Clear Sky Science · it
Adattamento cross-modale a basso consumo di dati per telerilevamento con caching di caratteristiche multi-granularità migliorato tramite proxy
Insegnare ai satelliti a comprendere la Terra con meno dati
Le immagini satellitari sono una miniera d’oro per tracciare l’espansione urbana, monitorare le colture e rispondere alle catastrofi, ma trasformare quelle immagini in mappe affidabili di solito richiede migliaia di etichette create a mano. Questo articolo presenta un nuovo modo per far funzionare potenti modelli immagine–linguaggio sui dati satellitari anche quando gli esempi etichettati sono scarsi, contribuendo a sbloccare viste tempestive e dettagliate del nostro pianeta senza grandi sforzi di annotazione.
Perché l’IA convenzionale fatica con le viste dallo spazio
La maggior parte dei moderni sistemi visione–linguaggio, come CLIP, sono addestrati su foto di uso quotidiano abbinate a brevi testi presi dal web. Sanno molto su gatti, automobili e strade cittadine, ma molto meno su piste di atterraggio, risaie o poli industriali osservati da centinaia di chilometri di distanza. Le immagini di telerilevamento si differenziano per scala, punto di vista e bande spettrali, e le etichette per esse sono costose perché richiedono competenze specialistiche. Quando sono disponibili solo pochi esempi, i metodi di fine-tuning standard tendono a sovra-adattarsi o a non convergere, lasciando questi grandi modelli sottoutilizzati nelle applicazioni geospaziali.
Aggiungere linguaggio ricco a etichette scarne
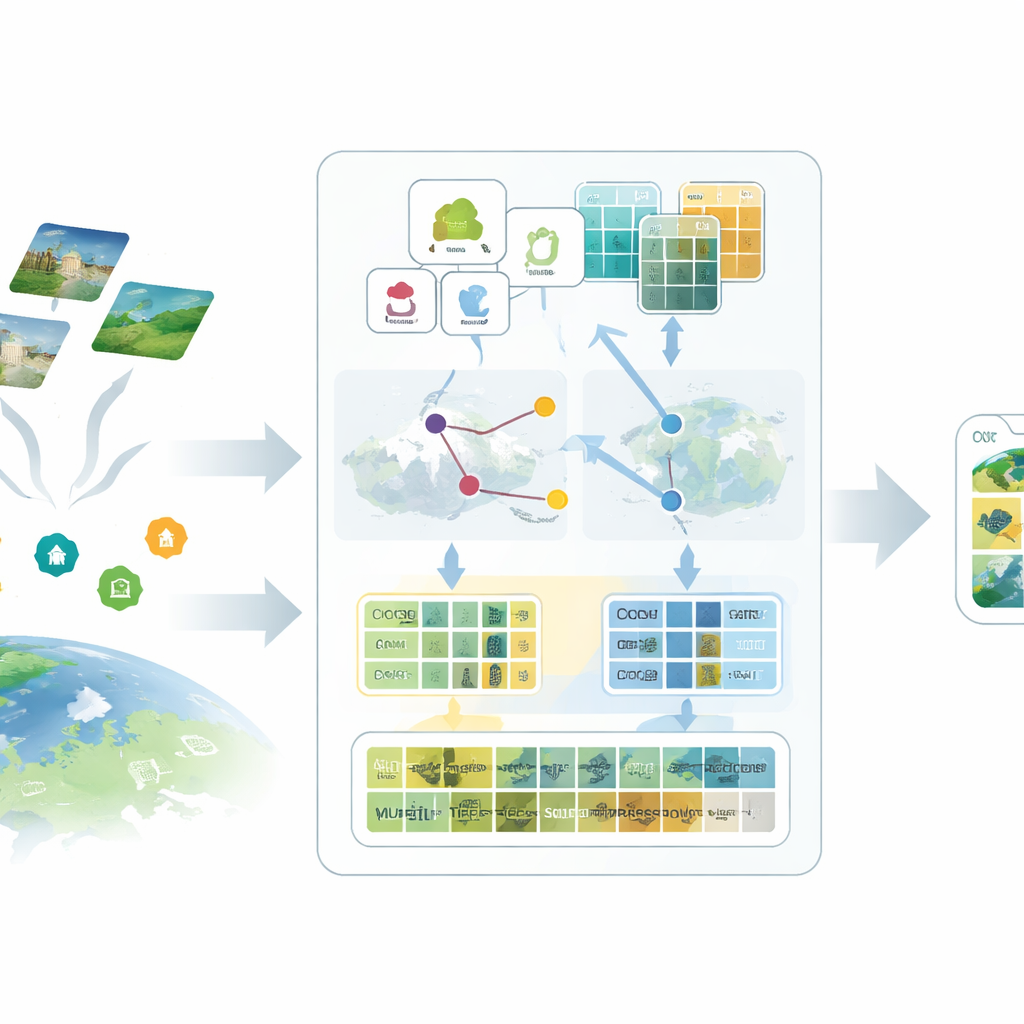
La prima idea del framework proposto, SatAdapter, è “parlare” al modello in modo sensato per i satelliti. Invece di fornire brevi nomi di classe come “aeroporto” o “foresta”, gli autori usano un grande modello linguistico per produrre descrizioni dettagliate di come ogni classe appare dall’alto — la sua texture, le forme, i pattern e la disposizione spaziale. Diversi prompt progettati con cura guidano il modello linguistico a descrivere, per esempio, l’allineamento delle piste, il raggruppamento degli edifici o l’ordinamento dei campi. Queste descrizioni più ricche vengono convertite in feature testuali che danno al modello visione–linguaggio un quadro più chiaro di come dovrebbe apparire ogni tipo di uso del suolo nelle immagini satellitari.
Proxy: sostituti per le etichette mancanti
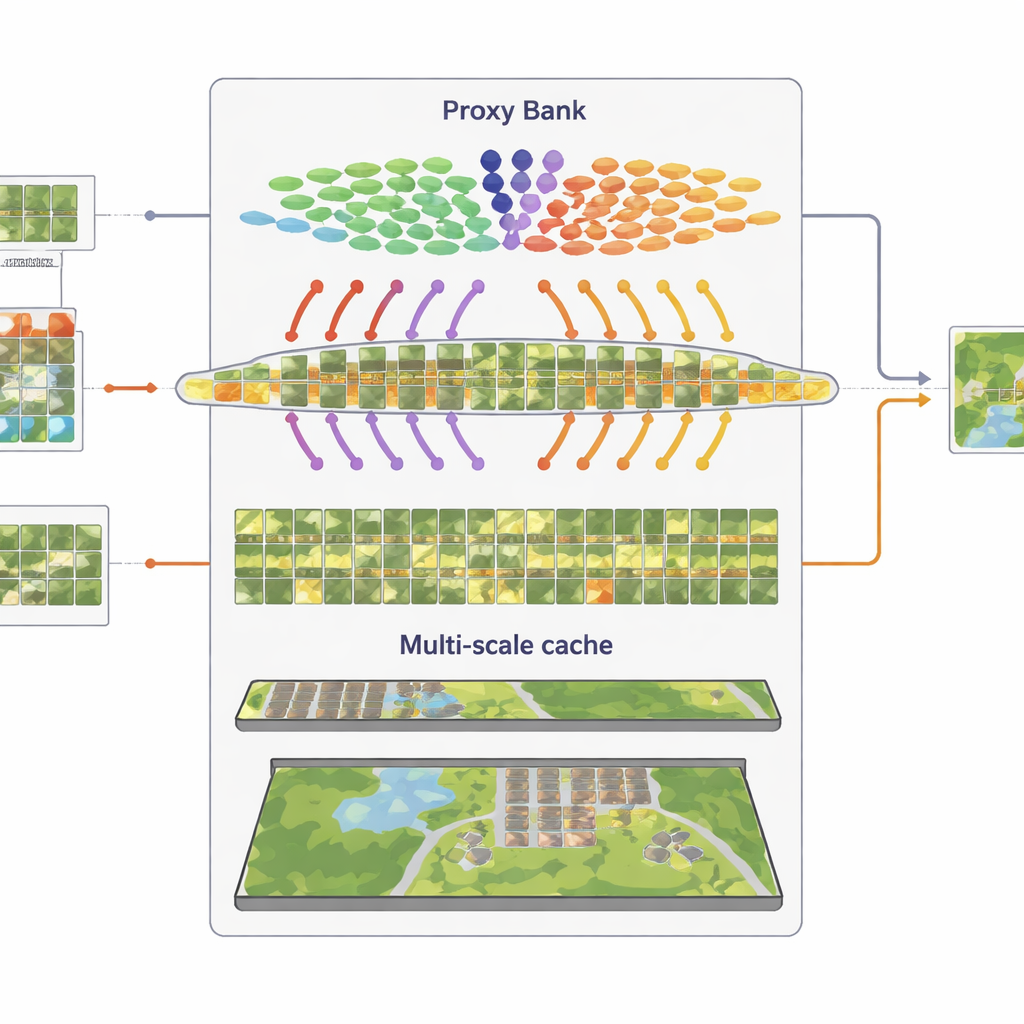
Il secondo ingrediente sostituisce le etichette mancanti con surrogati calibrati chiamati proxy. SatAdapter parte da un encoder immagine congelato di CLIP e calcola come le immagini satellitari non etichettate si relazionano alle descrizioni di classe basate sul linguaggio. Da questo costruisce vettori di riferimento per classe che agiscono come classificatori morbidi e appresi all’interno dello spazio condiviso immagine–testo. Questi proxy vengono raffinati tramite un’ottimizzazione offline efficiente che non modifica mai il backbone del modello. Per renderli più affidabili, il metodo fonde le previsioni di due encoder complementari — una rete convoluzionale e un vision transformer — in modo che sia le texture fini sia le disposizioni ampie contribuiscano. Il risultato è un insieme di pseudo-etichettature fiduciose che approssimano le annotazioni umane senza sforzo manuale.
Ricordare i pattern visivi a più scale
Il terzo componente è una “cache di caratteristiche” multi-granularità che memorizza pattern visivi rappresentativi. Dalle immagini pseudo-etichettate con confidenza, SatAdapter conserva sia dettagli a livello di patch sia sommari dell’intera scena come coppie chiave–valore. Durante l’inferenza, quando arriva una nuova immagine, il sistema misura la sua similarità rispetto a questa cache e alle previsioni basate sui proxy, combinandole con l’output zero-shot originale di CLIP. Questo semplice processo di recupero e fusione, controllato da pochi parametri di pesatura, permette al modello di riutilizzare conoscenze accumulate su texture, forme e disposizioni viste in scene satellitari precedenti — senza alcun addestramento basato su gradienti.
Dimostrare l’idea su paesaggi diversi
Per testare SatAdapter, gli autori lo valutano su cinque benchmark satellitari standard che coprono terreni agricoli europei, città globali, sobborghi statunitensi e complesse aree urbane cinesi, ciascuno con risoluzioni e categorie di copertura del suolo diverse. In condizioni zero-shot — dove sono noti solo i nomi delle classi — SatAdapter supera diversi baselines cross-modali di rilievo, aumentando l’accuratezza top-1 media di quasi cinque punti percentuali. In impostazioni few-shot, con solo 1 a 16 immagini etichettate per classe, batte anche i concorrenti basati su cache che richiedono immagini di supporto etichettate. Gli studi di ablazione mostrano che ciascuno dei tre moduli contribuisce, ma la loro combinazione — prompt ricchi, calibrazione dei proxy e caching multi-scala — fornisce i guadagni maggiori e più stabili attraverso backbone e dataset.
Cosa significa per il monitoraggio del nostro mondo in cambiamento
Per i non specialisti, la conclusione principale è che SatAdapter mostra come adattare modelli immagine–linguaggio di uso generale alle immagini satellitari senza l’usuale bisogno massiccio di dati etichettati. Arricchendo i semplici nomi di classe con linguaggio descrittivo, costruendo classificatori proxy da scene non etichettate e riciclando pattern visivi attraverso una cache di caratteristiche, il framework trasforma un modello generico addestrato sul web in uno strumento di telerilevamento robusto e a basso consumo di dati. Questo rende più pratico monitorare l’uso del suolo, le infrastrutture e i cambiamenti ambientali su larga scala, anche quando gli esperti possono etichettare solo una frazione minima delle immagini trasmesse dallo spazio.
Citazione: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Parole chiave: telerilevamento, modelli visione-linguaggio, apprendimento few-shot, immagini satellitari, IA geospaziale