Clear Sky Science · tr
Az verilerle çapraz-modal uyarlama: vekil destekli çok-dereceli özellik önbellekleme ile uzaktan algılama
Uydulara Dünyayı Daha Az Veriyle Anlatmayı Öğretmek
Uydu görüntüleri, kentsel büyümeyi izlemek, tarımı takip etmek ve felaketlere müdahale etmek için değerli bilgiler içerir—ancak bu görüntüleri güvenilir haritalara dönüştürmek genellikle binlerce zahmetli insan etiketine ihtiyaç duyar. Bu makale, etiketlenmiş örneklerin kısıtlı olduğu durumlarda güçlü görsel–dil yapay zekâ modellerini uydu verileri için işe yarar hâle getirmenin yeni bir yolunu sunuyor; böylece devasa anotasyon çalışmaları olmadan gezegenimizin zamanlı ve ayrıntılı görünümlerini açığa çıkarmayı kolaylaştırıyor.
Neden Standart Yapay Zekâ Uzaydan Çekilen Görüntülerle Zorlanır?
CLIP gibi çoğu modern görsel–dil sistemi, web’den alınmış günlük fotoğraflar ve kısa metinlerle eğitilir. Bu modeller kediler, arabalar ve şehir sokakları hakkında çok şey bilir, ancak yüzlerce kilometre yükseklikten görülen pistler, pirinç tarlaları veya sanayi bölgeleri hakkında çok daha az bilgi sahibidir. Uzaktan algılama görüntüleri ölçek, bakış açısı ve spektral bantlar bakımından farklılık gösterir ve bunlar için etiketler uzman bilgisi gerektirdiği için pahalıdır. Yalnızca birkaç örnek olduğunda, standart ince ayar yöntemleri aşırı uyum sağlar veya yakınsamayı başaramaz; bu da bu büyük modellerin coğrafi uygulamalarda yeterince kullanılmamasına yol açar.
Yalın Etiketlere Zengin Dil Eklemek
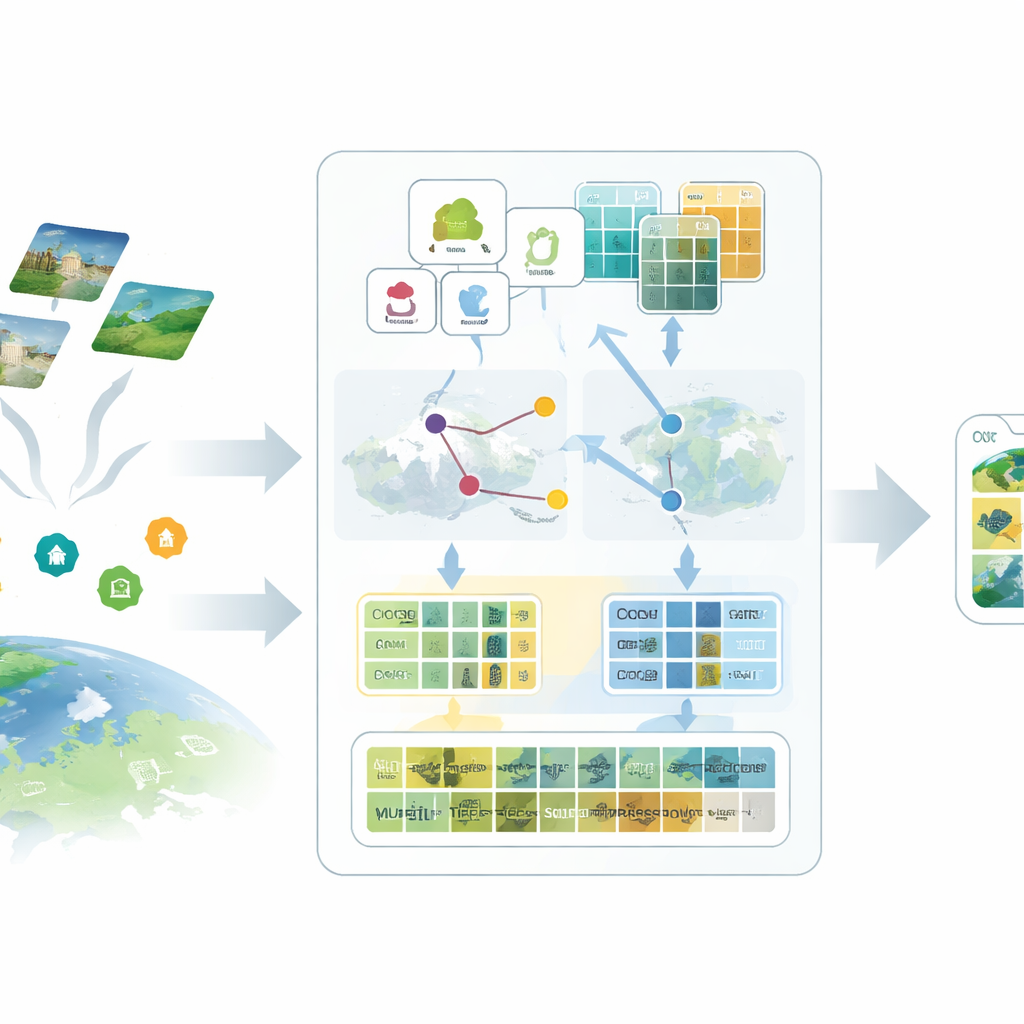
Önerilen SatAdapter çerçevesindeki ilk fikir, modele uydu görüntüleri açısından anlamlı şekilde “konuşmaktır”. “Havaalanı” veya “orman” gibi kısa sınıf isimleri vermek yerine yazarlar, büyük bir dil modelini kullanarak her sınıfın yukarıdan nasıl göründüğüne dair ayrıntılı tanımlamalar üretiyor—dokusu, şekilleri, desenleri ve mekânsal düzeni. Özenle tasarlanmış bir dizi soru istemi, dil modelini örneğin pistlerin nasıl hizalandığını, binaların nasıl kümelendiğini veya tarlaların nasıl düzenlendiğini tarif etmeye yönlendiriyor. Bu daha zengin betimlemeler, görsel–dil modeline her arazi kullanım türünün uydu görüntülerinde nasıl görünmesi gerektiğine dair daha net bir zihinsel resim sağlayan metin özelliklerine dönüştürülüyor.
Vekiller: Eksik Etiketlerin Yerine Geçmek
İkinci bileşen, eksik etiketleri vekiller adı verilen dikkatle kalibre edilmiş yer tutucularla değiştirir. SatAdapter, CLIP’in donmuş bir görüntü kodlayıcısıyla başlar ve etiketlenmemiş uydu görüntülerinin dil tabanlı sınıf tanımlarıyla nasıl ilişkili olduğunu hesaplar. Buradan, paylaşılan görüntü–metin uzayında yumuşak, öğrenilmiş sınıflandırıcılara benzeyen sınıf bazlı referans vektörleri oluşturur. Bu vekiller, omurga modeli hiçbir zaman değiştirilmeden verimli bir çevrimdışı optimizasyon yoluyla inceltilir. Daha güvenilir olmaları için yöntem, ince dokuları ve geniş düzenleri birlikte yakalayacak şekilde birbirini tamamlayan iki kodlayıcının—bir konvolüsyonel ağ ve bir görsel dönüştürücü—tahminlerini birleştirir. Sonuç, insan anotasyonlarını elle uğraşmadan yaklaşıklayan güvenli sahte etiketler kümesidir.
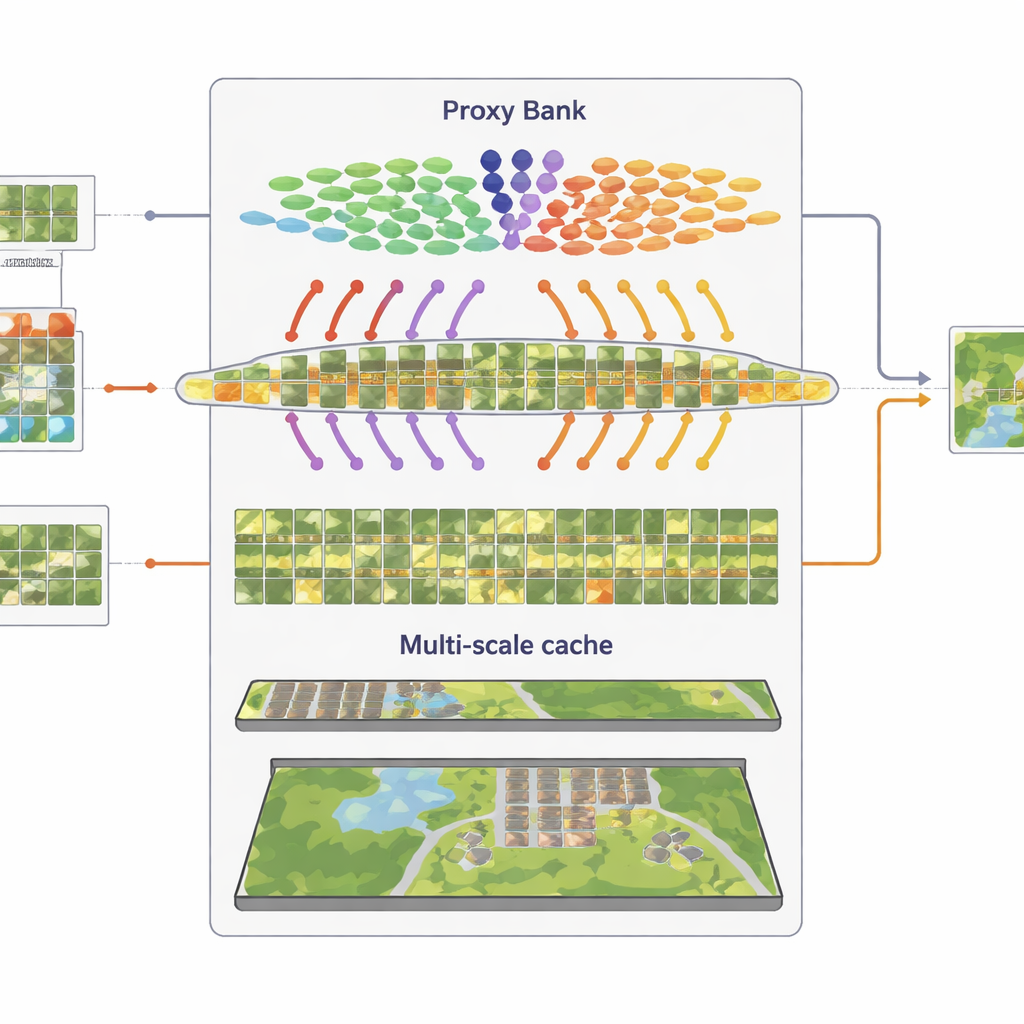
Görsel Desenleri Çoklu Ölçeklerde Hatırlamak
Üçüncü bileşen, temsilci görsel desenleri hatırlayan çok-dereceli bir “özellik önbelleği”dir. Güvenli şekilde sahte etiketlenmiş görüntülerden SatAdapter, hem yama düzeyindeki ayrıntıları hem de tüm sahne özetlerini anahtar–değer çiftleri olarak depolar. Çıkarım sırasında yeni bir görüntü geldiğinde, sistem onun bu önbelleğe ve vekil tabanlı tahminlere olan benzerliğini ölçer ve bunları orijinal sıfır atış (zero-shot) CLIP çıktısıyla birleştirir. Birkaç ağırlıklandırma parametresiyle kontrol edilen bu basit alma-ve-birleştirme işlemi, modelin önceki uydu sahnelerinde görülen doku, şekil ve düzenlere dair birikmiş bilgiyi gradyan tabanlı eğitim olmadan yeniden kullanmasını sağlar.
Farklı Peyzajlarda Fikri Kanıtlamak
SatAdapter’i test etmek için yazarlar, Avrupa tarım alanlarından küresel şehirlere, ABD banliyölerine ve karmaşık Çin kentsel sahnelerine kadar farklı çözünürlükler ve arazi örtüsü kategorileri içeren beş standart uydu kıyaslama setinde değerlendirme yapıyorlar. Sıfır atış koşullarında—yalnızca sınıf isimlerinin bilindiği durumlarda—SatAdapter birkaç önde gelen çapraz-modal temel yöntemi geride bırakıyor ve ortalama top-1 doğruluğu neredeyse beş yüzde puan artırıyor. 1 ila 16 etiketli görüntünün sınıf başına bulunduğu az örnekli (few-shot) ayarlarda da etiketli destek görüntüleri gerektiren önbellek tabanlı rakipleri yeniyor. Ablasyon çalışmaları her üç modülün de fayda sağladığını gösteriyor; ancak zengin istemler, vekil kalibrasyonu ve çok ölçekli önbelleklemenin birleşimi, omurga modelleri ve veri setleri genelinde en büyük ve en istikrarlı artışları sunuyor.
Değişen Dünyamızı İzlemek İçin Bunun Anlamı
Uzman olmayanlar için temel çıkarım şudur: SatAdapter, genel amaçlı görsel–dil yapay zekâyı alışılmış etiket veri talebi olmadan uydu görüntülerine uyarlamanın bir yolunu gösteriyor. Basit sınıf isimlerini betimleyici dil ile zenginleştirerek, etiketlenmemiş sahnelerden vekil sınıflandırıcılar oluşturarak ve görsel desenleri bir özellik önbelleği aracılığıyla yeniden kullanarak çerçeve, web üzerinde eğitilmiş genel bir modeli güçlü, az-veri gerektiren bir uzaktan algılama aracına dönüştürüyor. Bu, uzmanların yalnızca görüntülerin çok küçük bir kısmını etiketleyebildiği durumlarda bile arazi kullanımı, altyapı ve çevresel değişikliği ölçekli şekilde izlemeyi daha pratik hâle getiriyor.
Atıf: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Anahtar kelimeler: uzaktan algılama, görsel-dil modelleri, az örnekle öğrenme, uydu görüntüleri, coğrafi yapay zekâ