Clear Sky Science · ar
التجميع الضبابي متعدد المناظير الموجه بالمرساة لصور طيفية عالية الأبعاد وصور ليزرية (LiDAR)
رؤية الأرض بوضوح أكبر
من صحة المحاصيل إلى نمو المدن، تراقب الأقمار الصناعية كوكبنا الآن بتفصيل ملحوظ. لكن أجهزة الاستشعار المختلفة ترى المكان نفسه بطرق متباينة للغاية: بعضها يسجل الألوان الدقيقة للغطاء النباتي، بينما يقوم آخر بتصوير الشكل الدقيق للمباني والتضاريس. تُقدّم هذه الدراسة طريقة جديدة لتجميع المناطق الأرضية تلقائياً إلى فئات ذات معنى عن طريق دمج هذه الرؤى المتباينة، بحيث يمكن للآلات أن تفهم عالمنا المتغير بشكل أفضل دون الاعتماد على تسميات بشرية مكلفة.
لماذا تعدد العيون أفضل من عين واحدة
نادراً ما تعتمد مهمات رصد الأرض الحديثة على نوع واحد من الكاميرات. تقيس أجهزة التصوير الطيفي العالي الأبعاد عشرات أو حتى مئات النطاقات اللونية، كاشفةً بصمات كيميائية للتربة والمحاصيل والمواد الصناعية. أجهزة LiDAR، بالمقابل، تطلق نبضات ليزر لبناء صورة ثلاثية الأبعاد عن الأرض، تلتقط ارتفاعات المباني، وسقوف الأشجار وبنية السطح الدقيقة. على نفس قطعة الأرض، تتطابق الصور بكسلًا ببكسل، لكنها تشفر معلومات مختلفة جداً. التحدي هو تجميع هذه البكسلات إلى أنواع غطاء أرضي—كالمباني والطرق والبساتين—بطريقة تستفيد من نقاط القوة في كل جهاز حسّي مع الوصول في الوقت نفسه إلى قرار مشترك ومتسق حول ما يوجد على الأرض. 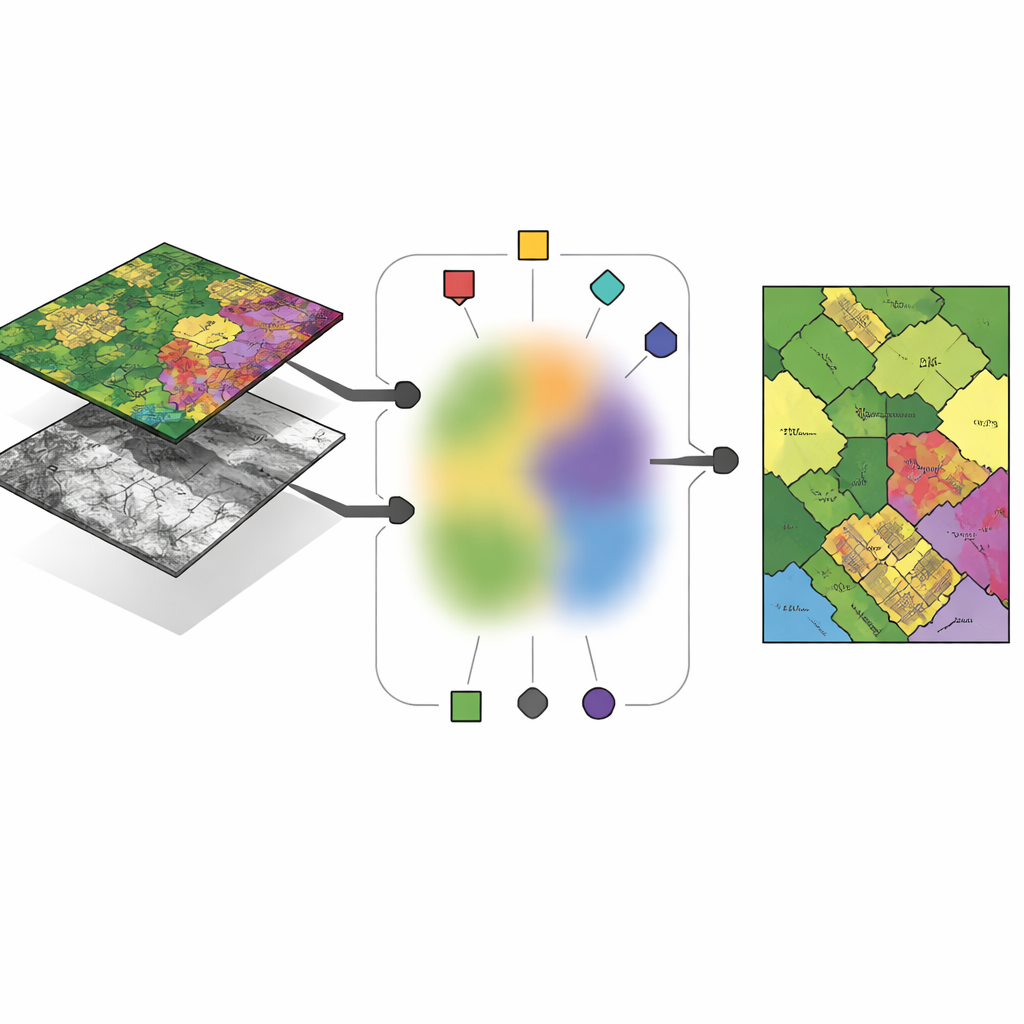
المرساة: نقاط ممثلة في بحر من البيانات
بدلاً من ترك الخوارزمية تبتكر مراكز «حُرّة» تماماً لكل مجموعة في كل جهاز، يقترح المؤلفون بناء هذه المراكز من مجموعة صغيرة من البكسلات المختارة بعناية تُسمى المراسي. تعمل هذه المراسي كنماذج نموذجية تلخّص الأنماط الرئيسة في كل صورة. يُعبّر عن كل مركز عنقود في جهاز معيّن كمزيج موزون من مراسيه، ما يجبر المراكز على البقاء قريبة من بيانات ملاحَظة حقيقية ويتجنّب حلولاً غير مستقرة أو بلا معنى. يقلّل هذا التصميم من عدد المعاملات الحرة التي يجب على الطريقة تعلمها ويجعل النتائج أسهل في التفسير: يصبح مركز العُنقود «فيما بين هذه البكسلات المرساة الملموسة» بدلاً من أن يكون نقطة مجردة تطفو في فضاء عالِ البُعد.
مشاركة عضوية المجموعة عبر الحساسات
الفكرة الأساسية للإطار الجديد، المسمّى التجميع الضبابي متعدد المناظير الموجه بالمرساة (AMVFC)، هي فصل «مكان وجود المجموعات» عن «مدى انتماء كل بكسل لها». يحافظ كل جهاز—الطيفي العالي الأبعاد وLiDAR—على مراكزه الخاصة بالعناقيد، مصمّمة حسب طريقته الخاصة في رؤية العالم، لكن جميع الحساسات تشترك في جدول واحد للانتماءات الضبابية. يسجّل هذا الجدول المشترك، لكل بكسل، درجات ناعمة للانتماء لكل مجموعة غطاء أرضي بدلاً من تعيين نعم/لا صارم. وبما أن الصورتين مصطفّتين مكانياً، يجب أن يشارك نفس البكسل في كلتا الرؤيتين هذه القيم العضوية، رابطاً الحساسات على مستوى القرار. ثم تضبط الطريقة خلطات المراسي والانتماءات الضبابية المشتركة بالتناوب، ساعيةً لإعادة بناء بيانات كل حساس بدقة قدر الإمكان مع الحفاظ على هذا الاتفاق عبر الحساسات.
التعمق لأنماط غير خطية
للتعامل بشكل أفضل مع العلاقات المعقدة وغير الخطية في البيانات، يوسّع المؤلفون نهجهم إلى نسخة عميقة تسمى ADMVFC. هنا، يقوم مُشفّر تلقائي تلافيفي مشترك أولاً بضغط مدخلات الطيفي العالي الأبعاد وLiDAR إلى تمثيل كامِن موحَّد. يطابق مُكيّف خفيف قنوات LiDAR مع قنوات الطيفي المخفَّضة قبل الترميز، بحيث يتغذى كلا النمطين على نفس الشبكة. في هذا الفضاء الكامن، يتم تطبيق نفس مخطط التجميع الضبابي الموجه بالمرساة: تُلخّص المراسي السمات، مراكز العناقيد هي مزيجات من المراسي، ويُربط جدول انتماءات ضبابي مشترك بين النمطين. يوازن التدريب بين هدفين في آن واحد—إعادة بناء بيانات كل حساس بدقة وإيجاد تجميع مشترك في الفضاء الكامن يتناسب مع كلا المنظورين.
اختبار الطريقة
قيّم الباحثون AMVFC ونظيره العميق على ثلاث مناطق معيارية: حقول زراعية قرب ترينتو في إيطاليا، مشاهد حضرية في غولفبورت بولاية مسيسيبي، ومنطقة حضرية وضواحي معقدة في هيوستن، تكساس. في كل حالة، جمعوا صوراً طيفية عالية الأبعاد مع بيانات LiDAR المطابقة وقارنوا طرقهم بتسع تقنيات تجميع متعددة الوسائط معروفة. قدّمت النسخة العميقة، ADMVFC، أفضل أداء عام في موقعي ترينتو وغولفبورت، محققةً دقة أعلى واتفاقاً أفضل مع الخرائط الموسومة يدوياً بينما ظلت أسرع من العديد من المنافسين المعتمدين على الرسوم البيانية. في مشهد هيوستن الأكثر تعقيداً، تفوّق AMVFC الأبسط قليلاً على شقيقه العميق، ربما لأن الشبكة العميقة واجهت صعوبة مع عدم التوازن الشديد في مجموعة البيانات بين الخلفية والبكسلات الموسومة. عبر كل الاختبارات، تتدرج كلتا النسختين تقريباً خطياً مع عدد العينات، مما يجعلهما عمليين لمجموعات بيانات استشعار عن بعد كبيرة. 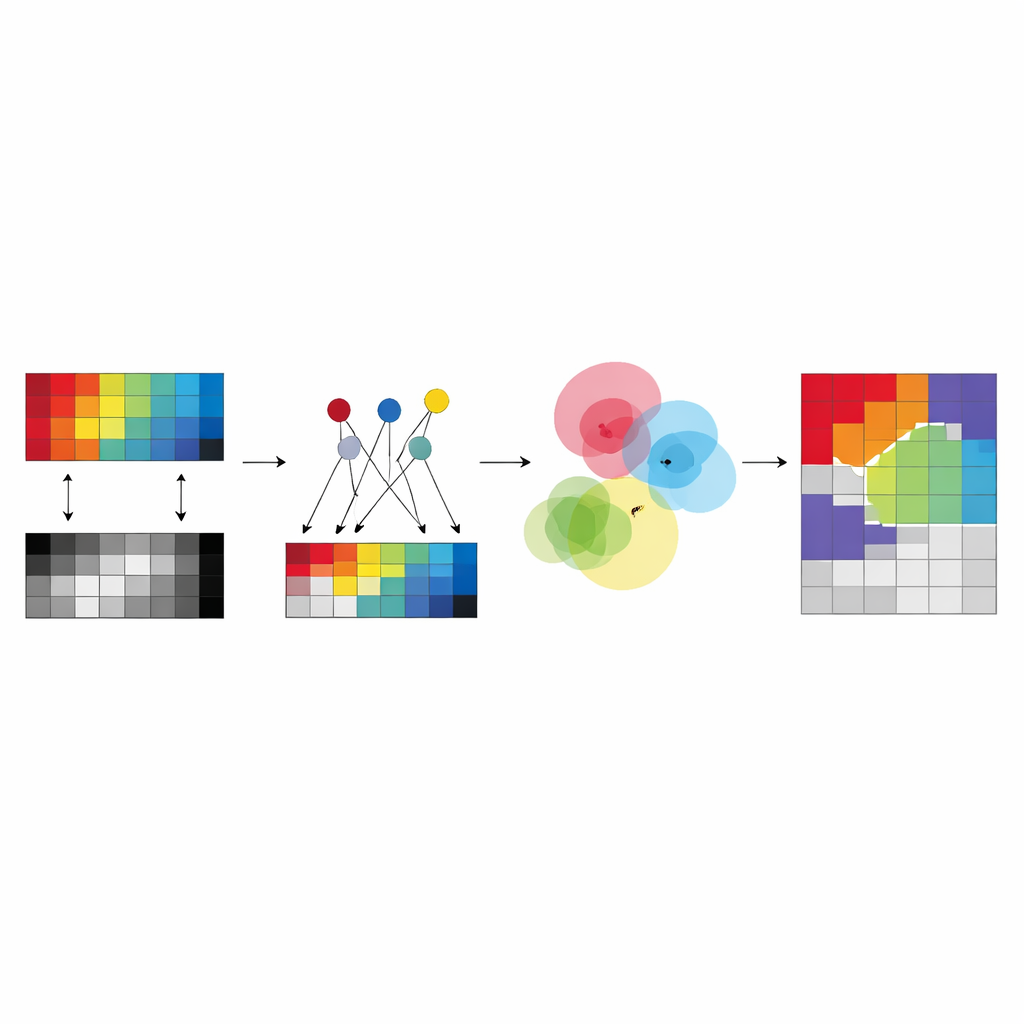
ما الذي يعنيه هذا لخرائط الكوكب
بعبارة بسيطة، تقدّم هذه الورقة طريقة لأن «تتفق» عيون الأقمار الصناعية المختلفة على فهم مشترك لما ترى على الأرض، دون الحاجة لإشراف بشري. من خلال إرساء مراكز العناقيد في بكسلات مرساة حقيقية وإجبار بيانات الطيفي العالي الأبعاد وLiDAR على مشاركة تعيينات ضبابية للمجموعات، تنتج الطرق خرائط غطاء أرضي أكثر موثوقية وقابلة للتفسير من العديد من الأدوات الحالية. تضيف النسخة العميقة قدرة إضافية على المشاهد ذات التعقيد المتوسط، بينما يظل النموذج الأصلي المعتمد على المراسي متيناً عندما تكون البيانات نادرة أو ضوضائية. معاً، تشير هذه الطرق إلى اتجاه نحو استخراج خرائط سريعة وأكثر قابلية للتوسع وأكثر ثقة لسطح كوكبنا.
الاستشهاد: Xiao, L., Liu, S. & Liu, Y. Anchor-guided multi-view fuzzy clustering for hyperspectral and LiDAR images. Sci Rep 16, 10175 (2026). https://doi.org/10.1038/s41598-026-40213-2
الكلمات المفتاحية: الاستشعار عن بعد, التصوير متعدد الوسائط, التجميع غير المراقب, طيفي عالي الأبعاد وLiDAR, خرائط غطاء الأرض