Clear Sky Science · nl
Weinig-gegevens cross-modale aanpassing voor remote sensing met proxy-verrijkte multi-granulariteits feature-caching
Satellieten leren de aarde te begrijpen met minder data
Satellietbeelden zijn een goudmijn voor het volgen van stedelijke groei, het monitoren van gewassen en het reageren op rampen — maar het omzetten van die beelden in betrouwbare kaarten vraagt meestal om duizenden nauwkeurige menselijke labels. Dit artikel introduceert een nieuwe manier om krachtige beeld–taal AI-modellen toepasbaar te maken op satellietdata, ook wanneer gelabelde voorbeelden schaars zijn, en helpt zo om tijdige, gedetailleerde beelden van onze planeet vrij te maken zonder enorme annotatie-inspanningen.
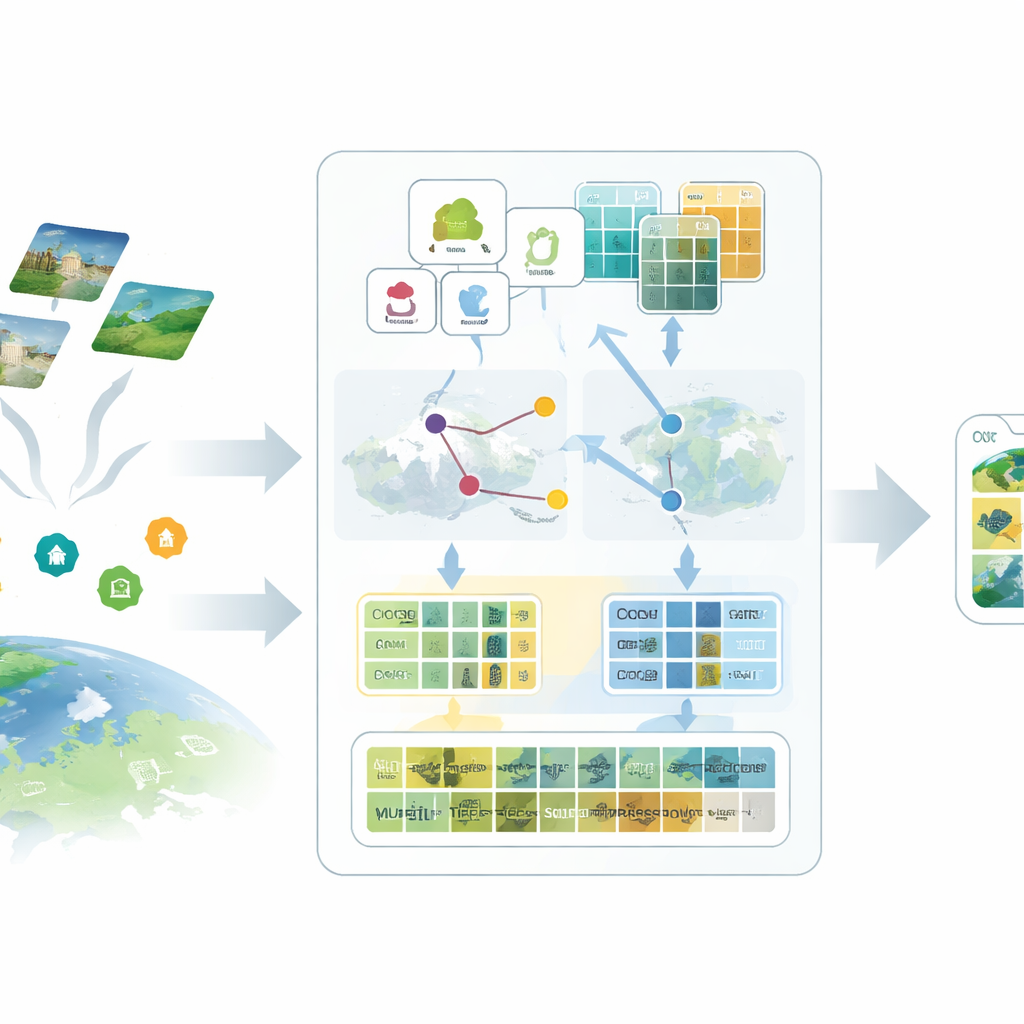
Waarom reguliere AI moeite heeft met beelden vanuit de ruimte
De meeste moderne vision–language systemen, zoals CLIP, zijn getraind op alledaagse foto’s gecombineerd met korte teksten van het web. Ze weten veel over katten, auto’s en stadsstraten, maar veel minder over start- en landingsbanen, rijstvelden of industrieterreinen gezien vanaf honderden kilometers hoogte. Remote sensing-beelden verschillen in schaal, aanzicht en spectrale banden, en labels voor deze beelden zijn duur omdat ze deskundige kennis vereisen. Als er maar een paar voorbeelden beschikbaar zijn, hebben standaard fine-tuning methoden de neiging te overfitten of niet te convergeren, waardoor deze grote modellen onderbenut blijven in geospatiale toepassingen.
Rijke taal toevoegen aan eenvoudige labels
Het eerste idee in het voorgestelde SatAdapter-framework is om het model op een manier aan te spreken die logisch is voor satellieten. In plaats van korte klassennamen zoals “luchthaven” of “bos” in te voeren, gebruiken de auteurs een groot taalmodel om gedetailleerde beschrijvingen te genereren van hoe elke klasse er van boven uitziet — de textuur, vormen, patronen en ruimtelijke indeling. Meerdere zorgvuldig ontworpen promptvragen sturen het taalmodel om bijvoorbeeld te beschrijven hoe startbanen liggen, hoe gebouwen clusteren of hoe velden gerangschikt zijn. Deze rijkere beschrijvingen worden omgezet in tekstkenmerken die het vision–language model een helder mentaal beeld geven van hoe elk type landgebruik in satellietbeelden zou moeten verschijnen.
Proxy’s: invallen voor ontbrekende labels
Het tweede ingrediënt vervangt ontbrekende labels door zorgvuldig gekalibreerde plaatsvervangers die proxy’s worden genoemd. SatAdapter begint met een bevroren image-encoder van CLIP en berekent hoe ongeëtiketteerde satellietbeelden zich verhouden tot de op taal gebaseerde klasseschrijvingen. Daaruit bouwt het klassegewijze referentievektoren die functioneren als zachte, geleerde klassificeerders binnen de gedeelde beeld–tekst ruimte. Deze proxy’s worden verfijnd via een efficiënte offline optimalisatie die de backbone van het model nooit wijzigt. Om ze betrouwbaarder te maken, fuseert de methode voorspellingen van twee complementaire encoders — een convolutioneel netwerk en een vision transformer — zodat zowel fijne texturen als brede indelingen bijdragen. Het resultaat is een set zelfverzekerde pseudo-labels die menselijke annotaties benaderen zonder handmatige inspanning.
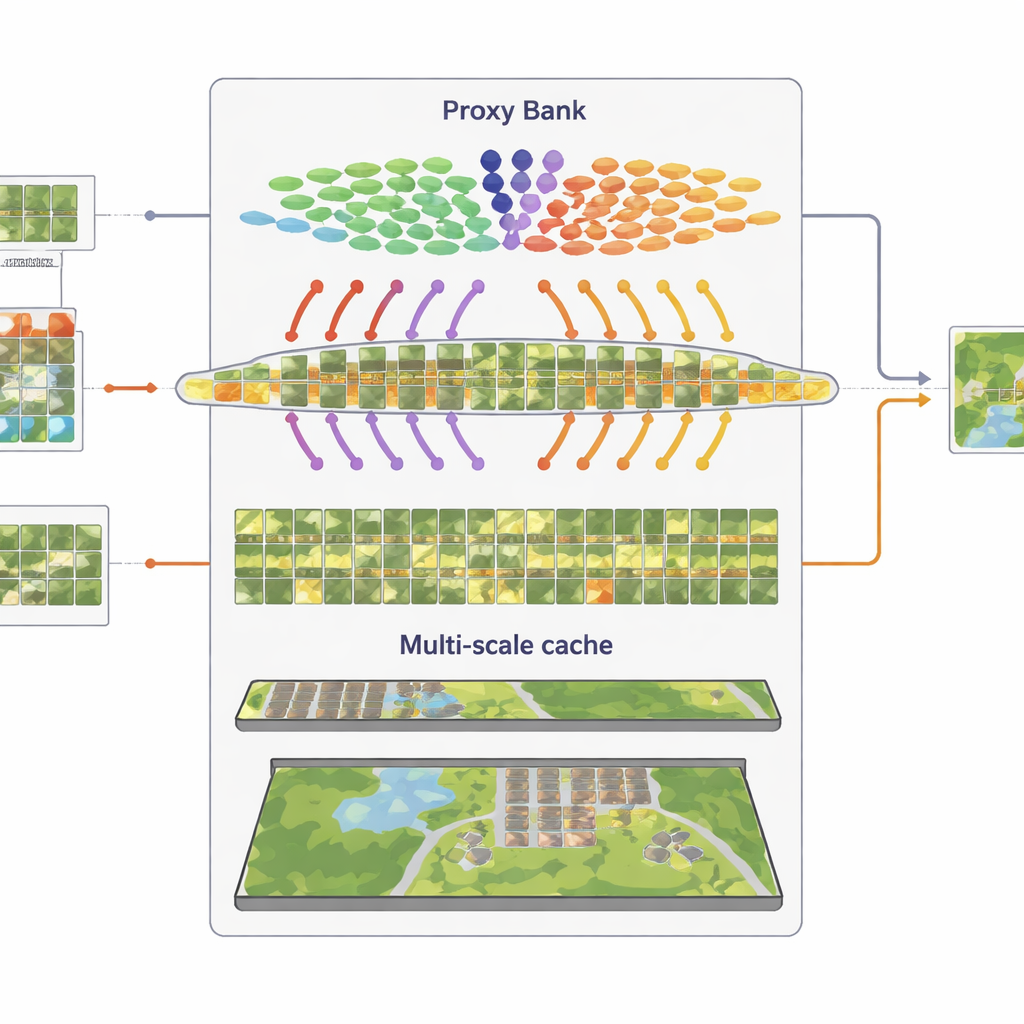
Visuele patronen onthouden op meerdere schalen
Het derde component is een multi-granulariteits “feature cache” die representatieve visuele patronen onthoudt. Uit de zelfverzekerd pseudo-geëtiketteerde beelden slaat SatAdapter zowel patch-niveau details als samenvattingen van volledige scènes op als key–value paren. Tijdens inferentie, wanneer een nieuw beeld binnenkomt, meet het systeem de overeenkomst met deze cache en met de proxy-gebaseerde voorspellingen, en combineert het deze met de oorspronkelijke zero-shot CLIP-output. Dit eenvoudige ophalen-en-fuseren proces, gestuurd door een paar wegingsparameters, stelt het model in staat om opgebouwde kennis over texturen, vormen en indelingen uit eerdere satellietscènes opnieuw te gebruiken — zonder enige gradient-gebaseerde training.
Het idee bewijzen op diverse landschappen
Om SatAdapter te testen evalueren de auteurs het op vijf standaard satellietbenchmarks die Europese landbouwgrond, wereldsteden, Amerikaanse buitenwijken en complexe Chinese stedelijke scènes bestrijken, elk met verschillende resoluties en landbedekkingscategorieën. Onder zero-shot condities — waarbij alleen klassennamen bekend zijn — overtreft SatAdapter verschillende toonaangevende cross-modale baselines en verhoogt de gemiddelde top-1 nauwkeurigheid met bijna vijf procentpunten. In few-shot settings, waar slechts 1 tot 16 gelabelde beelden per klasse beschikbaar zijn, verslaat het ook cache-gebaseerde concurrenten die gelabelde ondersteuningsbeelden vereisen. Ablatie-experimenten tonen aan dat elk van de drie modules helpt, maar hun combinatie — rijke prompts, proxy-kalibratie en multi-schaal caching — levert de grootste en meest stabiele winst op over backbones en datasets.
Wat dit betekent voor het monitoren van onze veranderende wereld
Voor niet-specialisten is de belangrijkste conclusie dat SatAdapter laat zien hoe je algemene beeld–taal AI kunt aanpassen aan satellietbeelden zonder de gebruikelijke behoefte aan veel gelabelde data. Door eenvoudige klassennamen te verrijken met beschrijvende taal, proxy-klassificeerders te construeren uit ongeëtiketteerde scènes en visuele patronen te hergebruiken via een feature cache, verandert het framework een generiek op het web getraind model in een krachtig remote sensing-hulpmiddel dat met weinig data kan werken. Dit maakt het praktischer om landgebruik, infrastructuur en milieuverandering op schaal te monitoren, zelfs wanneer experts slechts een klein deel van de beelden die vanuit de ruimte binnenkomen kunnen labelen.
Bronvermelding: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Trefwoorden: remote sensing, vision-language modellen, few-shot learning, satellietbeelden, geospatiale AI