Clear Sky Science · de
Low-Data Cross-Modal-Anpassung für Fernerkundung mit proxy-verstärktem Multi-Granularitäts-Feature-Cache
Satelliten beibringen, die Erde mit weniger Daten zu verstehen
Satellitenbilder sind eine Fundgrube, um Stadtwachstum zu verfolgen, Ernten zu überwachen und auf Katastrophen zu reagieren — doch aus diesen Bildern verlässliche Karten zu machen, erfordert meist tausende mühsamer menschlicher Labels. Dieses Paper stellt eine neue Methode vor, die leistungsfähige Bild–Text-KI-Modelle für Satellitendaten nutzbar macht, auch wenn nur wenige gelabelte Beispiele vorliegen. So lassen sich zeitnahe, detaillierte Einblicke in unseren Planeten gewinnen, ohne massive Annotationsaufwände.
Warum normale KI bei Aufnahmen aus dem All scheitert
Die meisten modernen Vision–Language-Systeme, etwa CLIP, werden auf Alltagsfotos mit kurzen Web-Texten trainiert. Sie wissen viel über Katzen, Autos und Straßenszenen, aber deutlich weniger über Start- und Landebahnen, Reisfelder oder Industrieparks, die aus Hunderten Kilometern Höhe abgebildet sind. Fernerkundungsbilder unterscheiden sich hinsichtlich Maßstab, Blickwinkel und spektralen Bändern, und Labels sind teuer, weil Expertenwissen nötig ist. Bei nur wenigen Beispielen neigen Standard-Finetuning-Verfahren zum Überanpassen oder konvergieren nicht, sodass diese großen Modelle in geospatialen Anwendungen untergenutzt bleiben.
Reiche Sprache statt knapper Labels
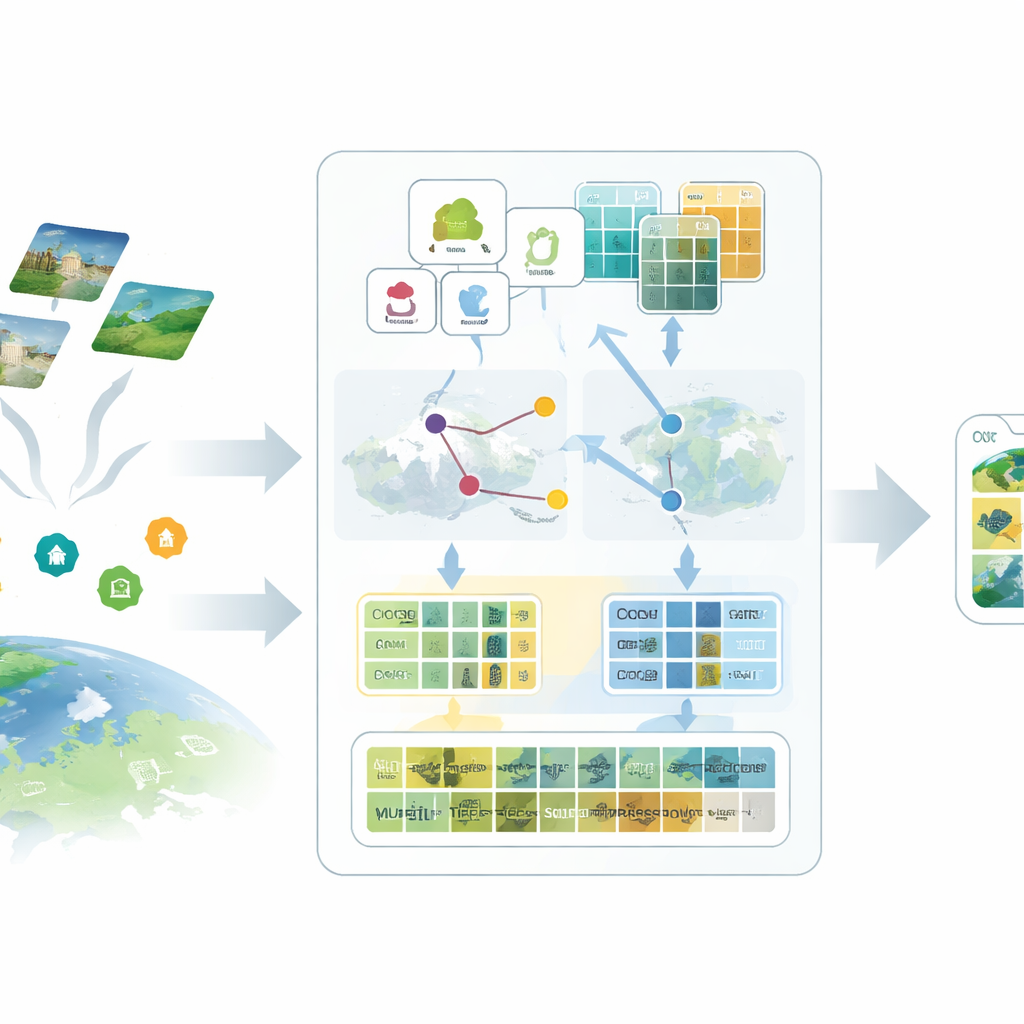
Die erste Idee im vorgeschlagenen SatAdapter-Framework ist, das Modell so „anzusprechen“, dass es für Satellitenaufnahmen sinnvoll ist. Anstatt kurze Klassennamen wie „Flughafen“ oder „Wald“ zu verwenden, erzeugen die Autoren mit einem großen Sprachmodell detaillierte Beschreibungen, wie jede Klasse von oben aussieht — Texturen, Formen, Muster und räumliche Anordnungen. Mehrere sorgfältig entworfene Prompt-Fragen leiten das Sprachmodell dazu, etwa zu beschreiben, wie Startbahnen ausgerichtet sind, wie Gebäudecluster auftreten oder wie Felder strukturiert sind. Diese reicheren Beschreibungen werden in Textfeature umgewandelt, die dem Vision–Language-Modell ein klareres mentales Bild davon geben, wie jede Landnutzungsart in Satellitenbildern aussehen sollte.
Proxies: Ersatz für fehlende Labels
Die zweite Zutat ersetzt fehlende Labels durch sorgfältig kalibrierte Stellvertreter, sogenannte Proxies. SatAdapter beginnt mit einem eingefrorenen Bildencoder von CLIP und berechnet, wie unlabeled Satellitenbilder zu den sprachbasierten Klassentexten stehen. Daraus baut es klassenweise Referenzvektoren auf, die wie weiche, gelernte Klassifizierer im gemeinsamen Bild-Text-Raum fungieren. Diese Proxies werden durch eine effiziente Offline-Optimierung verfeinert, die das Backbone-Modell nie verändert. Um sie verlässlicher zu machen, fusioniert die Methode Vorhersagen aus zwei komplementären Encodern — einem konvolutionalen Netzwerk und einem Vision-Transformer — sodass sowohl feine Texturen als auch breite Layouts einfließen. Das Ergebnis sind selbstbewusste Pseudo-Labels, die menschliche Annotationen ohne manuellen Aufwand approximieren.
Visuelle Muster in mehreren Skalen behalten
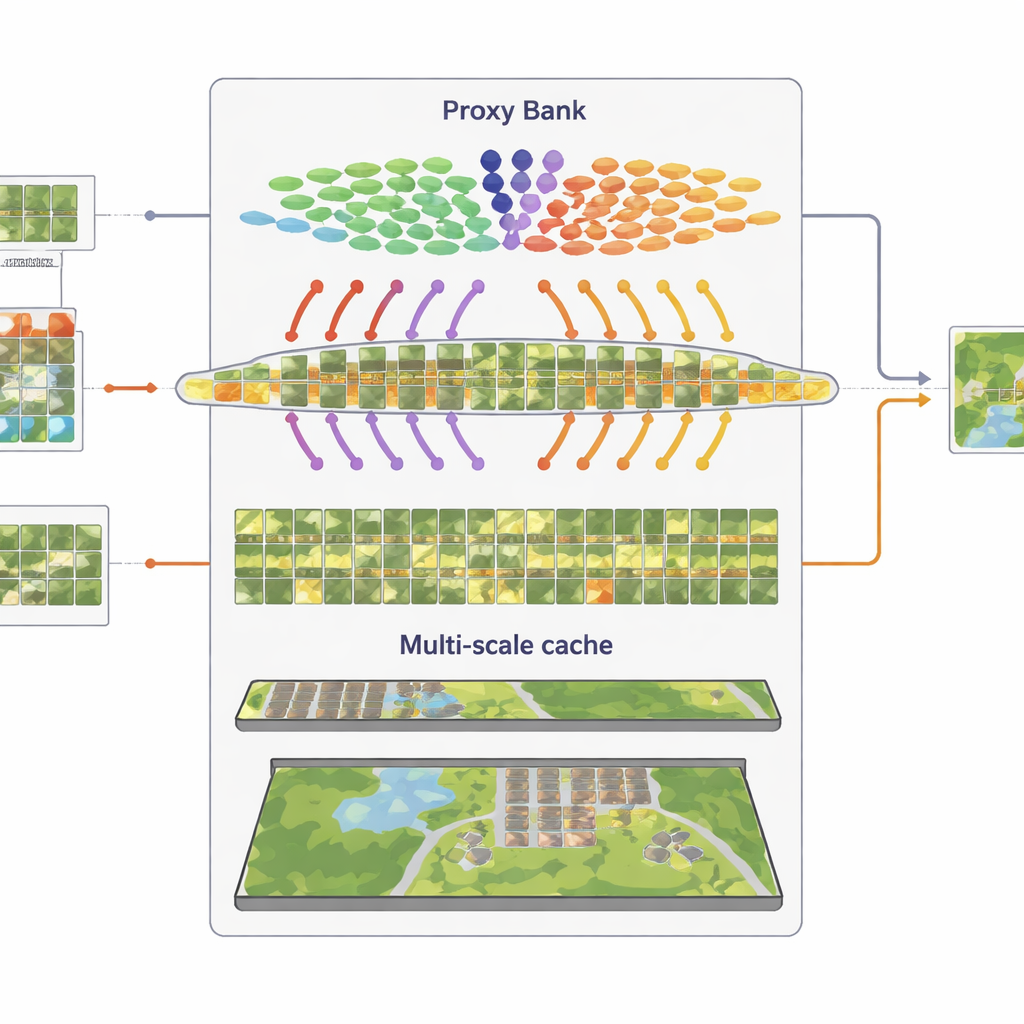
Die dritte Komponente ist ein Multi-Granularitäts-„Feature-Cache“, der repräsentative visuelle Muster speichert. Aus den mit hoher Zuversicht pseudo-gelabelten Bildern legt SatAdapter sowohl Patch-Ebene-Details als auch Ganz-Szene-Zusammenfassungen als Schlüssel-Wert-Paare ab. Während der Inferenz misst das System bei einem neuen Bild die Ähnlichkeit zu diesem Cache und zu den proxy-basierten Vorhersagen und kombiniert diese mit der ursprünglichen Zero-Shot-CLIP-Ausgabe. Dieser einfache Retrieval-und-Fusion-Prozess, gesteuert von einigen Gewichtungsparametern, erlaubt dem Modell, angesammeltes Wissen über Texturen, Formen und Layouts aus früheren Satellitenszenen wiederzuverwenden — ganz ohne gradientenbasiertes Training.
Die Idee über verschiedene Landschaften hinweg beweisen
Um SatAdapter zu testen, evaluieren die Autoren ihn auf fünf standardisierten Satelliten-Benchmarks, die europäische Agrarflächen, globale Städte, US-Vororte und komplexe chinesische Stadtbilder abdecken — jeweils mit unterschiedlichen Auflösungen und Landbedeckungskategorien. Unter Zero-Shot-Bedingungen — bei denen nur Klassennamen bekannt sind — übertrifft SatAdapter mehrere führende cross-modale Baselines und erhöht die durchschnittliche Top-1-Accuracy um nahezu fünf Prozentpunkte. In Few-Shot-Szenarien, mit nur 1 bis 16 gelabelten Bildern pro Klasse, schlägt er auch cache-basierte Konkurrenten, die gelabelte Support-Bilder benötigen. Ablationsstudien zeigen, dass alle drei Module beitragen, aber ihre Kombination — reiche Prompts, Proxy-Kalibrierung und Multi-Skalen-Caching — die größten und stabilsten Verbesserungen über Backbones und Datensätze liefert.
Was das bedeutet für die Beobachtung unserer sich wandelnden Welt
Für Nicht-Spezialisten ist die zentrale Erkenntnis, dass SatAdapter zeigt, wie sich generalistische Bild–Text-KI ohne großen Bedarf an gelabelten Daten an Satellitenbilder anpassen lässt. Indem einfache Klassennamen mit beschreibender Sprache angereichert, Proxy-Klassifizierer aus unlabeled Szenen konstruiert und visuelle Muster über einen Feature-Cache wiederverwendet werden, verwandelt das Framework ein generisches, web-trainiertes Modell in ein leistungsfähiges Low-Data-Fernerkundungswerkzeug. Damit wird es praktischer, Landnutzung, Infrastruktur und Umweltveränderungen in großem Maßstab zu überwachen, selbst wenn Experten nur einen winzigen Bruchteil der von der Raumfahrt gelieferten Bilder annotieren können.
Zitation: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Schlüsselwörter: Fernerkundung, Vision-Language-Modelle, Few-Shot-Lernen, Satellitenbilder, GeoAI