. The deep extension adds extra power on moderately complex scenes, while the original anchor-based model remains robust when data are sparse or noisy. Together, they point toward faster, more scalable and more trustworthy automatic mapping of our planet’s surface.
Citation: Xiao, L., Liu, S. & Liu, Y. Anchor-guided multi-view fuzzy clustering for hyperspectral and LiDAR images. Sci Rep 16, 10175 (2026). https://doi.org/10.1038/s41598-026-40213-2
Keywords: remote sensing, multimodal imaging, unsupervised clustering, hyperspectral and LiDAR, land cover mapping