Clear Sky Science · pl
Generowanie wideo z dźwięku sterowane AI do dynamicznego tworzenia treści za pomocą stable diffusion i transformatorów rozszerzonych o CNN
Przekształcanie głosów w ruchome opowieści
Wyobraź sobie, że mówisz do laptopa i natychmiast oglądasz krótki film, który oddaje nie tylko to, co powiedziałeś, ale też jak się czułeś, mówiąc to. To obietnica EchoVid — nowego systemu sztucznej inteligencji, który zamienia mówione audio w krótkie, emocjonalnie wyczulone klipy wideo. Praca ta leży na styku technologii mowy, generowania obrazów i efektów wideo, z celem uproszczenia tworzenia treści cyfrowych do poziomu zwykłego mówienia na głos.
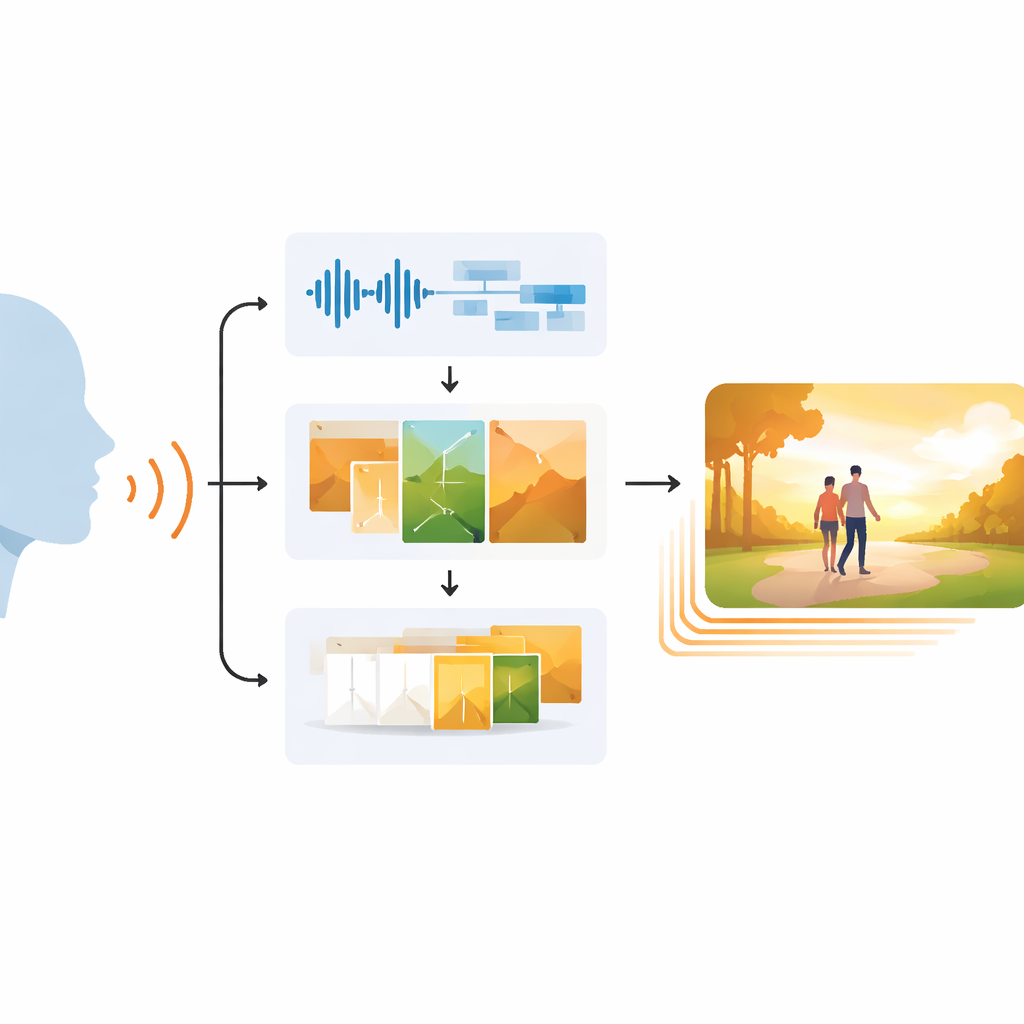
Dlaczego dopasowanie obrazu i dźwięku jest trudne
Ludzie naturalnie łączą ton głosu, mimikę i otoczenie, by się rozumieć. Istniejące systemy AI generujące obrazy czy filmy często pomijają tę złożoność. Wiele z nich skupia się na pisemnych poleceniach, ignorując to, jak pauzy, wysokość tonu czy podniecenie w mowie sygnalizują radość, smutek czy napięcie. Wcześniejsze generatory wideo miały problem z płynnym ruchem w czasie, często tworząc migoczące sceny, sztywne postacie lub obrazy, które nie pasowały do dźwięku. Te braki ograniczają przydatność takich narzędzi dla nauczycieli, opowiadaczy i technologii wspomagających, które polegają na dokładnych, emocjonalnie wiernych wizualizacjach.
Trzystopniowa droga od mowy do wideo
EchoVid rozwiązuje ten problem za pomocą trzyetapowego procesu. Najpierw system słucha osoby mówiącej przez mikrofon. Oczyszcza dźwięk, aby zredukować szumy tła, a następnie konwertuje mowę na tekst, jednocześnie szacując nastrój głosu na podstawie rytmu, wysokości i natężenia. Po drugie, łączy rozpoznane słowa z tymi emocjonalnymi wskazówkami, tworząc bogaty wewnętrzny prompt. Prompt jest dopasowywany do bazy tematów — takich jak natura, życie miejskie czy fantasy — aby utrzymać scenę w odpowiednim tonie. Korzystając z potężnego generatora obrazów znanego jako Stable Diffusion, EchoVid generuje pojedyncze klatki, które wizualnie odzwierciedlają zarówno treść wypowiedzi, jak i jej nastrój. Wreszcie, w trzecim etapie system tworzy dodatkowe klatki pośrednie w specjalnej „ukrytej” (latent) przestrzeni, delikatnie morfując jeden obraz w kolejny, tak aby finalne wideo było płynne, a nie skokowe.
Wnętrze silnika
Pod maską EchoVid starannie wyrównuje jakość z prędkością. Front-end mowy jest dostrojony do zakresu częstotliwości typowych dla ludzkiego głosu, co pomaga zredukować błędy rozpoznawania. Generator obrazów działa w umiarkowanej rozdzielczości, która może być później powiększana, utrzymując czas przetwarzania na rozsądnym poziomie przy jednoczesnym uzyskaniu ostrych rezultatów. Badacze wykorzystują dodatkowe wskazówki w promptach — na przykład tagi zapewniające spójne tło czy dynamiczny ruch — aby utrzymać postacie i ustawienia stabilne między klatkami. Unikają też kosztownych, wolnych technik, takich jak w pełni autoregresywne transformatory wideo, zamiast tego polegając na sprytnej interpolacji i ponownym wykorzystaniu narzędzi do generowania obrazów. W efekcie, na nowoczesnej karcie graficznej EchoVid może wyprodukować gotowe klipy w czasie niewiele dłuższym niż długość oryginalnego nagrania, co czyni użycie w niemal rzeczywistym czasie wykonalnym.
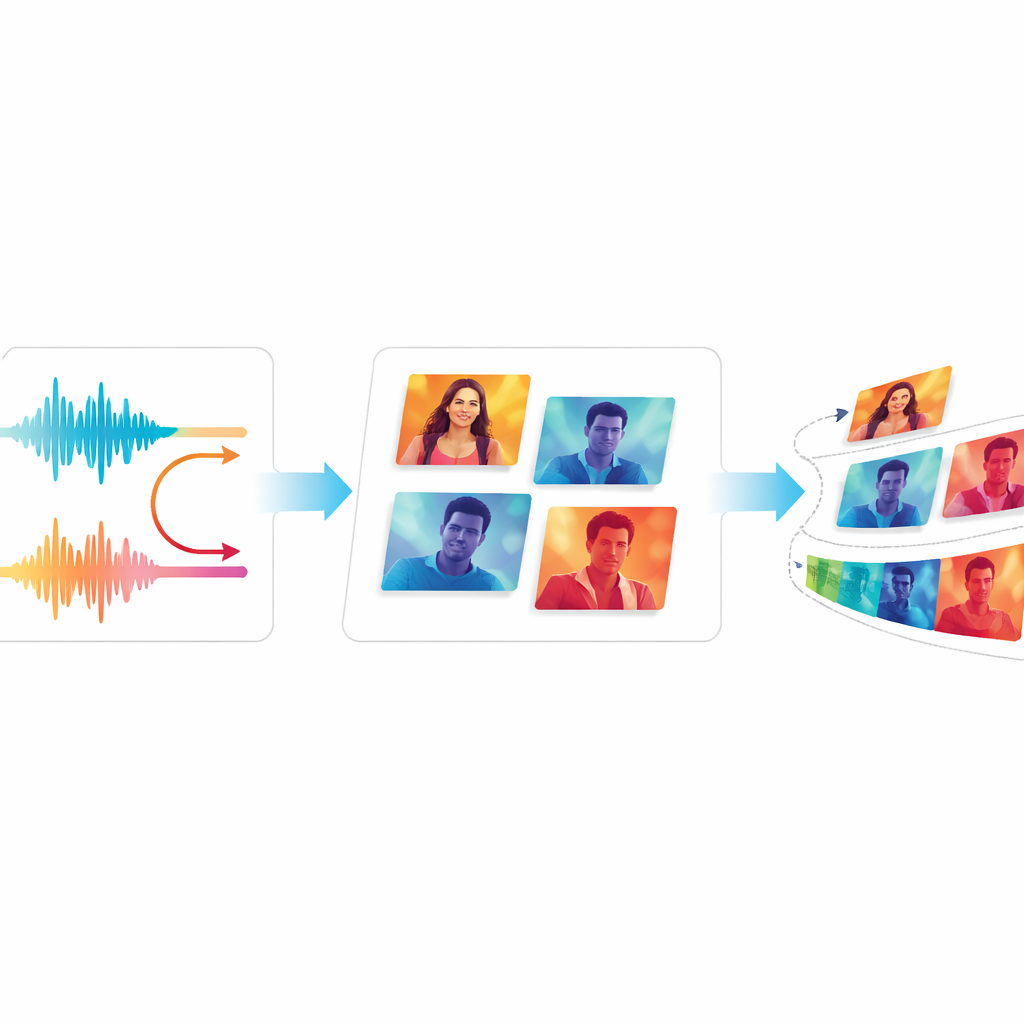
Testowanie jakości i płynności
Aby ocenić, czy EchoVid rzeczywiście przewyższa wcześniejsze systemy, autorzy porównali go z dobrze znanymi generatorami wideo, w tym klasycznymi modelami opartymi na GAN-ach i nowoczesnymi narzędziami opartymi na dyfuzji. Używają standardowych miar porównujących generowane wideo z rzeczywistymi, a także metody oceny, która sprawdza, jak wiernie wideo odzwierciedla opisy tekstowe. Zespół wprowadza też dwie nowe miary: jedną śledzącą spójność wizualną między klatkami, a drugą szacującą, ile rozpraszającego migotania widzowie mogą zauważyć. Na dwóch powszechnie używanych zbiorach danych wideo EchoVid osiąga lepsze wyniki niż starsze systemy pod względem zgodności semantycznej i stabilności temporalnej, przy jednoczesnej efektywności obliczeniowej. Eksperci-ludzie, którzy obejrzeli próbne klipy, zgodzili się, że wideo wygląda spójnie i dobrze odpowiada promptom.
Co to może znaczyć dla codziennych użytkowników
Główne przesłanie EchoVid jest takie, że generowanie wysokiej jakości wideo sterowanego mową jest teraz w zasięgu bez ogromnych kosztów treningu czy umiejętności montażowych. Zamieniając zwykłe mówione opisy w krótkie, emocjonalnie dopasowane filmy, system może pomóc nauczycielom przekształcać wykłady w wizualne opowieści, uczynić podcasty bardziej angażującymi lub wspierać osoby z ubytkiem słuchu poprzez wizualne streszczenia rozmów. Autorzy przyznają, że pozostają otwarte wyzwania — takie jak obsługa wielu języków, drobne ruchy twarzy czy bardzo długie albo złożone sceny — ale ich wyniki pokazują, że staranne połączenie analizy mowy, dyfuzji obrazu i inteligentnej interpolacji klatek już potrafi wygenerować przekonujące, nastawione na nastrój wideo z samego dźwięku głosu.
Cytowanie: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Słowa kluczowe: generowanie audio-do-wideo, wideo sterowane mową, generatywne AI, stable diffusion, multimodalne opowiadanie