Clear Sky Science · ar
التكيُّف عبر الوسائط بكمية بيانات قليلة للاستشعار عن بُعد مع تخزين ميزات متعدد الدقة معزَّز بالوكلاء
تعليم الأقمار الصناعية فهم الأرض ببيانات أقل
تُعد صور الأقمار الصناعية منجمًا ثمينًا لتتبع النمو الحضري ومراقبة المحاصيل والاستجابة للكوارث—لكن تحويل تلك الصور إلى خرائط موثوقة عادةً ما يتطلب آلاف التسميات اليدوية المجهدة. تُقدِّم هذه الورقة طريقة جديدة لجعل نماذج الذكاء الاصطناعي القوية بين الصور والنصوص تعمل على بيانات الأقمار الصناعية حتى عندما تكون الأمثلة الموسومة نادرة، ما يساعد على فتح رؤى مفصَّلة وفي الوقت المناسب عن كوكبنا دون جهود تعليق واسعة النطاق.
لماذا تكافح نظم الذكاء الاصطناعي العادية مع مشاهد الفضاء
تُدرَّب معظم أنظمة الرؤية–اللغة الحديثة، مثل CLIP، على صور يومية مقترنة بنصوص قصيرة من الويب. هي تعرف الكثير عن القطط والسيارات وشوارع المدن، لكن لديها معرفة أقل عن المدارج وحقول الأرز أو المتنزهات الصناعية المرصودة من مئات الكيلومترات فوق سطح الأرض. تختلف صور الاستشعار عن بُعد في المقياس وزاوية العرض والأطياف، وتسمياتها مكلفة لأنها تتطلب خبرة متخصصة. عندما تتوفر أمثلة قليلة فقط، تميل طرق الضبط الدقيق القياسية إلى الإفراط في التعلّم أو الفشل في التقارب، مما يترك هذه النماذج الكبيرة غير مستغلة في التطبيقات الجغرافية المكانية.
إضافة لغة غنية إلى التسميات البسيطة
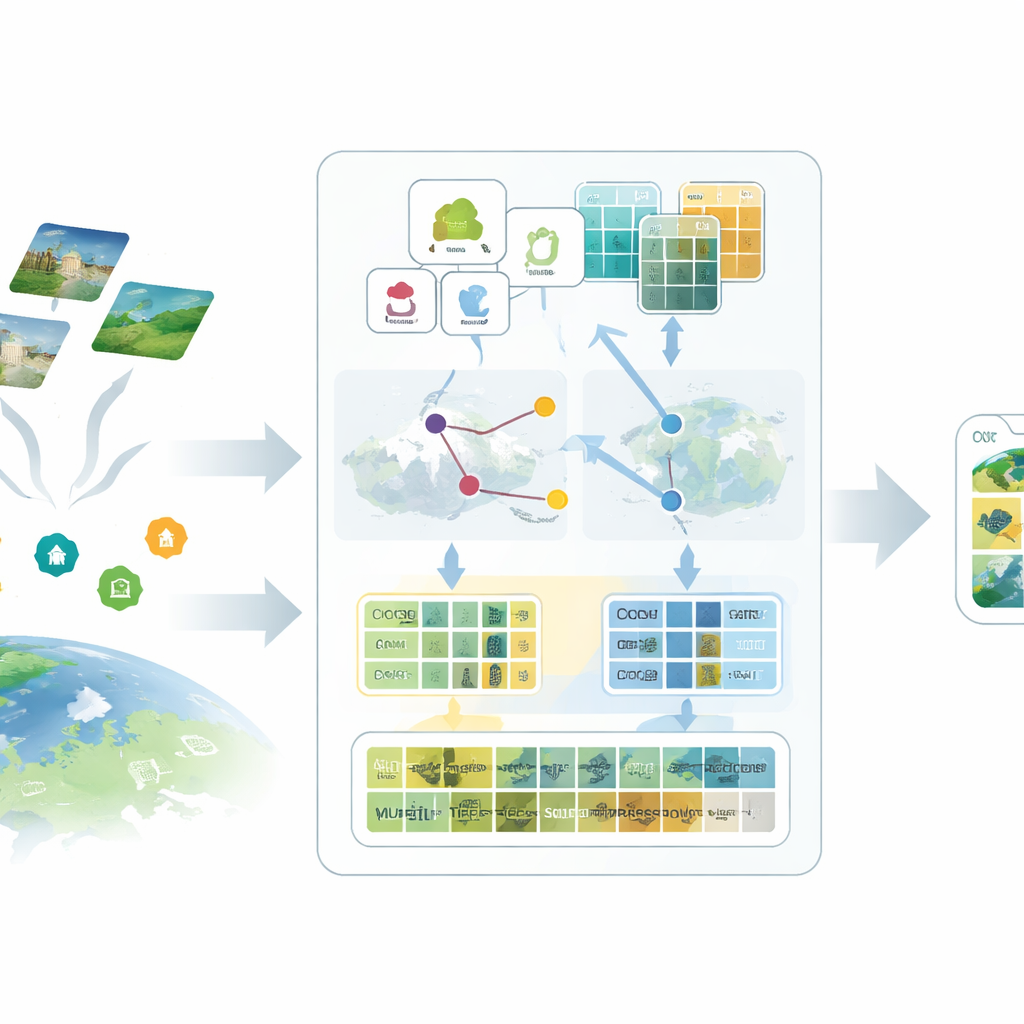
الفكرة الأولى في إطار SatAdapter هي «التحدُّث» إلى النموذج بطريقة تتناسب مع الأقمار الصناعية. بدلاً من إدخال أسماء فئات قصيرة مثل «مطار» أو «غابة»، يستخدم المؤلفون نموذج لغة كبيرًا لإنتاج أوصاف مفصّلة لكيفية ظهور كل فئة من الأعلى—قوامها وأشكالها وأنماطها والتوزيع المكاني لها. توجّه عدة برومبتات مصممة بعناية نموذج اللغة لوصف، على سبيل المثال، كيفية استقامة المدارج، وكيف تتجمّع المباني، أو كيف تُرتَّب الحقول. تُحوَّل هذه الأوصاف الأكثر ثراءً إلى ميزات نصية تمنح نموذج الرؤية–اللغة صورة ذهنية أوضح لما ينبغي أن تبدو عليه كل فئة استخدام أرضي في صور الأقمار الصناعية.
الوكلاء: بدائل للتسميات المفقودة
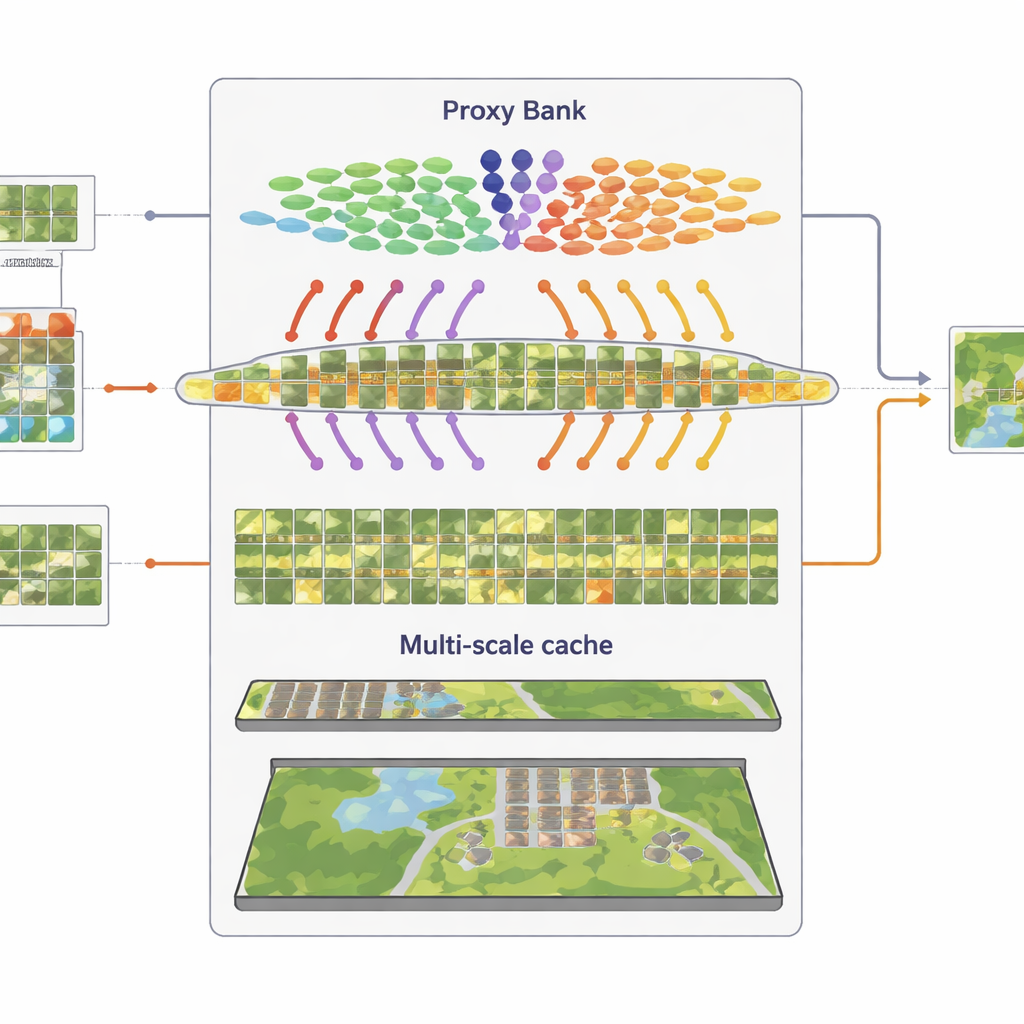
المكوِّن الثاني يستبدل التسميات المفقودة ببدائل مُعايَرة بعناية تُسمى وكلاء. يبدأ SatAdapter مع مشفِّر صور ثابت من CLIP ويحسب كيف ترتبط الصور الفضائية غير الموسومة بوصف الفئات المستند إلى اللغة. من هذا يبني متجهات مرجعية على مستوى الفئة تعمل كمصنّفات لينة متعلَّمة داخل الفضاء المشترك للصورة والنص. تُنقَّح هذه الوكلاء من خلال تحسين غير متصل فعّال لا يغيِّر الهيكل الخلفي الأساسي. لجعلها أكثر موثوقية، تدمج الطريقة توقعات من مشفِّرين مُكمِّلين—شبكة التلافيف ومحول الرؤية—بحيث تُساهم كل من القوام الدقيقة والتوزيعات الواسعة. النتيجة هي مجموعة من التسميات الكاذبة الواثقة التي تقترب من تسميات البشر دون جهد يدوي.
تذكُّر الأنماط البصرية على مقاييس متعددة
المكوّن الثالث هو «مخبأ ميزات» متعدد الدقة يتذكّر أنماطًا بصرية ممثلة. من الصور التي وُصفت بتسميات كاذبة واثقة، يخزن SatAdapter تفاصيل على مستوى الرقعة وملخّصات المشهد الكامل كأزواج مفتاح–قيمة. أثناء الاستدلال، عندما تصل صورة جديدة، يقيس النظام تشابهها مع هذا المخبأ ومع توقعات الوكلاء، مدمجًا إياها مع خرج CLIP الصفري الأصلي. تتيح هذه العملية البسيطة للاسترجاع والدمج، التي يتحكم فيها بعض معلمات الوزن، للنموذج إعادة استخدام المعرفة المتراكمة عن القوام والأشكال والتوزيعات التي لوحظت في مشاهد فضائية سابقة—دون أي تدريب قائم على التدرجات.
إثبات الفكرة على مناظِر متنوعة
لاختبار SatAdapter، يقيمه المؤلفون على خمسة معايير قياسية للأقمار الصناعية تغطي مزارع أوروبية، ومدن عالمية، وضواحي أمريكية، ومشاهد حضرية صينية معقدة، كل منها بدقّات وفئات تغطية أرضية مختلفة. في ظروف الصفر-إطلاق—حيث تُعرف أسماء الفئات فقط—يتفوّق SatAdapter على عدة قواعد مقارنة عابرة الوسائط رائدة، رافعًا متوسط دقة القمة-1 بنحو خمس نقاط مئوية. في إعدادات عدد العينات القليل، حيث تتوفر فقط من 1 إلى 16 صورة موسومة لكل فئة، يتغلب أيضًا على المنافسين المعتمدين على المخبأ الذين يتطلبون صور دعم موسومة. تُظهر دراسات النزع أن كل واحد من المكوّنات الثلاثة مفيد، لكن مزيجها—البرومبتات الغنية، ومعايرة الوكلاء، وتخزين متعدد المقاييس—يُقدّم أكبر المكاسب وأكثرها استقرارًا عبر البنى الخلفية ومجموعات البيانات.
ماذا يعني هذا لمراقبة عالمنا المتغير
بالنسبة لغير المتخصصين، الخلاصة هي أن SatAdapter يوضّح كيفية تكييف نماذج الذكاء الاصطناعي العامة للرؤية–اللغة مع صور الأقمار الصناعية دون الحاجة المعتادة إلى الكثير من البيانات الموسومة. من خلال إثراء أسماء الفئات البسيطة بلغة وصفية، وبناء مصنّفات وكيلة من المشاهد غير الموسومة، وإعادة استخدام الأنماط البصرية عبر مخبأ ميزات، يحوّل الإطار نموذجًا عامًا مُدرَّبًا على الويب إلى أداة استشعار عن بُعد قوية وموفرة للبيانات. يجعل هذا من العملي أكثر مراقبة استخدامات الأراضي والبنية التحتية والتغير البيئي على نطاق واسع، حتى عندما يستطيع الخبراء وسم جزء صغير فقط من الصور المتدفقة من الفضاء.
الاستشهاد: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
الكلمات المفتاحية: الاستشعار عن بُعد, نماذج الرؤية واللغة, التعلُّم بعدد عينات قليل, صور الأقمار الصناعية, الذكاء الجغرافي المكاني