Clear Sky Science · sv
Förtätad ankarguidad flervy-fuzzy-klustring för hyperspektrala och LiDAR-bilder
Se jorden tydligare
Från grödors hälsa till stadsutbredning bevakar satelliter nu vår planet i anmärkningsvärd detalj. Men olika sensorer ser samma plats på mycket olika sätt: vissa registrerar vegetationens subtila färger, andra fångar byggnaders och terrängs exakta form. Denna studie introducerar ett nytt sätt att automatiskt gruppera markområden i meningsfulla kategorier genom att kombinera dessa kontrasterande vyer, så att maskiner bättre kan tolka vår föränderliga värld utan att förlita sig på dyra människomärkta etiketter.
Därför är många ögon bättre än ett
Moderna jordobservationsuppdrag förlitar sig sällan på en enda typ av kamera. Hyperspektrala sensorer mäter tiotals eller till och med hundratals färgband och avslöjar kemiska fingeravtryck hos jord, grödor och konstgjorda material. LiDAR-sensorer skickar laserpulsar för att bygga en tredimensionell bild av marken och fångar byggnaders höjder, trädtoppar och subtil ytstruktur. Över samma stadsblock är båda sensorerna pixelmappade, men de kodar mycket olika information. Utmaningen är att klustra, alltså gruppera, dessa pixlar i marktäcktstyper—som byggnader, vägar eller fruktodlingar—på ett sätt som använder varje sensors styrkor men ändå når en gemensam, konsekvent slutsats om vad som finns på marken. 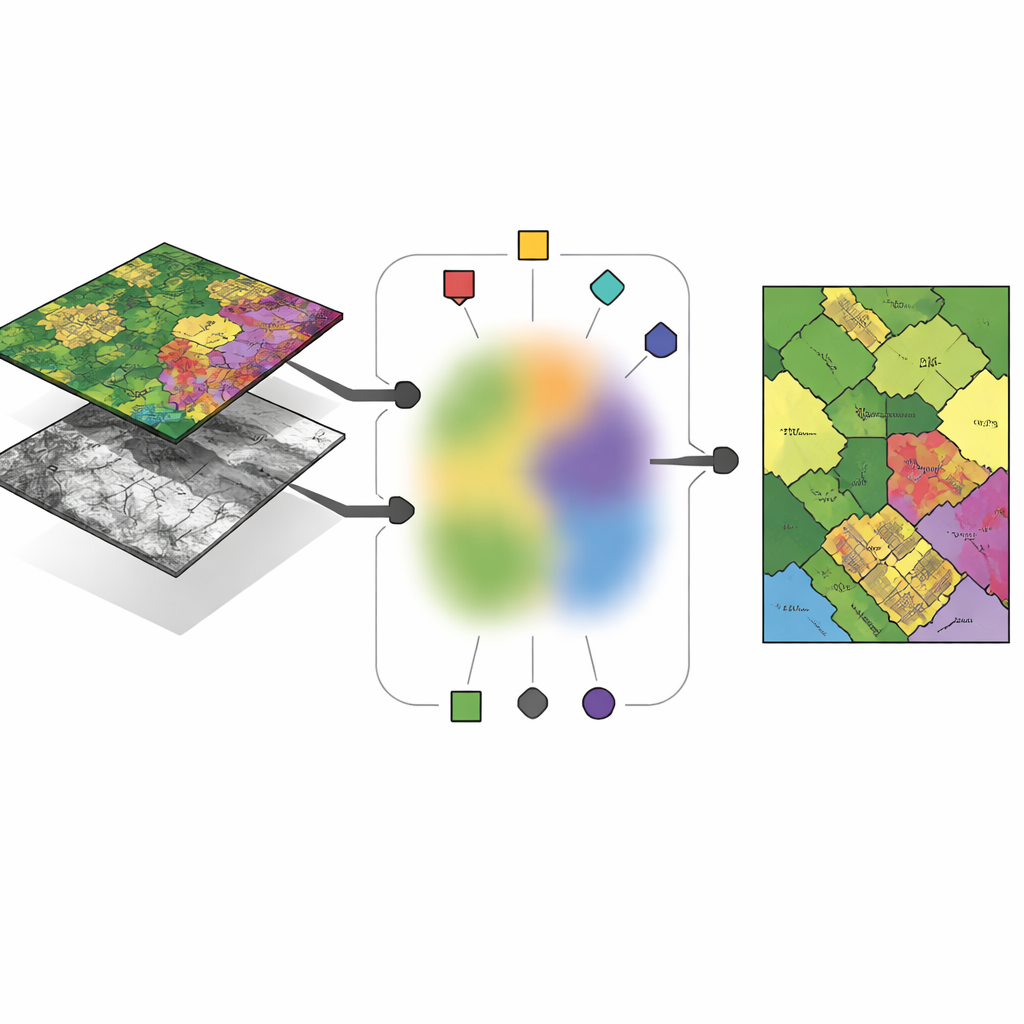
Ankare: representativa punkter i ett hav av data
I stället för att låta algoritmen hitta helt fria ”centra” för varje kluster i varje sensor föreslår författarna att bygga dessa centrum ur en liten mängd noggrant utvalda pixlar kallade ankare. Dessa ankare fungerar som typiska exempel som sammanfattar huvudmönstren i varje bild. Varje klustercentrum i en given sensor uttrycks som en viktad blandning av dess ankare, vilket tvingar centren att ligga nära verkliga, observerade data och undviker instabila eller meningslösa lösningar. Denna design minskar antalet fria parametrar som metoden måste lära och gör resultaten lättare att tolka: ett klustercentrum blir ”någonstans mellan dessa få konkreta anchor-pixlar” snarare än en abstrakt punkt som flyter i ett högdimensionellt rum.
Dela grupptillhörighet över sensorer
Den centrala idén i den nya ramen, kallad anchor-guided multi-view fuzzy clustering (AMVFC), är att separera ”var klustren är” från ”hur starkt varje pixel tillhör dem”. Varje sensor—hyperspektral och LiDAR—behåller sina egna klustercentra, anpassade till sitt särskilda sätt att se världen, men alla sensorer delar en enda tabell med fuzzy-tillhörigheter. Denna delade tabell registrerar, för varje pixel, mjuka grader av tillhörighet till varje marktäckesgrupp i stället för en hård ja-eller-nej-assignering. Eftersom de två bilderna är rumsligt justerade måste samma pixel i båda vyerna dela dessa tillhörighetsvärden, vilket binder ihop sensorerna på beslutsnivå. Metoden justerar därefter anchor-blandningarna och de delade tillhörigheterna växelvis, i syfte att rekonstruera varje sensors data så noggrant som möjligt samtidigt som denna tvärsensoröverenskommelse bevaras.
Gå djupare för icke-linjära mönster
För att bättre hantera komplexa, icke-linjära relationer i data utvidgar författarna sitt tillvägagångssätt till en djup version kallad ADMVFC. Här komprimerar en delad konvolutionell autoenkod först både hyperspektrala och LiDAR-insatser till en gemensam latent representation. En lättviktig adapter anpassar LiDAR-kanalerna till de reducerade hyperspektrala kanalerna före kodning, så att båda modaliteterna matas in i samma nätverk. I detta latenta rum tillämpas samma ankarguidad fuzzy-klustringsschema: ankare sammanfattar funktionerna, klustercentra är blandningar av ankare och en delad fuzzy-tillhörighetstabell knyter modaliteterna samman. Träningen väger två mål samtidigt—att rekonstruera varje sensors data noggrant och att hitta en gemensam klustring i det latenta rummet som passar båda vyerna.
Sätta metoden på prov
Forskarna utvärderar AMVFC och dess djupa motsvarighet på tre referensområden: jordbruksfält nära Trento i Italien, urbana scener i Gulfport, Mississippi, och en komplex stads- och förortsregion i Houston, Texas. I varje fall kombinerar de hyperspektrala bilder med matchande LiDAR-data och jämför sina metoder mot nio etablerade multimodala klustringstekniker. Den djupa versionen, ADMVFC, levererar bäst total prestanda på Trento- och Gulfport-platserna, med högre noggrannhet och bättre överensstämmelse med människomärkta kartor samtidigt som den är snabbare än många grafintensiva konkurrenter. På den mer invecklade scenen i Houston presterar den enklare AMVFC något bättre än sin djupa motsvarighet, troligen därför att det djupa nätverket har svårt med datasetets extrema obalans mellan bakgrunds- och märkta pixlar. I samtliga tester skalar båda versionerna nästan linjärt med antalet prover, vilket gör dem praktiska för stora fjärranalysdatamängder. 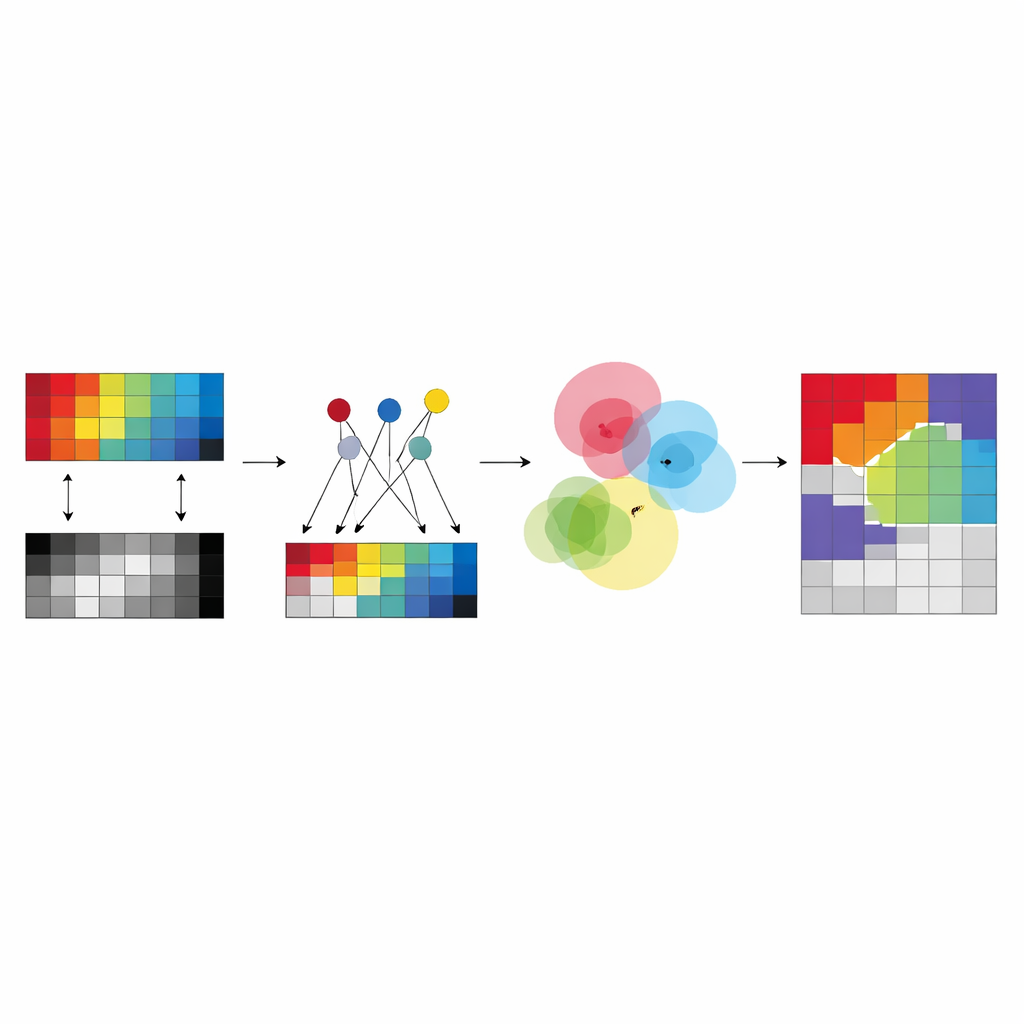
Vad detta betyder för kartläggning av planeten
Enkelt uttryckt erbjuder detta arbete ett sätt för olika satellit"ögon" att nå en gemensam förståelse av vad de ser på jorden, utan krav på mänsklig övervakning. Genom att förankra klustercentra i verkliga anchor-pixlar och tvinga hyperspektral och LiDAR-data att dela fuzzy-gruppbestämningar ger metoderna mer tillförlitliga, tolkbara marktäckeskartor än många befintliga verktyg. Den djupa förlängningen tillför extra kraft i måttligt komplexa scener, medan den ursprungliga anchor-baserade modellen förblir robust när data är glesa eller brusiga. Tillsammans pekar de mot snabbare, mer skalbar och mer pålitlig automatisk kartläggning av jordens yta.
Citering: Xiao, L., Liu, S. & Liu, Y. Anchor-guided multi-view fuzzy clustering for hyperspectral and LiDAR images. Sci Rep 16, 10175 (2026). https://doi.org/10.1038/s41598-026-40213-2
Nyckelord: fjärranalys, multimodal avbildning, oinformerad klustring, hyperspektral och LiDAR, markanvändningskartering