Clear Sky Science · fr
Adaptation croisée faible-données pour la télédétection avec mise en cache de caractéristiques multi-granularité enrichie par proxys
Apprendre aux satellites à comprendre la Terre avec moins de données
Les images satellites sont une mine d’or pour suivre l’expansion urbaine, surveiller les cultures et répondre aux catastrophes — mais transformer ces images en cartes fiables exige généralement des milliers d’annotations humaines laborieuses. Cet article présente une nouvelle approche pour adapter des modèles puissants image–texte aux données satellite même lorsque les exemples annotés sont rares, ce qui permet d’obtenir des vues détaillées et opportunes de notre planète sans efforts massifs d’annotation.
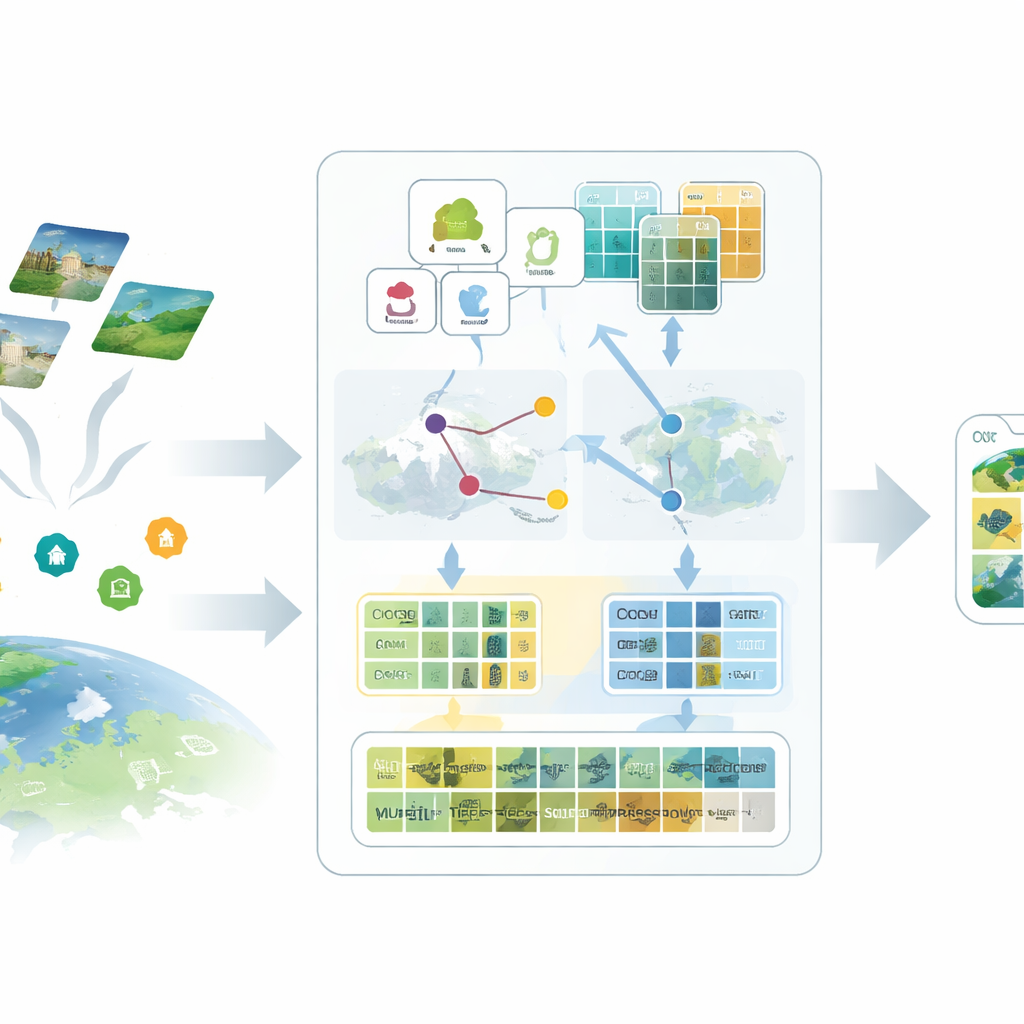
Pourquoi l’IA classique peine avec les vues spatiales
La plupart des systèmes vision–langage modernes, comme CLIP, sont entraînés sur des photos quotidiennes associées à de courts textes issus du web. Ils connaissent beaucoup de choses sur les chats, les voitures et les rues de ville, mais bien moins sur les pistes d’atterrissage, les rizières ou les zones industrielles vues à des centaines de kilomètres d’altitude. Les images de télédétection diffèrent par l’échelle, le point de vue et les bandes spectrales, et leurs étiquettes sont coûteuses car elles exigent une expertise. Quand seuls quelques exemples sont disponibles, les méthodes classiques de fine-tuning ont tendance à surapprendre ou à ne pas converger, laissant ces grands modèles sous-utilisés dans les applications géospatiales.
Ajouter du langage riche à des étiquettes sommaires
La première idée du cadre proposé SatAdapter est de « parler » au modèle d’une manière adaptée aux images satellite. Au lieu d’entrer de courts noms de classes comme « aéroport » ou « forêt », les auteurs utilisent un grand modèle de langage pour produire des descriptions détaillées de l’apparence de chaque classe vue d’en haut — textures, formes, motifs et agencements spatiaux. Plusieurs invites (prompts) soigneusement conçues guident le modèle de langage pour décrire, par exemple, l’alignement des pistes, le regroupement des bâtiments ou l’organisation des parcelles. Ces descriptions enrichies sont converties en caractéristiques textuelles qui donnent au modèle vision–langage une image mentale plus claire de ce à quoi chaque type d’occupation du sol doit ressembler en imagerie satellite.
Des proxys : remplacer les étiquettes manquantes
Le second ingrédient remplace les étiquettes manquantes par des substituts calibrés appelés proxys. SatAdapter démarre avec un encodeur d’image gelé issu de CLIP et calcule comment les images satellite non étiquetées se rapportent aux descriptions de classes basées sur le langage. À partir de cela, il construit des vecteurs de référence par classe qui agissent comme des classifieurs souples, appris, dans l’espace image–texte partagé. Ces proxys sont raffinés via une optimisation hors ligne efficace qui n’altère jamais le modèle de base. Pour les rendre plus fiables, la méthode fusionne les prédictions de deux encodeurs complémentaires — un réseau convolutionnel et un vision transformer — de sorte que textures fines et agencements larges contribuent tous deux. Le résultat est un ensemble de pseudo-étiquettes confiantes qui approchent les annotations humaines sans travail manuel.
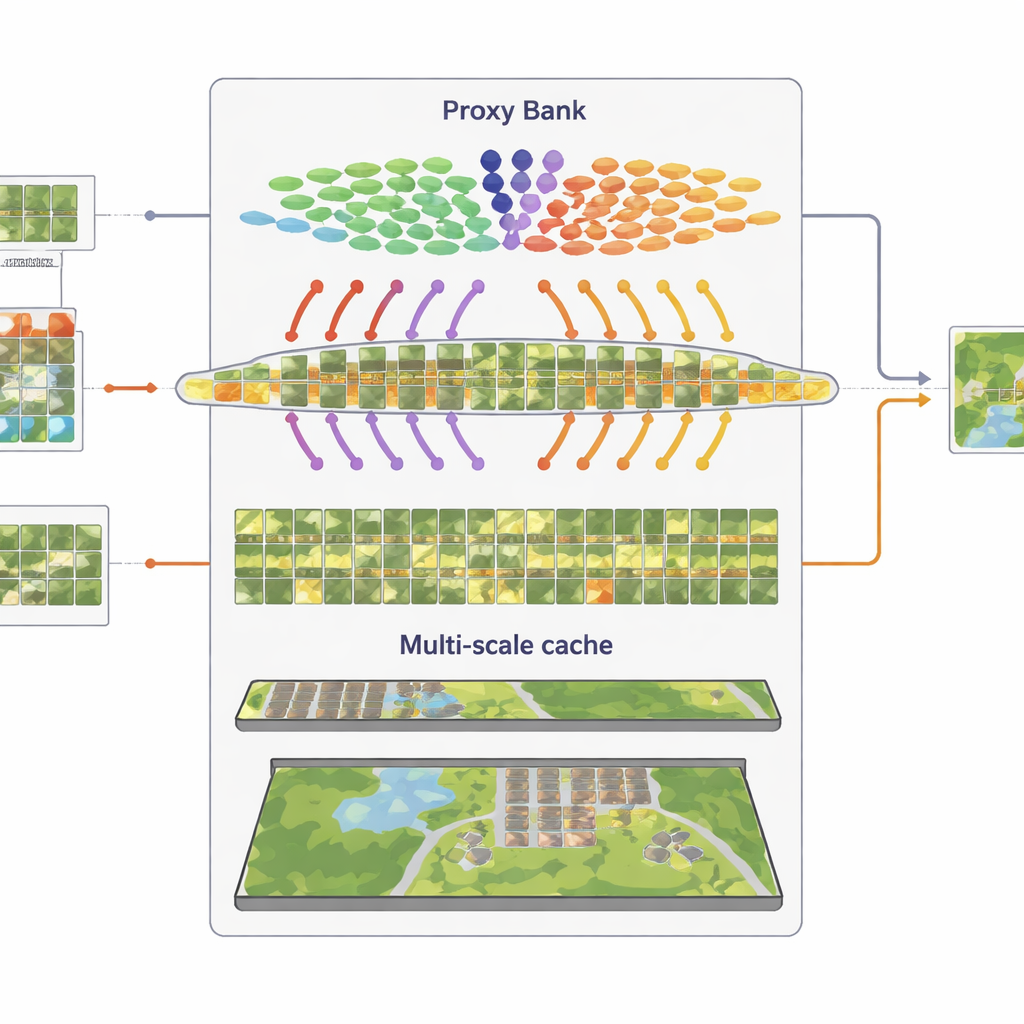
Mémoriser les motifs visuels à plusieurs échelles
Le troisième composant est une « cache de caractéristiques » multi-granularité qui mémorise des motifs visuels représentatifs. À partir des images pseudo-étiquetées de manière confiante, SatAdapter stocke à la fois des détails au niveau des patches et des résumés de la scène entière sous forme de paires clé–valeur. Lors de l’inférence, quand une nouvelle image arrive, le système mesure sa similarité avec cette cache et avec les prédictions basées sur les proxys, en les combinant avec la sortie zéro-shot originale de CLIP. Ce processus simple de recherche et de fusion, contrôlé par quelques paramètres de pondération, permet au modèle de réutiliser les connaissances accumulées sur les textures, les formes et les agencements observés dans des scènes satellite précédentes — sans aucun entraînement par gradient.
Valider l’approche sur des paysages variés
Pour tester SatAdapter, les auteurs l’évaluent sur cinq benchmarks satellite standard couvrant des terres agricoles européennes, des villes mondiales, des banlieues américaines et des scènes urbaines chinoises complexes, chacune avec des résolutions et des catégories de couverture du sol différentes. En conditions zéro-shot — où seuls les noms de classes sont connus — SatAdapter dépasse plusieurs références cross-modales de pointe, augmentant l’exactitude top-1 moyenne d’environ cinq points de pourcentage. En configuration few-shot, avec seulement 1 à 16 images annotées par classe, il surpasse aussi des concurrents basés sur la mise en cache qui nécessitent des images de support étiquetées. Des études d’ablation montrent que chacun des trois modules apporte un bénéfice, mais leur combinaison — prompts riches, calibration des proxys et mise en cache multi-échelle — fournit les gains les plus importants et les plus stables à travers les architectures et les jeux de données.
Ce que cela signifie pour la surveillance de notre monde en mutation
Pour les non-spécialistes, l’idée principale est que SatAdapter montre comment adapter une IA image–texte à usage général à l’imagerie satellite sans l’appétit habituel pour les données étiquetées. En enrichissant de simples noms de classes par un langage descriptif, en construisant des classifieurs proxies à partir de scènes non étiquetées et en réutilisant des motifs visuels via une cache de caractéristiques, le cadre transforme un modèle générique entraîné sur le web en un outil de télédétection performant en faible-données. Cela rend plus pratique la surveillance de l’utilisation des sols, des infrastructures et des changements environnementaux à grande échelle, même lorsque les experts ne peuvent annoter qu’une infime fraction des images qui descendent de l’espace.
Citation: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Mots-clés: télédétection, modèles vision-langage, apprentissage en quelques coups, imagerie satellite, IA géospatiale