Clear Sky Science · pt
Adaptação cross-modal com poucos dados para sensoriamento remoto com cache de características multi-granular aprimorado por proxies
Ensinando satélites a entender a Terra com menos dados
Imagens de satélite são uma mina de ouro para acompanhar o crescimento urbano, monitorar culturas e responder a desastres — mas transformar essas imagens em mapas confiáveis normalmente exige milhares de rótulos humanos meticulosos. Este artigo apresenta uma nova forma de fazer modelos poderosos visão–linguagem funcionarem para dados de satélite mesmo quando exemplos rotulados são escassos, ajudando a liberar visões detalhadas e oportunas do nosso planeta sem esforços massivos de anotação.
Por que a IA comum tem dificuldade com vistas do espaço
A maioria dos sistemas visão–linguagem modernos, como o CLIP, é treinada com fotos do dia a dia pareadas com textos curtos da web. Eles sabem muito sobre gatos, carros e ruas da cidade, mas muito menos sobre pistas, arrozais ou parques industriais vistos a centenas de quilômetros de altitude. Imagens de sensoriamento remoto diferem em escala, ponto de vista e bandas espectrais, e os rótulos para elas são caros porque exigem conhecimento especializado. Quando apenas alguns exemplos estão disponíveis, métodos padrão de fine-tuning tendem a overfit ou a não convergir, deixando esses grandes modelos subutilizados em aplicações geoespaciais.
Adicionando linguagem rica a rótulos enxutos
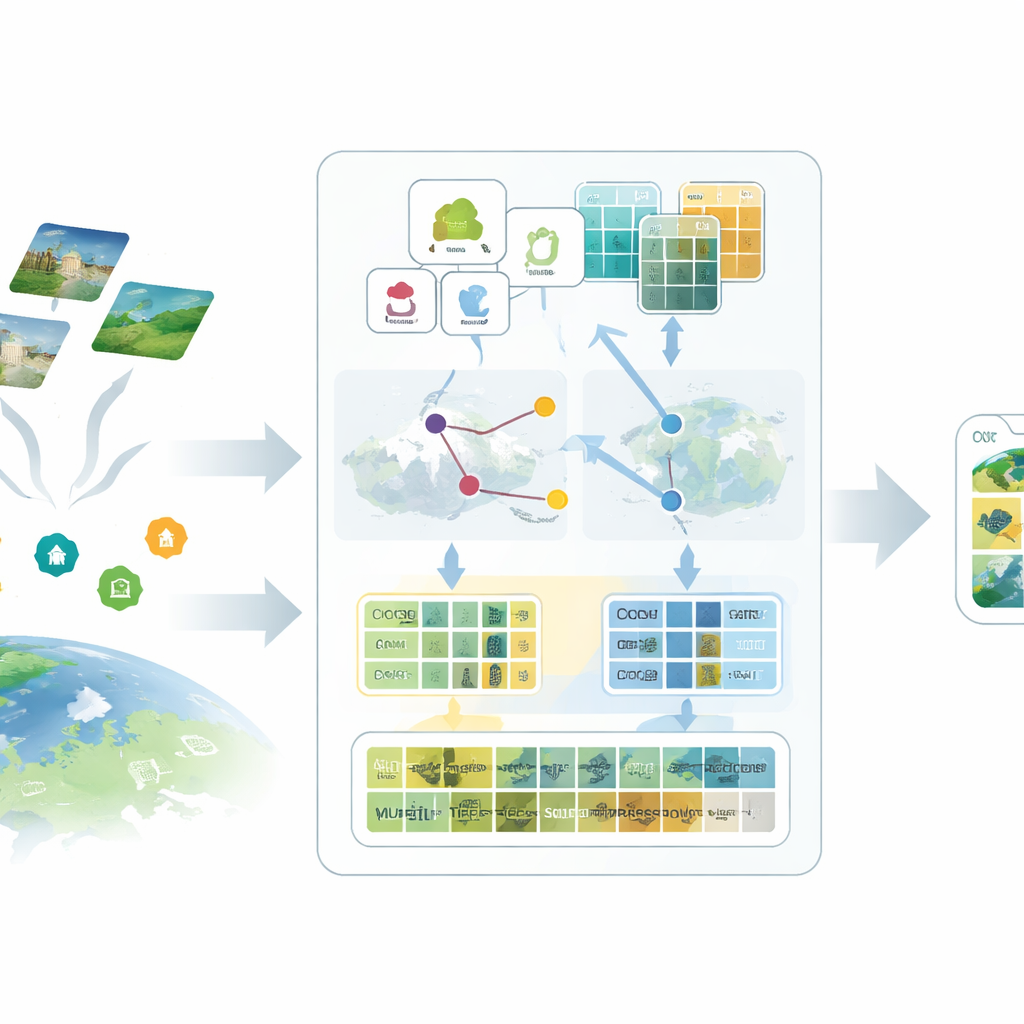
A primeira ideia na estrutura proposta, SatAdapter, é “conversar” com o modelo de uma forma que faça sentido para satélites. Em vez de alimentar nomes de classe curtos como “aeroporto” ou “floresta”, os autores usam um grande modelo de linguagem para produzir descrições detalhadas de como cada classe aparece vista de cima — sua textura, formas, padrões e distribuição espacial. Vários prompts de pergunta cuidadosamente projetados guiam o modelo de linguagem a descrever, por exemplo, como as pistas se alinham, como os edifícios se agrupam ou como os campos são organizados. Essas descrições mais ricas são convertidas em características de texto que dão ao modelo visão–linguagem uma imagem mental mais clara de como cada tipo de uso do solo deve aparecer em imagens de satélite.
Proxies: substitutos para rótulos ausentes
O segundo ingrediente substitui rótulos ausentes por substitutos calibrados chamados proxies. O SatAdapter começa com um codificador de imagem congelado do CLIP e calcula como imagens de satélite não rotuladas se relacionam com as descrições de classe baseadas em linguagem. A partir disso, constrói vetores de referência por classe que atuam como classificadores suaves e aprendidos dentro do espaço compartilhado imagem–texto. Esses proxies são refinados por meio de uma otimização offline eficiente que nunca altera a espinha dorsal do modelo. Para torná-los mais confiáveis, o método funde previsões de dois codificadores complementares — uma rede convolucional e um vision transformer — de forma que tanto texturas finas quanto disposições amplas contribuam. O resultado é um conjunto de pseudo-rótulos confiáveis que aproximam anotações humanas sem esforço manual.
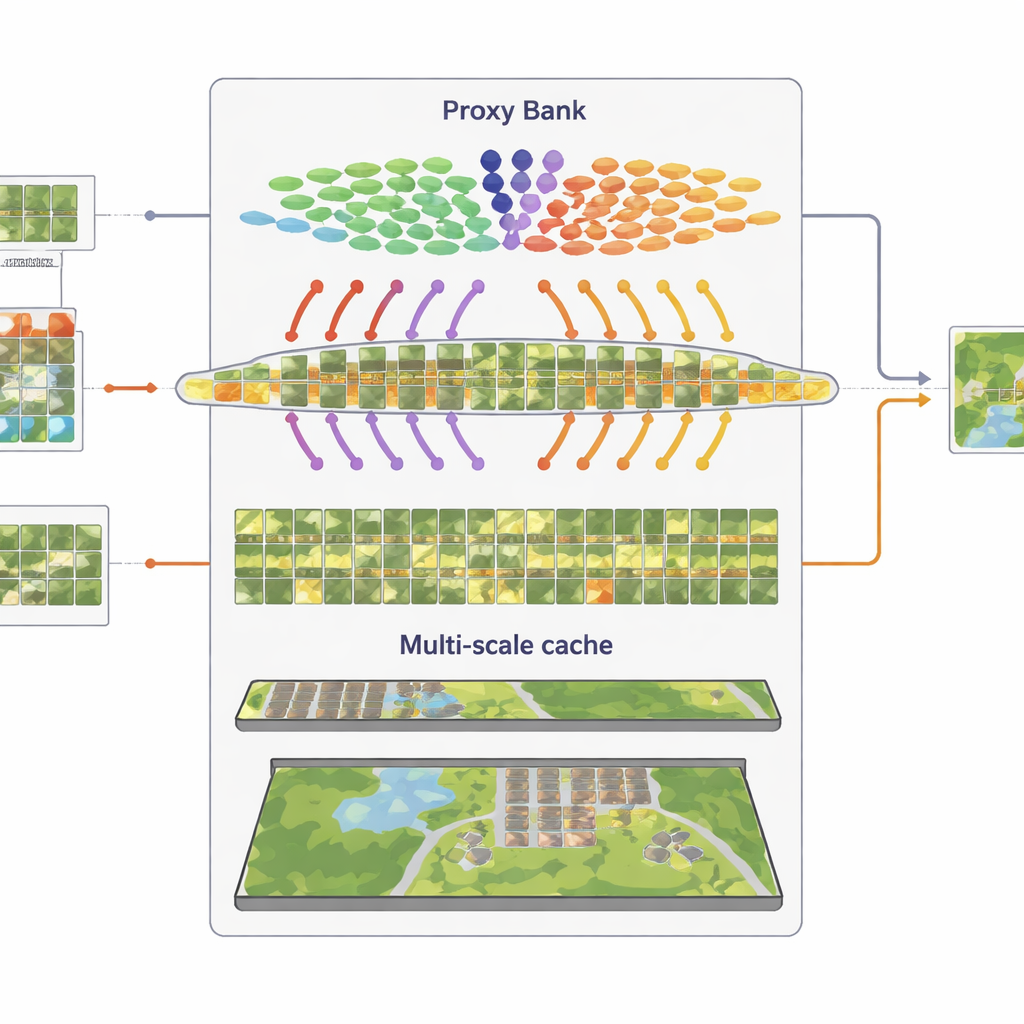
Lembrando padrões visuais em múltiplas escalas
O terceiro componente é um “cache de características” multi-granular que recorda padrões visuais representativos. A partir das imagens pseudo-rotuladas com alta confiança, o SatAdapter armazena tanto detalhes em nível de bloco quanto resumos de cena inteira como pares chave–valor. Durante a inferência, quando chega uma nova imagem, o sistema mede sua similaridade com esse cache e com as previsões baseadas em proxies, combinando-os com a saída zero-shot original do CLIP. Esse processo simples de recuperação e fusão, controlado por alguns parâmetros de ponderação, permite que o modelo reutilize conhecimento acumulado sobre texturas, formas e layouts vistos em cenas de satélite anteriores — sem qualquer treinamento baseado em gradiente.
Provando a ideia em paisagens diversas
Para testar o SatAdapter, os autores o avaliam em cinco benchmarks padrão de satélite que abrangem fazendas europeias, cidades globais, subúrbios dos EUA e cenas urbanas complexas da China, cada um com diferentes resoluções e categorias de cobertura do solo. Em condições zero-shot — onde apenas os nomes das classes são conhecidos — o SatAdapter supera vários baselines cross-modal de ponta, elevando a acurácia top-1 média em quase cinco pontos percentuais. Em cenários few-shot, com apenas 1 a 16 imagens rotuladas por classe, ele também supera concorrentes baseados em cache que exigem imagens de suporte rotuladas. Estudos de ablação mostram que cada um dos três módulos contribui, mas sua combinação — prompts ricos, calibração de proxies e cache multi-escala — entrega os ganhos mais amplos e estáveis entre backbones e conjuntos de dados.
O que isso significa para monitorar nosso mundo em mudança
Para não especialistas, a principal conclusão é que o SatAdapter demonstra como adaptar IA visão–linguagem de uso geral para imagens de satélite sem o apetite usual por dados rotulados. Ao enriquecer nomes de classe simples com linguagem descritiva, construir classificadores proxy a partir de cenas não rotuladas e reciclar padrões visuais por meio de um cache de características, a estrutura transforma um modelo genérico treinado na web em uma ferramenta robusta de sensoriamento remoto com poucos dados. Isso torna mais prático monitorar uso do solo, infraestrutura e mudanças ambientais em escala, mesmo quando especialistas podem rotular apenas uma fração ínfima das imagens que chegam do espaço.
Citação: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Palavras-chave: sensoriamento remoto, modelos visão-linguagem, aprendizado com poucos exemplos, imagens de satélite, IA geoespacial