Clear Sky Science · zh
用于遥感的低数据跨模态自适应:基于代理增强多粒度特征缓存
教会卫星在更少数据下理解地球
卫星影像是追踪城市扩张、监测作物和应对灾害的宝贵资源——但将这些图像变成可靠地图通常需要成千上万的人工标注。本文提出了一种新方法,使强大的图像—语言 AI 模型在标注样本稀缺时也能应用于卫星数据,从而在无需大规模注释的情况下解锁及时且细致的地球观测能力。
常规 AI 为什么难以处理太空视角影像
大多数现代视觉—语言系统(如 CLIP)在配有短文本的日常照片上训练。它们对猫、汽车和街道很熟悉,但对从数百公里高空看到的跑道、稻田或工业园区知之甚少。遥感影像在尺度、视角和光谱波段上与普通照片不同,而且这类影像的标签昂贵,需要专家知识。当只有少量示例可用时,标准微调方法往往过拟合或难以收敛,使得这些大模型在地理空间应用中未能充分发挥作用。
用丰富语言扩展简略标签
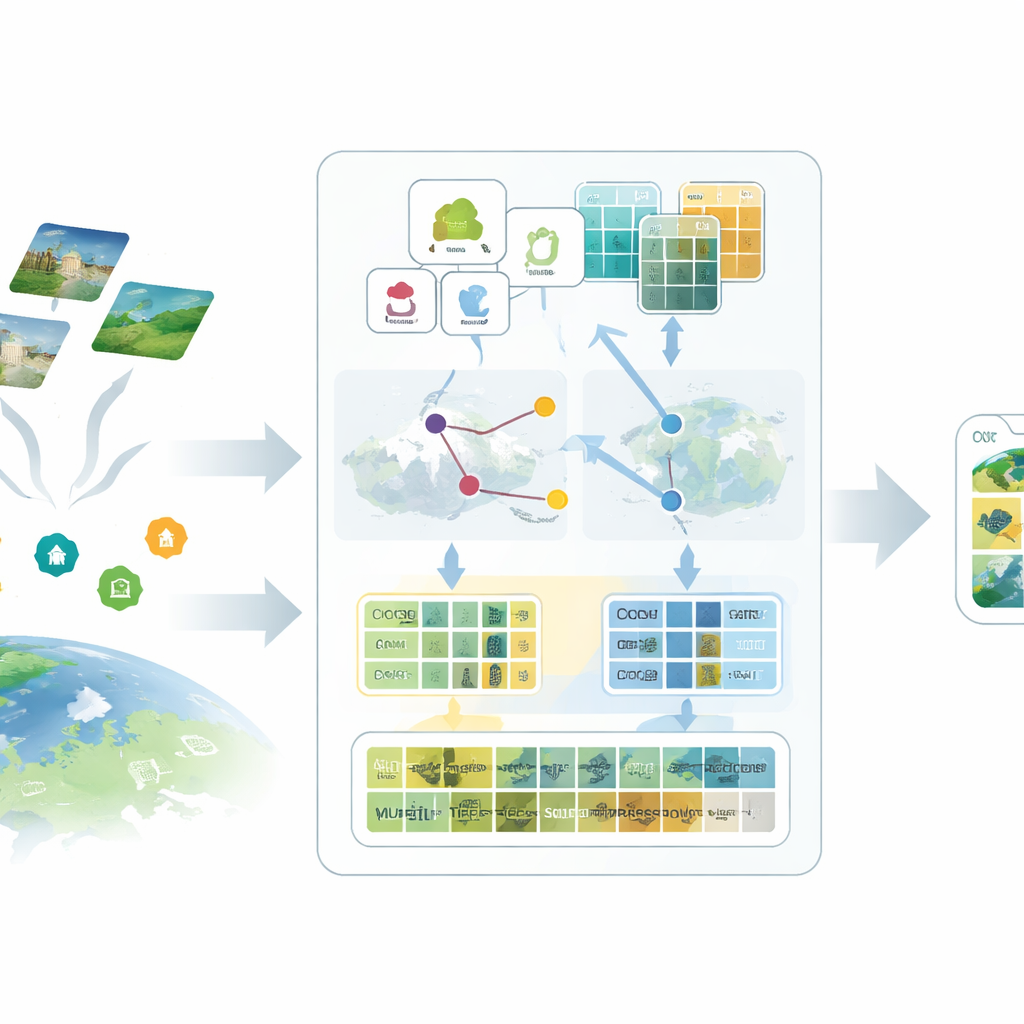
SatAdapter 框架的第一个思路是以更适合卫星影像的“语言”与模型对话。作者不是输入“机场”或“森林”等简短类别名,而是使用大型语言模型生成关于每个类别从上方看起来如何的详细描述——包括纹理、形状、模式和空间布局。若干精心设计的问题提示引导语言模型描述例如跑道的对齐方式、建筑如何聚集、田块如何排列等。这些更丰富的描述被转换为文本特征,为视觉—语言模型提供了更清晰的心理图景,使其更能识别卫星影像中的各类地物。
代理:替代缺失标签的代表向量
第二个要素是用经过校准的“代理”代替缺失标签。SatAdapter 从冻结的 CLIP 图像编码器出发,计算未标注卫星影像与基于语言的类别描述之间的关联。从中构建按类别的参考向量,作为共享图像—文本空间内的软性、可学习分类器。这些代理通过高效的离线优化得到精炼,且永远不改变主干模型。为了增强可靠性,该方法融合了两种互补编码器的预测——卷积网络和视觉变换器——使得细节纹理和宏观布局都有贡献。结果是一组可信的伪标签,近似人工注释但不需人工工作。
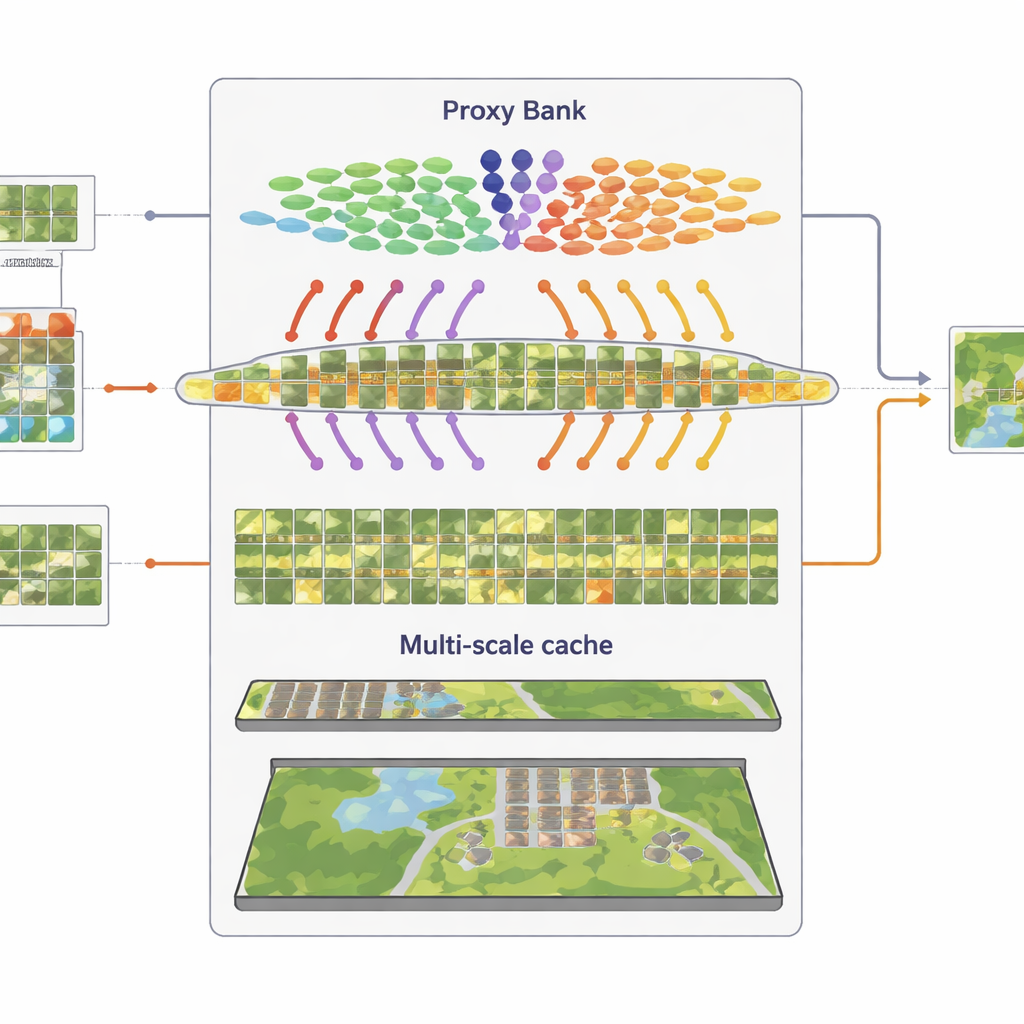
在多尺度上记忆视觉模式
第三个组件是一个多粒度的“特征缓存”,用于记忆代表性视觉模式。SatAdapter 从那些被赋予高置信度伪标签的图像中,存储补丁级细节和整景摘要,作为键-值对。在推理时,当新图像到来,系统测量其与该缓存以及基于代理的预测的相似度,并将它们与原始零样本 CLIP 输出相结合。这个由少数权重参数控制的简单检索与融合过程,使模型能够重用先前卫星场景中积累的关于纹理、形状和布局的知识——无需任何基于梯度的训练。
在多样地景上验证该方法
为测试 SatAdapter,作者在五个标准卫星基准上进行了评估,这些基准涵盖欧洲农田、全球城市、美国郊区以及复杂的中国城市场景,每个数据集具有不同分辨率和地物类别。在零样本条件下——仅知道类别名称——SatAdapter 超过了多个领先的跨模态基线,使平均 top-1 精度提高近五个百分点。在少样本设置下(每类仅有 1 到 16 张标注图像),它也优于那些依赖标注支持图像的基于缓存的竞争方法。消融研究表明,三大模块各自都有贡献,但它们的组合——丰富提示、代理校准和多尺度缓存——在不同主干和数据集上带来了最大且最稳定的提升。
这对监测我们变化中的世界意味着什么
对非专业读者而言,关键结论是 SatAdapter 展示了如何在不依赖大量标注数据的情况下,将通用的图像—语言 AI 适配到卫星影像。通过用描述性语言丰富简单的类别名、从未标注场景构建代理分类器,以及通过特征缓存循环利用视觉模式,该框架将一个在网络上训练的通用模型转变为一个强大且低数据需求的遥感工具。这让在专家仅能标注极少数从太空传回图像时,也能大规模监测土地利用、基础设施和环境变化变得更可行。
引用: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
关键词: 遥感, 视觉-语言模型, 少样本学习, 卫星影像, 地理空间人工智能