Clear Sky Science · he
התאמה חוצת-ממדים עם נתונים מועטים ברחף-רחוק באמצעות מטמון תכונות מרובה-גרנולריות משופר בפרוקסי
להדריך לוויינים להבין את כדור הארץ עם פחות נתונים
תמונות לוויין הן אוצר לרישום גידול עירוני, ניטור גידולים ותגובה לאסונות — אבל המרת התמונות הללו למפות מהימנות דורשת בדרך כלל אלפי תוויות אנושיות מייגעות. המאמר מציג דרך חדשה לגרום למודלים חזקים משולבי תמונה–טקסט לעבוד על נתוני לוויין גם כשהדוגמאות המסומנות נדירות, ובכך לאפשר תצפיות מדויקות ומעודכנות על כוכב הלכת שלנו בלי מאמצי תיוג המוניים.
למה בינה רגילה מתקשה עם מבטים מרחוק
מרבית מערכות הראייה–שפה המודרניות, כמו CLIP, מאומנות על תמונות יום-יום המשולבות עם טקסט קצר מהאינטרנט. הן יודעות הרבה על חתולים, מכוניות ורחובות עירוניים, אך פחות על מסלולי נחיתה, שדות אורז או פארקי תעשייה המוצגים ממאות קילומטרים למעלה. תמונות חישה מרחוק שונות בקנה מידה, בנקודת המבט ובתחומי הספקטרום, ותוויות עבורן יקרות כי הן דורשות מומחיות. כשיש רק כמה דוגמאות, שיטות כוונון מקובלות נוטות להיפגע מהתאמה-יתר או לא להתכנס, ומשאירות מודלים גדולים אלה לא מנוצלים ביישומי גיאו-מרחב.
להעשיר תוויות קצרות בשפה עשירה
הרעיון הראשון במסגרת המוצעת SatAdapter הוא "לדבר" עם המודל באופן שמתאים ללוויינים. במקום להזין שמות כיתות קצרים כמו "שדה תעופה" או "יער", המחברים משתמשים במודל שפה גדול כדי לייצר תיאורים מפורטים של איך כל כיתה נראית מלמעלה — מרקמה, צורות, דפוסים ופריסת מרחב. מספר הנחיות-שאלה מעוצבות בקפידה מנחות את מודל השפה לתאר, למשל, כיצד מסלולי נחיתה מיושרים, כיצד מבנים מתמקדים או כיצד שדות מסודרים. התיאורים העשירים הללו מומרצים לתכונות טקסט שנותנות למודל ראייה–שפה תמונה מנטלית ברורה יותר של איך כל סוג שימוש-קרקע אמור להיראות בתמונות לוויין.
פרוקסים: ממלאי מקום לתוויות חסרות
המרכיב השני מחליף תוויות חסרות בממלאי-מקום מכוילים בקפידה הנקראים פרוקסים. SatAdapter מתחיל עם מקודד תמונה קפוא של CLIP ומחשב כיצד תמונות לוויין ללא תוויות יחסיות לתיאורי הכיתה המבוססי-שפה. מכך הוא בונה וקטורי ייחוס לכל כיתה המשמשים כמיין-רכים רכים בלולאת המרחב המשותף של תמונה וטקסט. פרוקסים אלה מחדדים באמצעות אופטימיזציה יעילה לא-מקוונת שלא משנה את מבנה הגב. כדי להגדיל את אמינותם, השיטה ממזגת תחזיות משני מקודדים משלימים — רשת קונבולוציה ואדריכליית ויז׳ן טרנספורמר — כך שגם מרקמים עדינים וגם פריסות רחבות תורמים. התוצאה היא סט של תוויות-פייג׳ו בטוחות שמקרבות לתוויות אנושיות ללא מאמץ ידני.
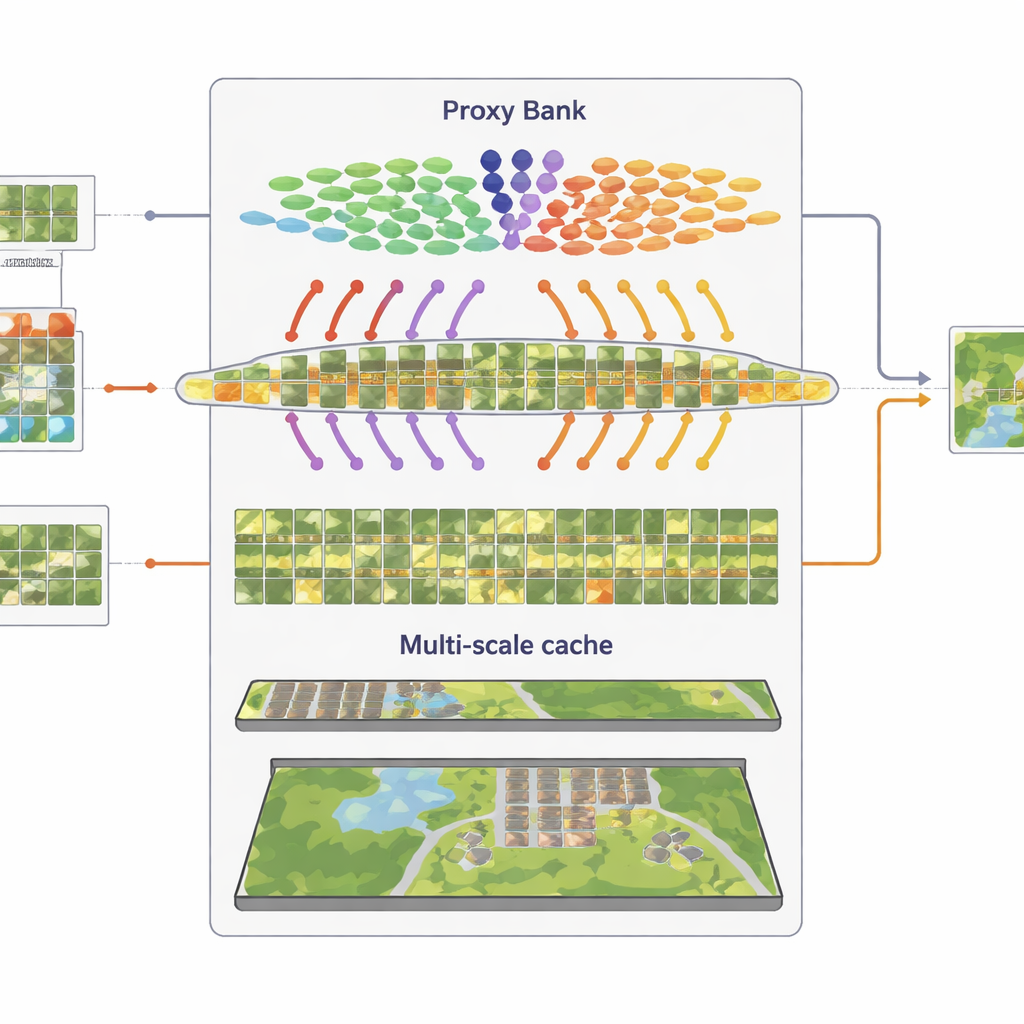
לזכור דפוסים חזותיים ברמות רבות
המרכיב השלישי הוא "מטמון תכונות" מרובה-גרנולריות שזוכר דפוסים חזותיים מייצגים. מתוך התמונות שסומנו בפייג׳ו בביטחון, SatAdapter מאחסן הן פרטים ברמת חתיכות והן סיכומי סצנה כולה כצמדי מפתח–ערך. בזמן הסקה, כאשר תמונה חדשה מגיעה, המערכת מודדת את הדמיון שלה למטמון זה ולתחזיות המבוססות-פרוקסי, ומשלבת אותן עם פלט ה-CLIP האפס-ירי המקורי. תהליך של שליפה ומיזוג פשוט זה, הנשלט על ידי כמה פרמטרי משקל, מאפשר למודל להשתמש מחדש בידע שנצבר על מרקמים, צורות ופריסות שנראו בסצנות לוויין קודמות — ללא כל אימון מבוסס גרדיאנט.
להוכיח את הרעיון על נופים מגוונים
כדי לבחון את SatAdapter, המחברים מעריכים אותו על חמישה מאגרי בדיקה סטנדרטיים של לוויין המשתרעים על פני חקלאות אירופית, ערים גלובליות, פרוורים בארה"ב וסצנות עירוניות סיניות מורכבות, כל אחד עם רזולוציות וקטגוריות כיסוי קרקע שונות. בתנאי אפס-ירי — שבהם ידועים רק שמות הכיתות — SatAdapter עולה על כמה מהבסיסים החוצי-ממדי המובילים, ומעלה את דיוק top-1 הממוצע בכמעט חמש נקודות אחוז. בהגדרות מעט-דוגמאות, שבהן זמינות רק 1 עד 16 תמונות מסומנות לכל כיתה, הוא גם מביס מתחרים מבוססי-מטמון שדורשים תמונות תמיכה מסומנות. מחקרי אבולוציה מראים שכל אחד מהשלושה מודולים תורם, אך השילוב — הנחיות עשירות, כיול פרוקסי ומטמון רב-קנה מידה — מספק את השיפורים הגדולים והיציבים ביותר על פני גב-מודלים ומאגרי נתונים.
מה זה אומר לגבי מעקב אחר העולם המשתנה שלנו
ללא-מומחים, המסקנה המרכזית היא ש-SatAdapter מראה כיצד להתאים מודלים כלליים של תמונה–שפה לתמונות לוויין בלי התיאבון הרגיל לנתונים מסומנים. בהעשרת שמות כיתות פשוטים בשפה תיאורית, בבניית מסווגים פרוקסי מתוך סצנות ללא תוויות ובמיחזור דפוסים חזותיים דרך מטמון תכונות, המסגרת הופכת מודל כללי מאומן-אינטרנט לכלי חישה מרחוק חזק ודל-נתונים. זה מקל על ניטור שימושי קרקע, תשתיות ושינוי סביבתי בקנה מידה, גם כאשר מומחים יכולים לתייג רק חלק זעום מהתמונות הזורמות מלמעלה.
ציטוט: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
מילות מפתח: חישה מרחוק, מודלים ראייה-שפה, למידה במעט דוגמאות, תמונות לוויין, בינה גיאו-מרחבית