Clear Sky Science · en
Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching
Teaching Satellites to Understand the Earth with Less Data
Satellite images are a gold mine for tracking urban growth, monitoring crops, and responding to disasters—but turning those pictures into reliable maps usually demands thousands of painstaking human labels. This paper introduces a new way to make powerful image–language AI models work for satellite data even when labeled examples are scarce, helping unlock timely, detailed views of our planet without massive annotation efforts.
Why Regular AI Struggles with Space Views
Most modern vision–language systems, such as CLIP, are trained on everyday photos paired with short text from the web. They know a lot about cats, cars, and city streets, but much less about runways, rice paddies, or industrial parks seen from hundreds of kilometers above. Remote sensing images differ in scale, viewpoint, and spectral bands, and labels for them are expensive because they require expert knowledge. When only a few examples are available, standard fine-tuning methods tend to overfit or fail to converge, leaving these large models underused in geospatial applications.
Adding Rich Language to Bare-Bones Labels
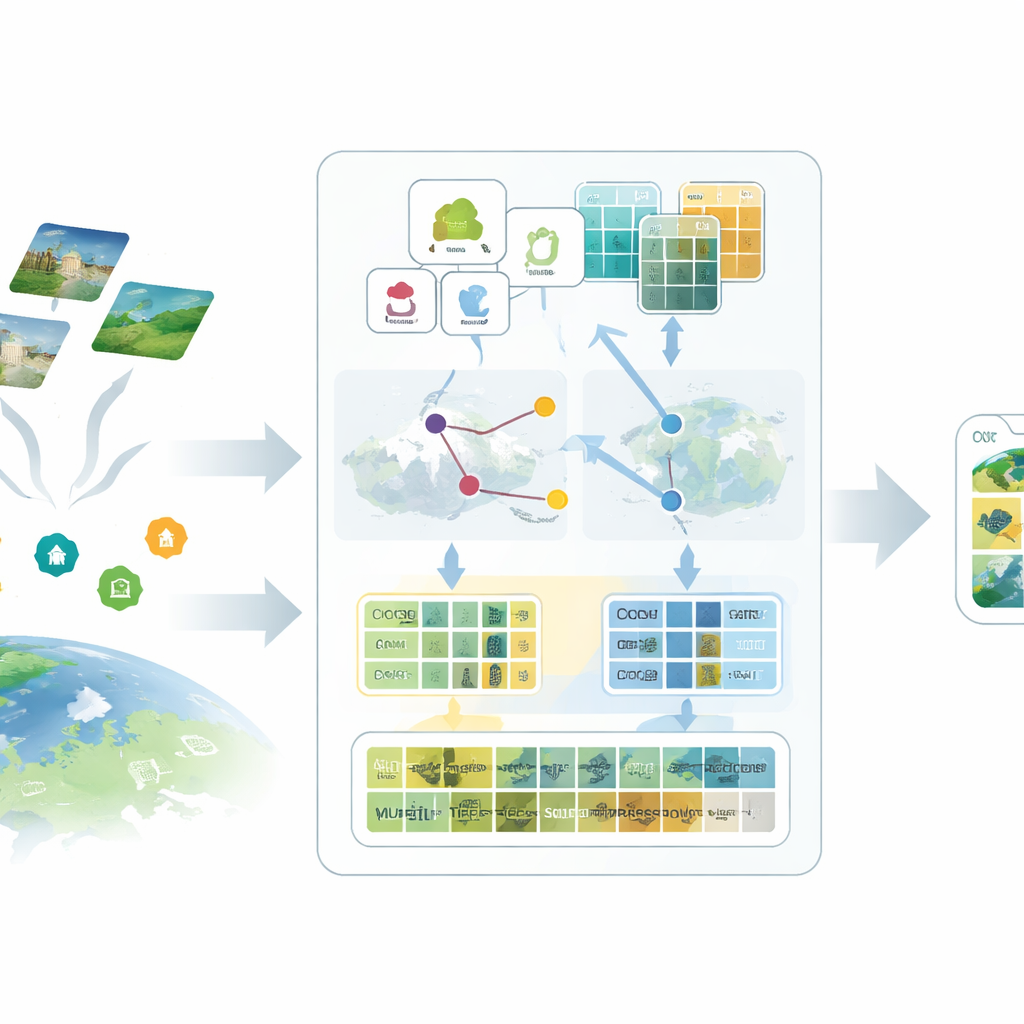
The first idea in the proposed SatAdapter framework is to “talk” to the model in a way that makes sense for satellites. Instead of feeding in short class names like “airport” or “forest,” the authors use a large language model to produce detailed descriptions of how each class looks from above—its texture, shapes, patterns, and spatial layout. Several carefully designed question prompts guide the language model to describe, for example, how runways align, how buildings cluster, or how fields are arranged. These richer descriptions are converted into text features that give the vision–language model a clearer mental picture of what each land-use type should look like in satellite imagery.
Proxies: Standing In for Missing Labels
The second ingredient replaces missing labels with carefully calibrated stand-ins called proxies. SatAdapter starts with a frozen image encoder from CLIP and computes how unlabeled satellite images relate to the language-based class descriptions. From this, it builds class-wise reference vectors that act like soft, learned classifiers within the shared image–text space. These proxies are refined through an efficient offline optimization that never alters the backbone model. To make them more reliable, the method fuses predictions from two complementary encoders—a convolutional network and a vision transformer—so that both fine textures and broad layouts contribute. The result is a set of confident pseudo-labels that approximate human annotations without manual effort.
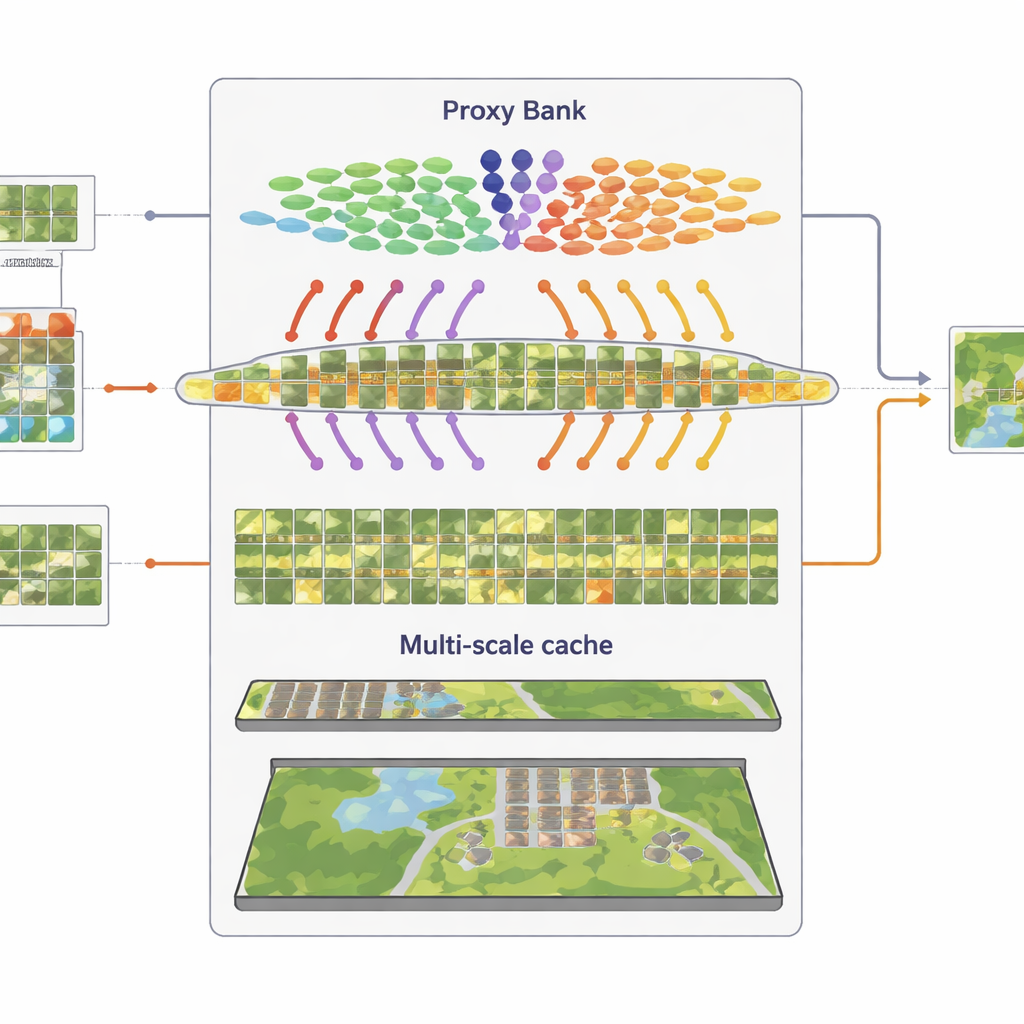
Remembering Visual Patterns at Multiple Scales
The third component is a multi-granularity “feature cache” that remembers representative visual patterns. From the confidently pseudo-labeled images, SatAdapter stores both patch-level details and whole-scene summaries as key–value pairs. During inference, when a new image arrives, the system measures its similarity to this cache and to the proxy-based predictions, combining them with the original zero-shot CLIP output. This simple retrieval-and-fuse process, controlled by a few weighting parameters, lets the model reuse accumulated knowledge about textures, shapes, and layouts seen in previous satellite scenes—without any gradient-based training.
Proving the Idea on Diverse Landscapes
To test SatAdapter, the authors evaluate it on five standard satellite benchmarks that span European farmland, global cities, U.S. suburbs, and complex Chinese urban scenes, each with different resolutions and land-cover categories. Under zero-shot conditions—where only class names are known—SatAdapter outperforms several leading cross-modal baselines, raising average top-1 accuracy by nearly five percentage points. In few-shot settings, where only 1 to 16 labeled images per class are available, it also beats cache-based competitors that require labeled support images. Ablation studies show that each of the three modules helps, but their combination—rich prompts, proxy calibration, and multi-scale caching—delivers the largest and most stable gains across backbones and datasets.
What This Means for Watching Our Changing World
For non-specialists, the key takeaway is that SatAdapter shows how to adapt general-purpose image–language AI to satellite imagery without the usual appetite for labeled data. By enriching simple class names with descriptive language, constructing proxy classifiers from unlabeled scenes, and recycling visual patterns through a feature cache, the framework turns a generic web-trained model into a strong, low-data remote sensing tool. This makes it more practical to monitor land use, infrastructure, and environmental change at scale, even when experts can label only a tiny fraction of the images streaming down from space.
Citation: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Keywords: remote sensing, vision-language models, few-shot learning, satellite imagery, geospatial AI