Clear Sky Science · ja
プロキシ強化マルチ粒度特徴キャッシングによるリモートセンシングの低データ跨モーダル適応
衛星に地球の見方を少ないデータで教える
衛星画像は都市の拡大、作物の監視、災害対応を追跡するための宝の山ですが、それらの画像を信頼できる地図に変換するには通常、何千もの手作業によるラベルが必要です。本論文は、ラベル付き例が乏しい場合でも強力な画像と言語のAIモデルを衛星画像に適用できる新手法を紹介します。これにより、大規模な注釈作業なしにタイムリーで詳細な地球の可視化が可能になります。
通常のAIが宇宙からの眺めで苦戦する理由
CLIPのような現代の多くのビジョン–ランゲージシステムは、日常的な写真と短いウェブテキストの組み合わせで訓練されています。これらは猫や車、街路については多くを知っていますが、数百キロ上空から見た滑走路、稲作地帯、産業団地については十分に学んでいません。リモートセンシング画像はスケール、視点、スペクトル帯が異なり、ラベル付けには専門知識が必要で高コストです。利用可能な例が少ない場合、標準的なファインチューニングは過学習や収束失敗に陥りがちで、大型モデルが地理空間用途で十分に活用されません。
簡素なラベルに豊かな言語を付与する
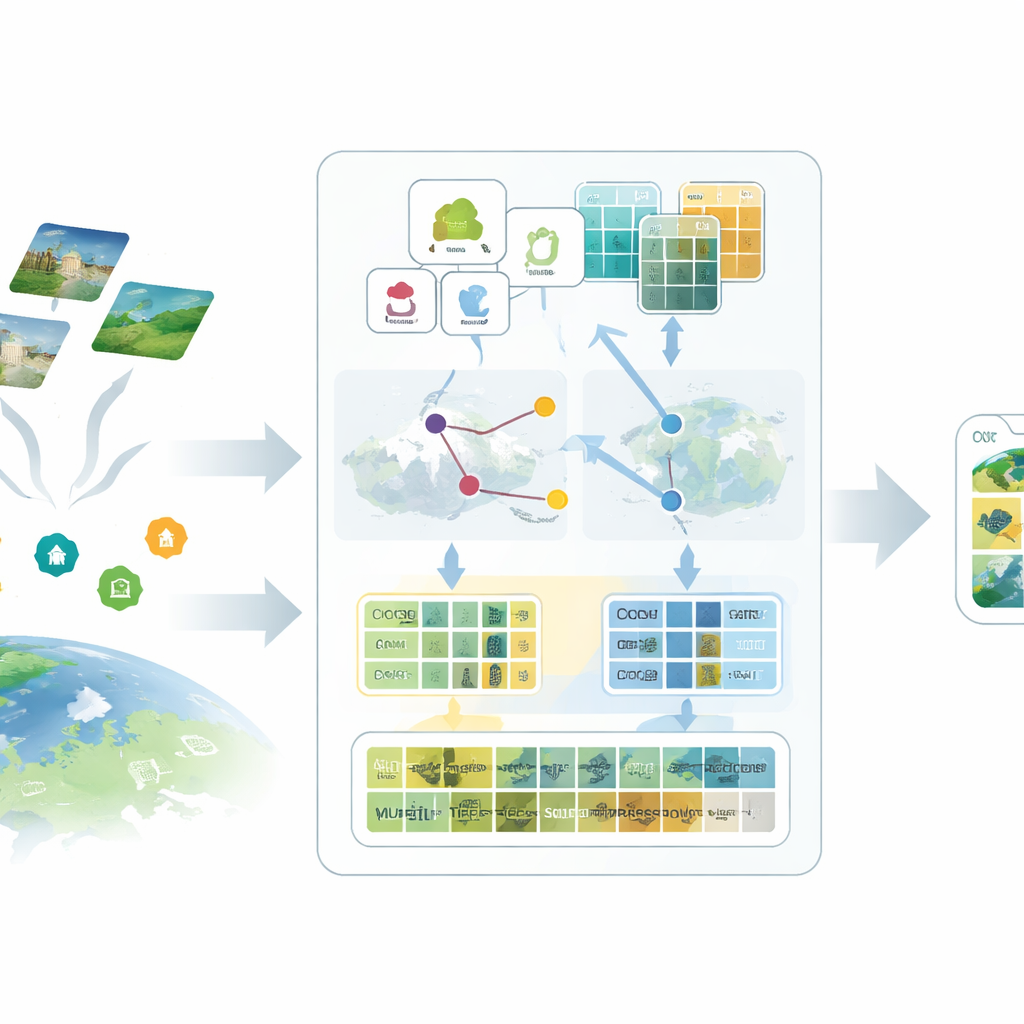
提案するSatAdapterフレームワークの第一のアイデアは、衛星画像に適した“語りかけ方”をモデルに与えることです。「空港」や「森林」のような短いクラス名を与える代わりに、著者らは大規模言語モデルを用いて各クラスが上空からどのように見えるかを詳細に記述させます—質感、形状、パターン、空間配置などです。慎重に設計された複数のプロンプトが、滑走路の配列や建物の集まり方、畑の並び方といった特徴を言語モデルに説明させます。こうした豊かな記述はテキスト特徴に変換され、ビジョン–ランゲージモデルに各土地利用タイプが衛星画像でどう見えるべきかのより明確なイメージを与えます。
欠けたラベルの代わりに立つプロキシ
第二の要素は、プロキシと呼ばれる精緻に較正された代替表現で欠損ラベルを置き換えることです。SatAdapterは凍結されたCLIPの画像エンコーダから始め、ラベルのない衛星画像が言語ベースのクラス記述とどのように関連するかを算出します。そこからクラスごとの参照ベクトルを構築し、共有の画像–テキスト空間内でソフトな学習済み分類器のように振る舞わせます。これらのプロキシはバックボーンモデルを変更せずに行う効率的なオフライン最適化で精緻化されます。信頼性を高めるために、方法は畳み込みネットワークとビジョントランスフォーマーという相補的な2つのエンコーダの予測を融合し、細かな質感と広域のレイアウトの両方を寄与させます。結果として、人手による注釈なしにそれらを近似する自信の高い疑似ラベルの集合が得られます。
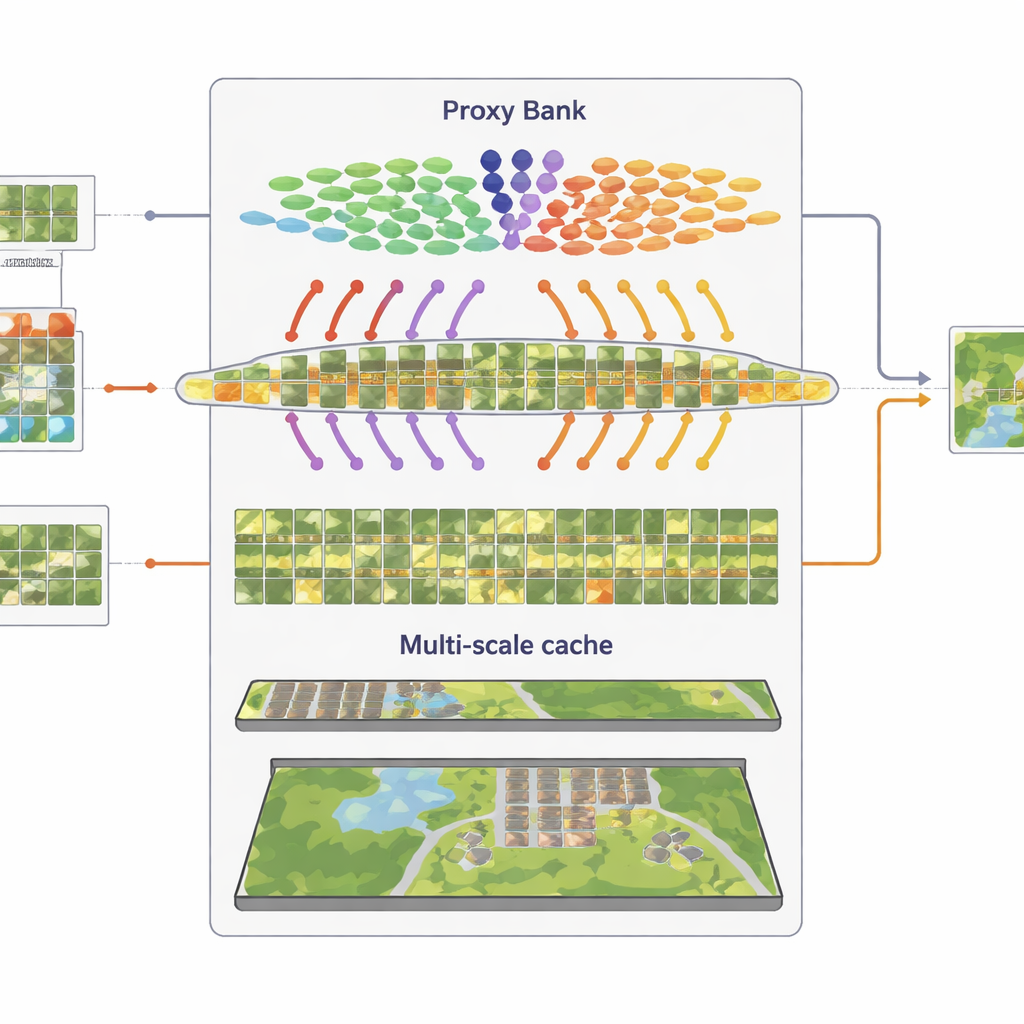
複数スケールの視覚パターンを記憶する
第三の構成要素は、代表的な視覚パターンを記憶するマルチ粒度の「特徴キャッシュ」です。自信の高い疑似ラベル付き画像から、SatAdapterはパッチレベルの詳細とシーン全体の要約の両方をキー–バリューペアとして格納します。推論時に新しい画像が入力されると、システムはその画像とキャッシュ、さらにプロキシベースの予測との類似度を測り、元のゼロショットCLIP出力と組み合わせます。いくつかの重み付けパラメータで制御されるこの単純な検索と融合のプロセスにより、以前の衛星シーンで観察された質感、形状、レイアウトに関する蓄積知識を勾配ベースの訓練なしで再利用できます。
多様な景観での有効性を実証
SatAdapterを検証するため、著者らは解像度や地表カテゴリが異なるヨーロッパの農地、世界の都市、米国郊外、複雑な中国の都市景観などを含む5つの標準的な衛星ベンチマークで評価しました。クラス名のみが知られているゼロショット条件下で、SatAdapterは複数の主要な跨モーダルベースラインを上回り、平均トップ1精度を約5ポイント引き上げました。1〜16枚のラベル画像しか利用できない少ショット設定でも、ラベル付きサポート画像を必要とするキャッシュベースの競合手法を凌駕しました。アブレーション研究により、3つのモジュールそれぞれが寄与することが示されましたが、豊かなプロンプト、プロキシの較正、マルチスケールキャッシングの組み合わせがバックボーンやデータセット全体で最大かつ最も安定した改善をもたらしました。
変わりゆく世界を監視するための意味
非専門家にとっての要点は、SatAdapterが一般目的の画像–言語AIを大量のラベルを必要とせずに衛星画像へ適応させる方法を示したことです。単純なクラス名を記述的な言語で豊かにし、ラベルのないシーンからプロキシ分類器を構築し、特徴キャッシュで視覚パターンを再利用することで、このフレームワークはウェブで訓練された汎用モデルを強力な低データのリモートセンシングツールへと変えます。これにより、専門家がごく一部の画像しかラベル付けできない状況でも、土地利用やインフラ、環境変化を大規模に監視する実用性が高まります。
引用: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
キーワード: リモートセンシング, ビジョン・ランゲージモデル, 少ショット学習, 衛星画像, 地理空間AI