Clear Sky Science · sv
Låg-data tvärmodal anpassning för fjärranalys med proxy-förstärkt flerskiktsfunktionscache
Lära satelliter att förstå jorden med mindre data
Satellitbilder är en guldgruva för att följa stadsutveckling, övervaka grödor och reagera på katastrofer — men att omvandla dessa bilder till pålitliga kartor kräver vanligtvis tusentals omsorgsfulla mänskliga etiketter. Denna artikel presenterar ett nytt sätt att få kraftfulla bild–språk-AI-modeller att fungera för satellitdata även när märkta exempel är knappa, vilket hjälper till att öppna upp tidsnära, detaljerade vyer av vår planet utan omfattande annoteringsinsatser.
Varför vanlig AI har svårt med rymdvy
De flesta moderna vision–språk-system, såsom CLIP, tränas på vardagsfotografier parade med kort text från webben. De vet mycket om katter, bilar och stadsgator, men betydligt mindre om startbanor, risfält eller industriområden sedda från hundratals kilometer höjd. Fjärranalysbilder skiljer sig i skala, synvinkel och spektrala band, och etiketter för dem är dyra eftersom de kräver expertkunskap. När endast några få exempel finns tillgängliga tenderar standardmetoder för finjustering att överanpassa eller misslyckas med konvergens, vilket lämnar dessa stora modeller outnyttjade i geospatiala tillämpningar.
Lägga rik språkbeskrivning till enkla etiketter
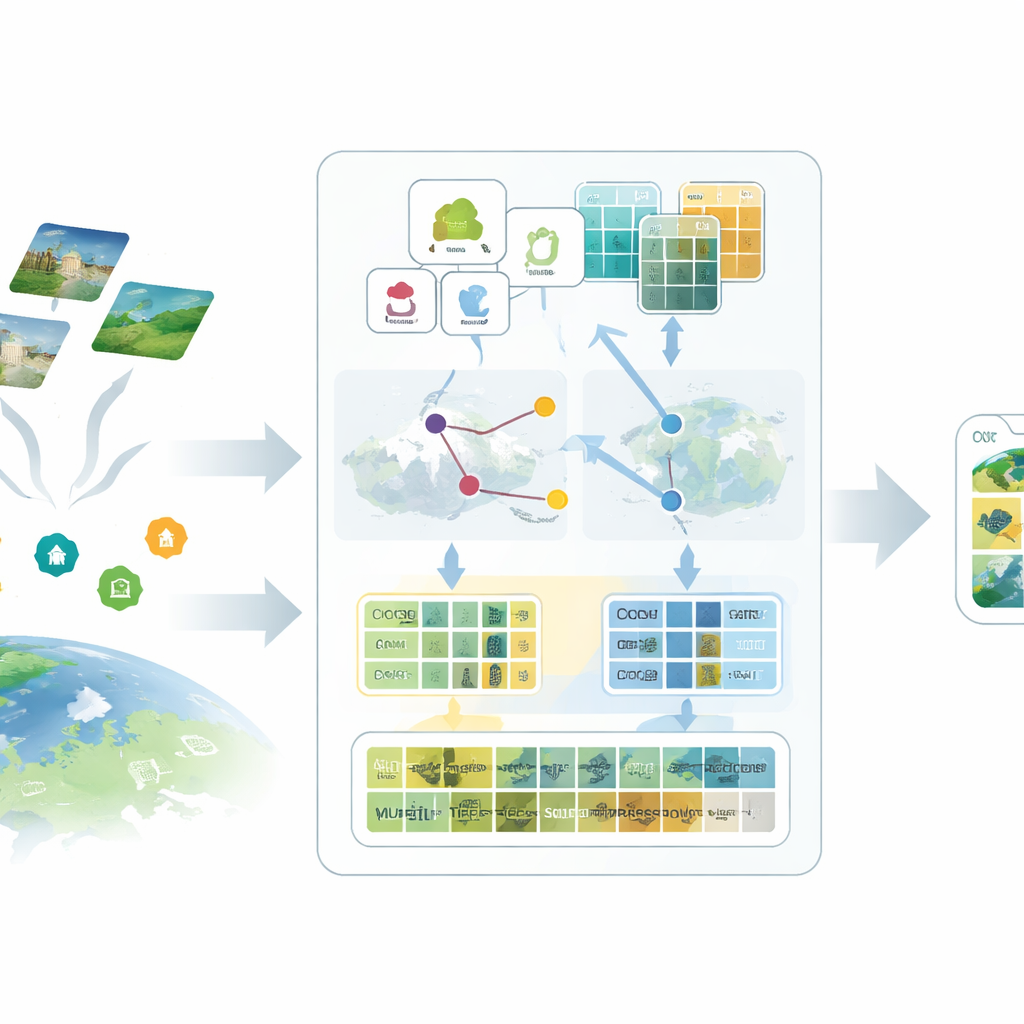
Den första idén i det föreslagna SatAdapter-ramverket är att "prata" med modellen på ett sätt som är meningsfullt för satelliter. Istället för att mata in korta klasser som "flygplats" eller "skog" använder författarna en stor språkmodell för att producera detaljerade beskrivningar av hur varje klass ser ut från ovan — dess textur, former, mönster och spatiala layout. Flera noggrant utformade frågepromptar styr språkmodellen att beskriva, till exempel hur startbanor ligger i förhållande till varandra, hur byggnader klustras eller hur fält är arrangerade. Dessa rikare beskrivningar omvandlas till textfunktioner som ger vision–språk-modellen en tydligare uppfattning om hur varje markanvändningstyp bör se ut i satellitbilder.
Proxies: ersättare för saknade etiketter
Den andra ingrediensen ersätter saknade etiketter med noggrant kalibrerade ersättare kallade proxies. SatAdapter börjar med en frusen bildeencoder från CLIP och beräknar hur omärkta satellitbilder relaterar till de språkbaserade klasbeskrivningarna. Därifrån bygger den klassvisa referensvektorer som fungerar som mjuka, inlärda klassificerare inom det gemensamma bild–text-rymden. Dessa proxies förfinas genom en effektiv offline-optimering som aldrig ändrar backbone-modellen. För att göra dem mer tillförlitliga fusionerar metoden prediktioner från två kompletterande encodrar — ett konvolutionsnätverk och en vision-transformer — så att både fina texturer och breda layouter bidrar. Resultatet är en uppsättning självsäkra pseudo-etiketter som approximativt motsvarar mänskliga annotationer utan manuellt arbete.
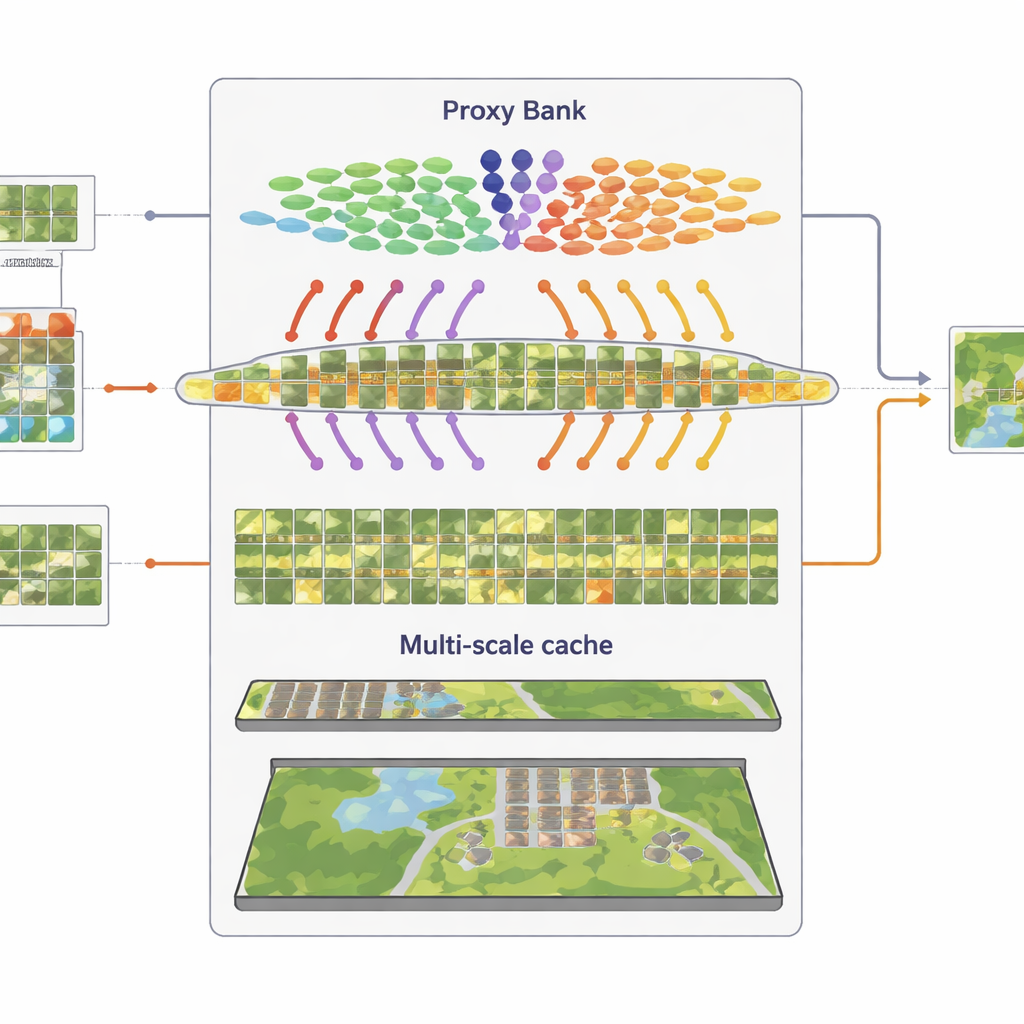
Komma ihåg visuella mönster i flera skalor
Den tredje komponenten är en flerskikts "funktionscache" som kommer ihåg representativa visuella mönster. Från de självförtroende pseudo-etiketterade bilderna lagrar SatAdapter både detaljnivåer på patch-nivå och helbildssammanfattningar som nyckel–värde-par. Under inferens, när en ny bild anländer, mäter systemet dess likhet med denna cache och med de proxy-baserade prediktionerna, och kombinerar dem med det ursprungliga zero-shot CLIP-utmatningen. Denna enkla sök-och-fusion-process, styrd av ett par viktparametrar, låter modellen återanvända ackumulerad kunskap om texturer, former och layouter som setts i tidigare satellitscener — utan någon gradientbaserad träning.
Bevisa idén på skiftande landskap
För att testa SatAdapter utvärderar författarna det på fem standardiserade satellitbenchmark som täcker europeiskt jordbruk, globala städer, amerikanska förorter och komplexa kinesiska urbana miljöer, var och en med olika upplösningar och marktäcktkategorier. Under zero-shot-förhållanden — där endast klasnamn är kända — överträffar SatAdapter flera ledande tvärmodala baslinjer och höjer genomsnittlig top-1-precision med nästan fem procentenheter. I få-exempel-inställningar, där endast 1 till 16 märkta bilder per klass är tillgängliga, slår det också cache-baserade konkurrenter som kräver märkta stödexempel. Ablationsstudier visar att var och en av de tre modulerna hjälper, men deras kombination — rika promptar, proxy-kalibrering och flerskalig caching — levererar de största och mest stabila förbättringarna över backbones och dataset.
Vad detta betyder för att övervaka vår föränderlig värld
För icke-specialister är huvudbudskapet att SatAdapter visar hur man anpassar allmänt användbara bild–språk-AI till satellitbilder utan den vanliga hungern efter märkta data. Genom att berika enkla klasnamn med beskrivande språk, konstruera proxy-klassificerare från omärkta scener och återanvända visuella mönster via en funktionscache förvandlar ramverket en generisk web-tränad modell till ett starkt fjärranalysverktyg som fungerar med lite data. Detta gör det mer praktiskt att övervaka markanvändning, infrastruktur och miljöförändringar i stor skala, även när experter bara kan märka en liten bråkdel av de bilder som strömmar ner från rymden.
Citering: Sun, Y., Cheng, Q., Xie, W. et al. Low-data cross-modal adaptation for remote sensing with proxy-enhanced multi-granularity feature caching. Sci Rep 16, 10895 (2026). https://doi.org/10.1038/s41598-026-39823-7
Nyckelord: fjärranalys, vision-språkmodeller, få-exempel-inlärning, satellitbilder, geospatial AI