Clear Sky Science · zh
基于 AI 的音频到视频生成:通过稳定扩散与 CNN 增强变换器实现动态内容创作
将声音化为流动的故事
想象一下,对着笔记本说话,瞬间看到一段短视频,不仅表达了你说的话,还传达了你说话时的情绪。这就是 EchoVid 的愿景:一种将语音转化为短小、具备情感感知的视频剪辑的新型人工智能系统。该工作位于语音技术、图像生成与视频特效的交汇处,目标是让数字内容创作像大声说话一样简单。
为何将视觉与声音匹配如此困难
人们在理解彼此时自然会将语气、面部表情与周围场景结合起来。现有的图像或视频生成 AI 常常错过这种丰富性。许多系统侧重于书面文本提示,忽略了语音中的停顿、音高或兴奋度如何传递喜悦、悲伤或悬念。早期的视频生成器在保持运动连贯性方面存在困难,常出现闪烁画面、僵硬角色或与声音不相符的视觉内容。这些差距限制了此类工具在教师、讲故事者和依赖准确、情感忠实视觉的辅助技术中的实用性。
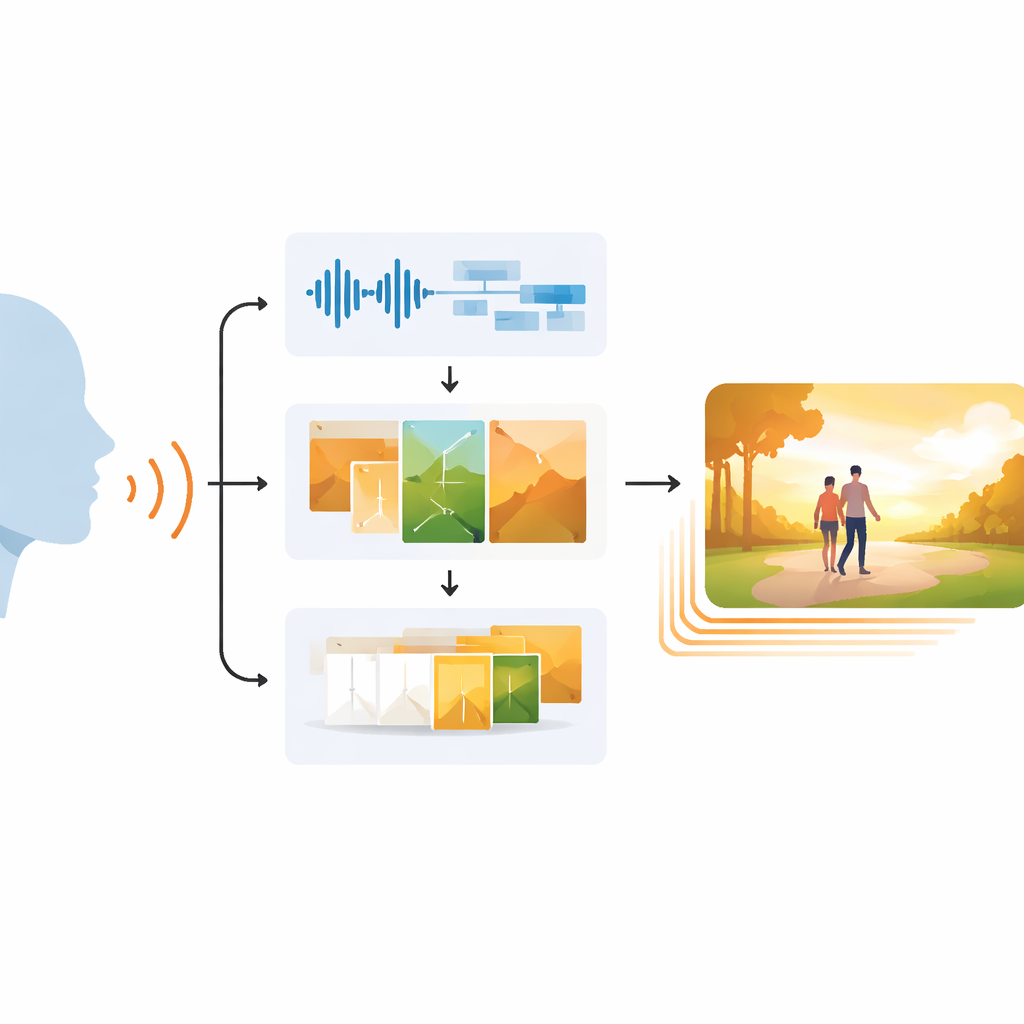
从语音到视频的三步路径
EchoVid 通过三阶段管道应对这一问题。首先,系统通过麦克风听取说话者的声音,对音频进行降噪处理,然后在转写文本的同时从节奏、音高与强度中估计语音情绪。其次,它将识别出的词汇与这些情感线索融合,构建出丰富的内部提示词。该提示词会与一个主题数据库(如自然、城市生活或奇幻)匹配,以保持场景的主题一致。利用名为 Stable Diffusion 的强大图像生成器,EchoVid 随后生成能同时反映所说内容与说话情感的单帧图像。最后,在第三阶段,系统在一种特殊的“潜在”空间中合成额外的中间帧,平滑地将一帧图像变形为下一帧,从而使最终视频更顺畅而非跳跃。
引擎内部
在引擎内部,EchoVid 在质量与速度之间谨慎平衡。语音前端针对人声所在的频率范围进行了调优,这有助于减少识别错误。图像生成器在中等分辨率下运行,支持后期放大处理,使得处理时间可控,同时仍能产出清晰结果。研究人员使用额外的提示提示——例如用于保持背景一致或表现动态运动的标签——以使角色与场景在帧与帧之间保持稳定。他们也避免使用昂贵且缓慢的技术,如完全自回归的视频变换器,而是依靠巧妙的插值和图像生成工具的重用。因此,在现代显卡上,EchoVid 生成成品片段所需的时间仅略超过原始音频的时长,使得接近实时的使用成为可能。
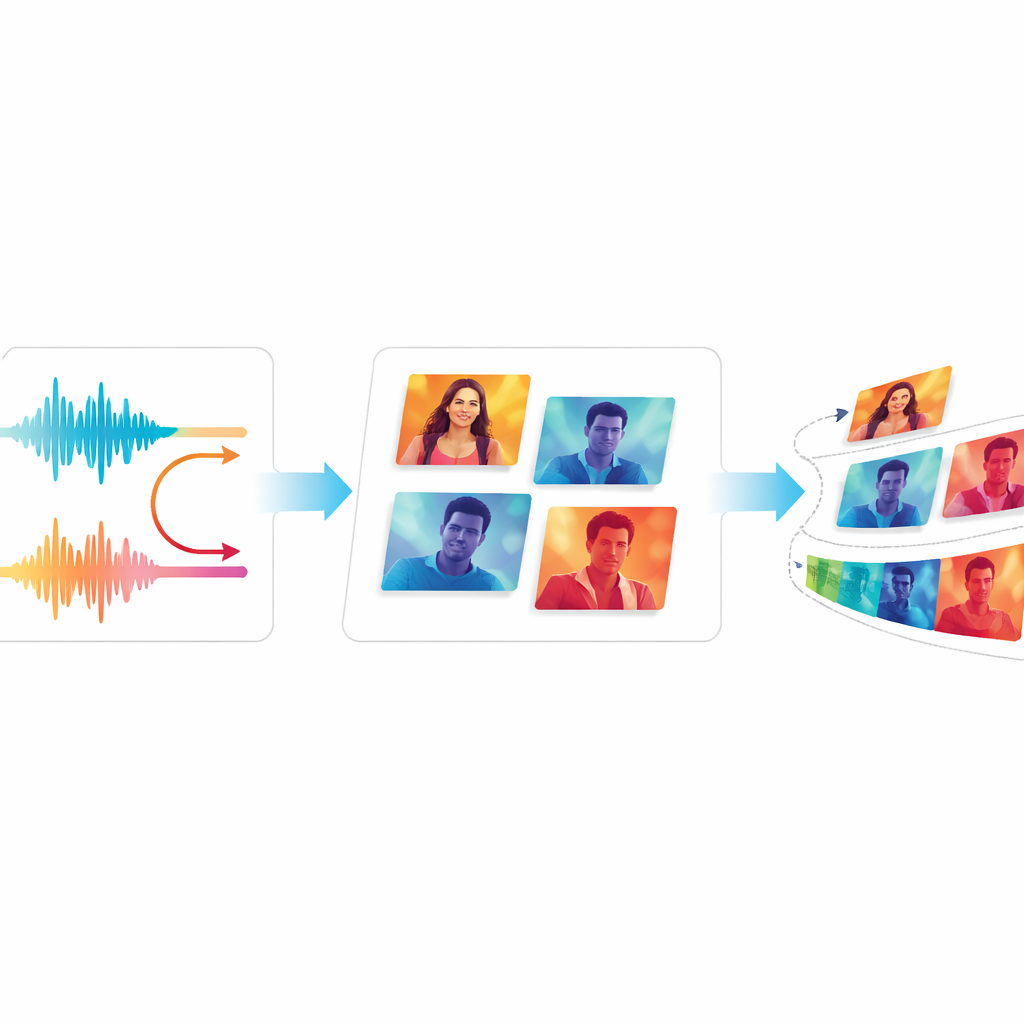
质量与流畅度的测试
为了评估 EchoVid 是否真正优于以往系统,作者将其与知名的视频生成器进行基准比较,包括经典的基于 GAN 的模型和现代的扩散类工具。他们使用标准度量将生成视频与真实视频进行对比,并采用一种评分方法检测视频与文本描述的匹配程度。团队还提出了两个新度量:一个跟踪视觉内容在帧间保持一致的程度,另一个估计观众可能注意到的干扰性闪烁量。在两个广泛使用的视频数据集上,EchoVid 在语义对齐与时间稳定性方面均优于旧系统,同时保持计算效率。观看样片的人类专家一致认为这些视频看起来连贯且与提示吻合良好。
对日常用户的潜在意义
EchoVid 的核心信息是,高质量的语音驱动视频生成现在在无需巨额训练成本或编辑技能的情况下变得可及。通过将普通的口述描述转化为短小、情绪调校的视频,该系统可能帮助教师把讲座变成视觉故事、增强播客的吸引力,或通过对话的视觉摘要支持听力受损者。作者也承认仍存在的挑战——例如处理多种语言、细微的面部表情以及非常长或复杂的场景——但他们的结果表明,谨慎地结合语音分析、图像扩散与智能帧插值,已经能够仅凭语音就生成令人信服且具情绪感知的视频。
引用: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
关键词: 音频到视频生成, 语音驱动视频, 生成式人工智能, 稳定扩散, 多模态叙事