Clear Sky Science · es
Adaptación cruzada multimodal con pocos datos para teledetección mediante almacenamiento en caché de características multigranulares mejorado con proxys
Enseñar a los satélites a entender la Tierra con menos datos
Las imágenes satelitales son una mina de oro para seguir el crecimiento urbano, monitorizar cultivos y responder a desastres, pero convertir esas imágenes en mapas fiables suele exigir miles de etiquetas hechas a mano. Este artículo presenta una nueva forma de hacer que modelos potentes de IA imagen–lenguaje funcionen con datos satelitales incluso cuando los ejemplos etiquetados escasean, ayudando a obtener vistas detalladas y oportunas de nuestro planeta sin enormes esfuerzos de anotación.
Por qué la IA convencional tropieza con las vistas desde el espacio
La mayoría de los sistemas visión–lenguaje modernos, como CLIP, se entrenan con fotos cotidianas emparejadas con textos breves de la web. Saben mucho sobre gatos, coches y calles, pero mucho menos sobre pistas de aterrizaje, arrozales o polígonos industriales vistos desde cientos de kilómetros de altura. Las imágenes de teledetección difieren en escala, punto de vista y bandas espectrales, y sus etiquetas son caras porque requieren conocimiento experto. Cuando solo hay unos pocos ejemplos disponibles, los métodos estándar de ajuste fino tienden a sobreajustar o a no converger, dejando estos grandes modelos infrautilizados en aplicaciones geoespaciales.
Añadir lenguaje rico a etiquetas escuetas
La primera idea del marco propuesto SatAdapter es “hablar” al modelo de una forma que tenga sentido para los satélites. En lugar de introducir nombres de clase cortos como “aeropuerto” o “bosque”, los autores usan un modelo de lenguaje grande para generar descripciones detalladas de cómo se ve cada clase desde arriba: su textura, formas, patrones y disposición espacial. Varios prompts cuidadosamente diseñados guían al modelo de lenguaje para describir, por ejemplo, cómo se orientan las pistas, cómo se agrupan los edificios o cómo se organizan los campos. Estas descripciones más ricas se convierten en características de texto que dan al modelo visión–lenguaje una imagen mental más clara de cómo debe lucir cada tipo de uso del suelo en las imágenes satelitales.
Proxys: suplantando etiquetas ausentes
El segundo ingrediente reemplaza las etiquetas faltantes por sustitutos calibrados llamados proxys. SatAdapter parte de un codificador de imágenes congelado de CLIP y calcula cómo se relacionan las imágenes satelitales no etiquetadas con las descripciones de clase basadas en lenguaje. A partir de esto, construye vectores de referencia por clase que actúan como clasificadores suaves y aprendidos dentro del espacio compartido imagen–texto. Estos proxys se refinan mediante una optimización offline eficiente que nunca altera el modelo base. Para hacerlos más fiables, el método fusiona las predicciones de dos codificadores complementarios —una red convolucional y un transformador de visión— para que tanto las texturas finas como las disposiciones generales contribuyan. El resultado es un conjunto de pseudoetiquetas confiables que aproximan a las anotaciones humanas sin esfuerzo manual.
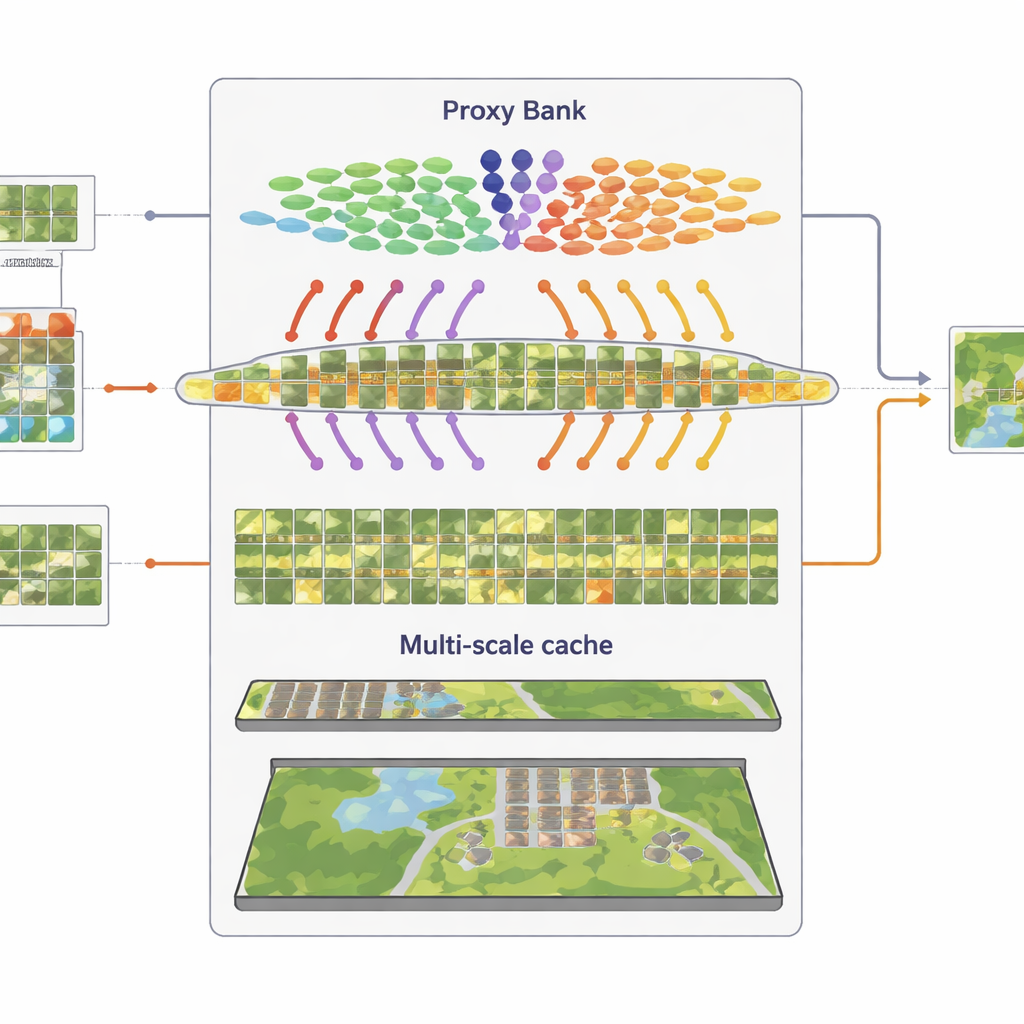
Recordar patrones visuales a múltiples escalas
El tercer componente es una “caché de características” multigranular que recuerda patrones visuales representativos. A partir de las imágenes pseudoetiquetadas con confianza, SatAdapter almacena tanto detalles a nivel de parche como resúmenes de la escena completa como pares clave–valor. Durante la inferencia, cuando llega una nueva imagen, el sistema mide su similitud con esta caché y con las predicciones basadas en proxys, combinándolas con la salida cero-shot original de CLIP. Este sencillo proceso de recuperación y fusión, controlado por unos pocos parámetros de ponderación, permite al modelo reutilizar el conocimiento acumulado sobre texturas, formas y disposiciones vistas en escenas satelitales previas, sin entrenamiento basado en gradientes.
Demostrando la idea en paisajes diversos
Para evaluar SatAdapter, los autores lo prueban en cinco benchmarks satelitales estándar que abarcan campos europeos, ciudades globales, suburbios estadounidenses y escenas urbanas complejas en China, cada uno con distintas resoluciones y categorías de cobertura del suelo. En condiciones zero-shot —donde solo se conocen los nombres de las clases— SatAdapter supera a varias referencias cross-modal líderes, aumentando la precisión top-1 media en casi cinco puntos porcentuales. En escenarios few-shot, con solo 1 a 16 imágenes etiquetadas por clase, también vence a competidores basados en caché que requieren imágenes de soporte etiquetadas. Los estudios de ablación muestran que cada uno de los tres módulos ayuda, pero su combinación —prompts ricos, calibración de proxys y caché multiescala— ofrece las ganancias más grandes y estables a través de backbones y conjuntos de datos.
Qué significa esto para vigilar nuestro mundo cambiante
Para no especialistas, la conclusión clave es que SatAdapter muestra cómo adaptar modelos imagen–lenguaje de propósito general a imágenes satelitales sin el habitual apetito por datos etiquetados. Al enriquecer nombres de clase simples con lenguaje descriptivo, construir clasificadores proxy a partir de escenas no etiquetadas y reciclar patrones visuales mediante una caché de características, el marco convierte un modelo genérico entrenado en la web en una herramienta de teledetección sólida y eficiente con pocos datos. Esto hace más práctico monitorizar el uso del suelo, la infraestructura y los cambios medioambientales a escala, incluso cuando los expertos solo pueden etiquetar una fracción mínima de las imágenes que llegan desde el espacio.
Cita: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Palabras clave: teledetección, modelos visión-lenguaje, aprendizaje con pocos ejemplos, imágenes satelitales, IA geoespacial