Clear Sky Science · ru
Адаптация кросс-модальных моделей при малом объёме данных для дистанционного зондирования с прокси-усиленным многозернистым кешированием признаков
Обучение спутников «понимать» Землю при небольшом объёме данных
Спутниковые снимки — кладезь информации для отслеживания роста городов, мониторинга посевов и реагирования на катастрофы — но превращение этих изображений в надёжные карты обычно требует тысяч кропотливых разметок людьми. В статье предложен новый подход, который позволяет мощным визуально-языковым моделям работать со спутниковыми данными даже при дефиците размеченных примеров, помогая получать оперативные и детальные представления о нашей планете без массовых усилий по аннотированию.
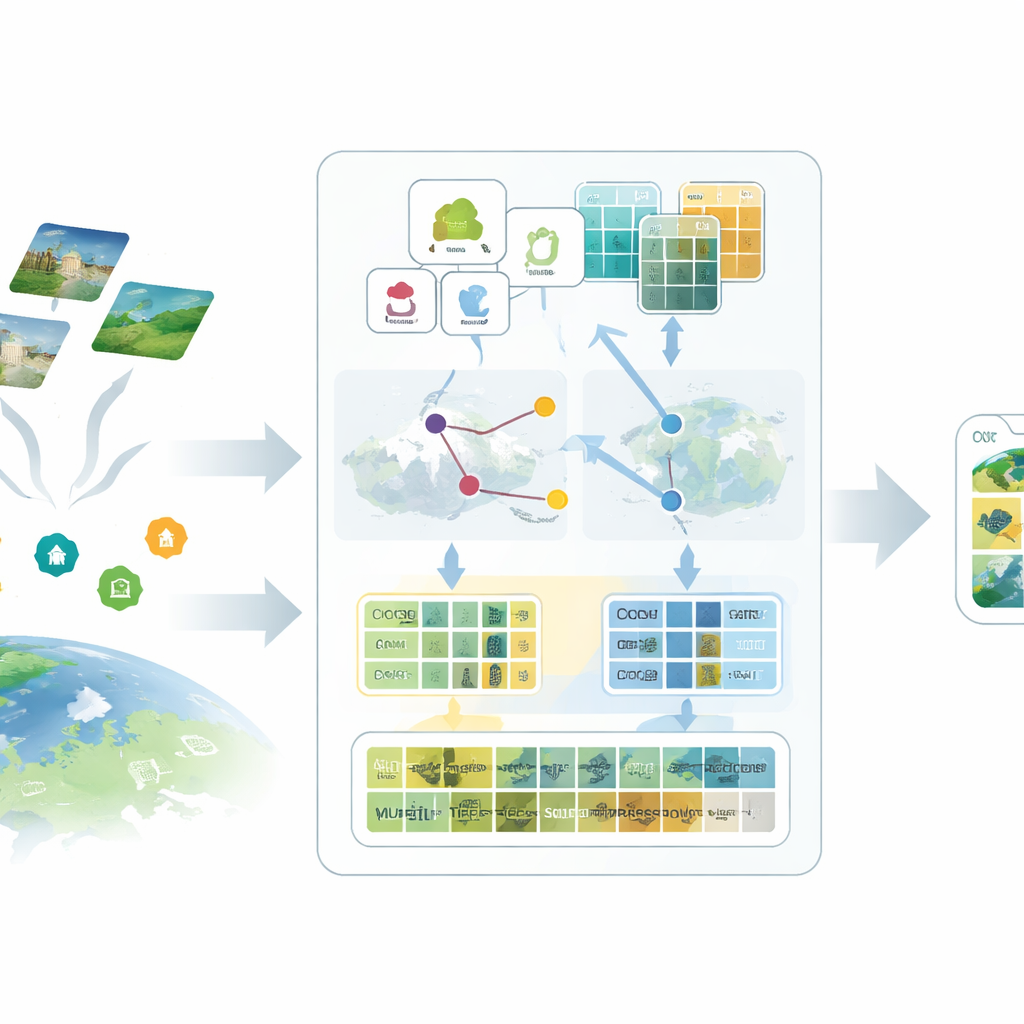
Почему обычным ИИ трудно снимать со спутника
Большинство современных визуально-языковых систем, таких как CLIP, обучены на обычных фотографиях с короткими подписями из интернета. Они многое знают о кошках, автомобилях и городских улицах, но гораздо меньше — о взлётно-посадочных полосах, рисовых полях или промышленных парках, снятых с сотен километров высоты. Изображения дистанционного зондирования отличаются по масштабу, точке съёмки и спектральным каналам, а их разметка дорога, поскольку требует экспертных знаний. Когда доступно лишь несколько примеров, стандартные методы дообучения склонны к переобучению или не сходятся, из-за чего крупные модели остаются малоиспользованными в геопространственных приложениях.
Обогащение скромных меток выразительным языком
Первая идея в предложенной SatAdapter — «разговаривать» с моделью на языке, понятном для спутниковых съёмок. Вместо коротких названий классов вроде «аэропорт» или «лес» авторы используют большую языковую модель для генерации подробных описаний того, как каждый класс выглядит сверху — его текстуры, формы, узоры и пространственная организация. Несколько тщательно продуманных подсказок направляют языковую модель описывать, например, выравнивание взлётно-посадочных полос, скопления зданий или расположение полей. Эти более богатые описания преобразуются в текстовые признаки, дающие визуально-языковой модели более ясное представление о том, как должен выглядеть каждый тип землепользования на спутниковом снимке.
Прокси: замена отсутствующих меток
Второй компонент заменяет отсутствующие метки тщательно откалиброванными заместителями — прокси. SatAdapter использует зафиксированный (frozen) кодировщик изображений из CLIP и оценивает, как немаркированные спутниковые изображения соотносятся с текстовыми описаниями классов. На основе этого строятся векторы-эталоны для каждого класса, которые ведут себя как мягкие, обучаемые классификаторы в общем пространстве изображение‑текст. Эти прокси уточняются через эффективную офлайн-оптимизацию, которая никогда не меняет базовую модель. Чтобы сделать прокси более надёжными, метод объединяет предсказания двух дополнительных кодировщиков — сверточной сети и визуального трансформера — так что и тонкие текстуры, и широкие композиционные шаблоны вносят вклад. В результате получается набор уверенных псевдометок, приближённых к человеческой разметке без ручного труда.
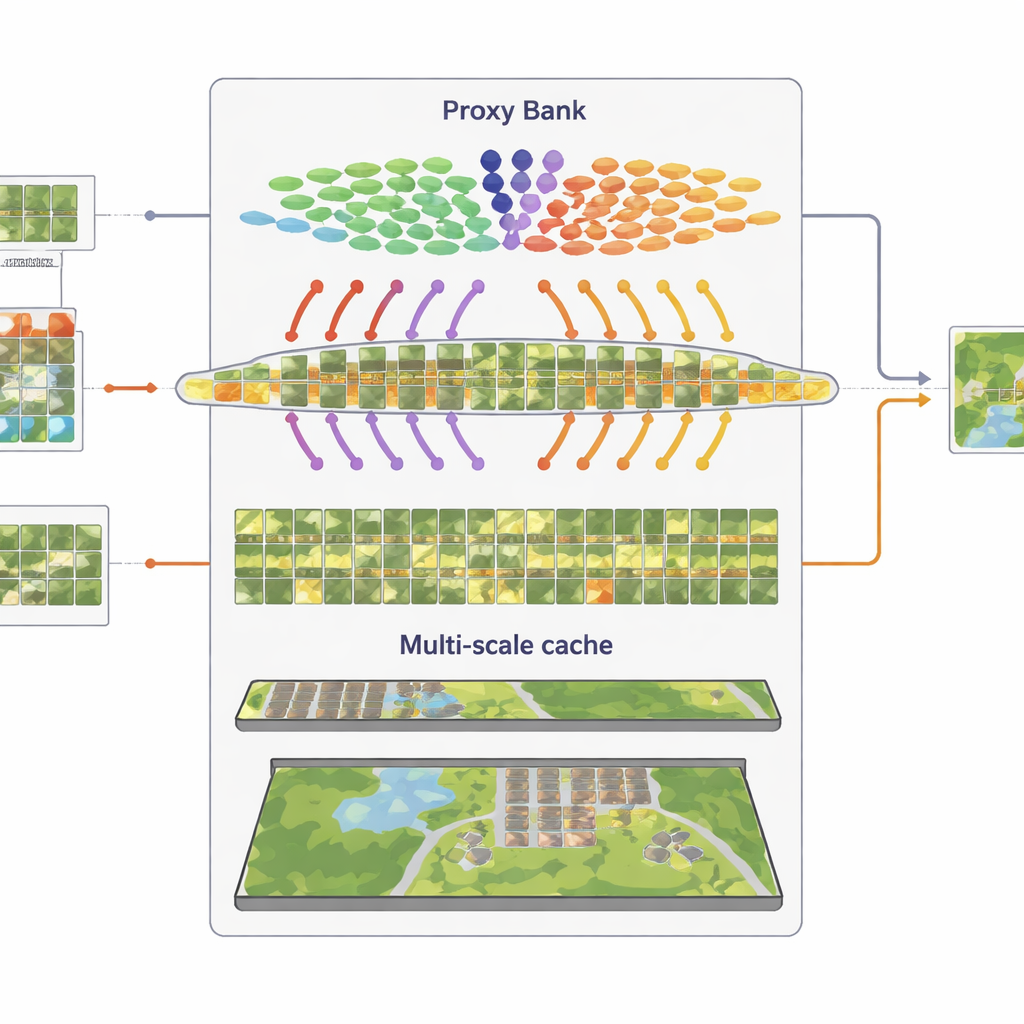
Запоминание визуальных паттернов на нескольких масштабах
Третий компонент — многозернистый «кеш признаков», который сохраняет представительные визуальные паттерны. Из уверенно псевдомаркированных изображений SatAdapter хранит как детали на уровне патчей, так и сводки целых сцен в виде пар ключ–значение. При инференсе, когда приходит новое изображение, система измеряет его сходство с этим кешем и с прокси‑предсказаниями, объединяя их с исходным нулевым (zero-shot) выходом CLIP. Этот простой процесс поиска и слияния, контролируемый несколькими весовыми параметрами, позволяет модели повторно использовать накопленные знания о текстурах, формах и композициях, встречающихся в предыдущих спутниковых сценах — без градиентного обучения.
Проверка идеи на разнообразных ландшафтах
Чтобы оценить SatAdapter, авторы протестировали его на пяти стандартных спутниковых наборах данных, охватывающих европейские сельхозугодья, мировые города, пригородные зоны США и сложные китайские урбанистические сцены, каждая с разным разрешением и категориями земного покрытия. В условиях zero-shot — когда известны только названия классов — SatAdapter превосходит несколько ведущих кросс-модальных базовых методов, повышая среднюю top-1 точность почти на пять процентных пунктов. В задачах few-shot, где доступно от 1 до 16 размеченных изображений на класс, он также обходит конкурентов, использующих кеши, но требующих размеченные поддерживающие изображения. Исследования абляций показывают, что каждый из трёх модулей улучшает результат, но их комбинация — богатые подсказки, калибровка прокси и многомасштабное кеширование — даёт наибольший и наиболее стабильный прирост по разным бэбонам и наборам данных.
Что это означает для наблюдения за изменяющимся миром
Для неспециалистов ключевая мысль такова: SatAdapter показывает, как адаптировать универсальные визуально-языковые модели к спутниковым изображениям без привычной потребности в огромном объёме размеченных данных. Обогащая простые названия классов описательным языком, конструируя прокси‑классификаторы из немаркированных сцен и повторно используя визуальные шаблоны через кеш признаков, фреймворк превращает общую модель, обученную на веб‑данных, в мощный инструмент дистанционного зондирования при малом количестве данных. Это делает более практичным мониторинг землепользования, инфраструктуры и экологических изменений в масштабах, даже когда эксперты могут разметить лишь крошечную долю изображений, поступающих из космоса.
Цитирование: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Ключевые слова: дистанционное зондирование, визуально-языковые модели, обучение при малом числе примеров, спутниковые изображения, геопространственный ИИ