Clear Sky Science · nl
AI-gestuurde audio-naar-video generatie voor dynamische contentcreatie via stable diffusion en CNN-augmented transformers
Stemmen omzetten in bewegende verhalen
Stel je voor dat je in je laptop spreekt en direct een korte video ziet die niet alleen vastlegt wat je zei, maar ook hoe je je voelde toen je het zei. Dat is de belofte van EchoVid, een nieuw kunstmatig-intelligentiesysteem dat gesproken audio omzet in korte, emotioneel bewuste videoclips. Het werk bevindt zich op het snijvlak van spraaktechnologie, beeldgeneratie en video-effecten, met als doel digitale contentcreatie net zo eenvoudig te maken als hardop praten.
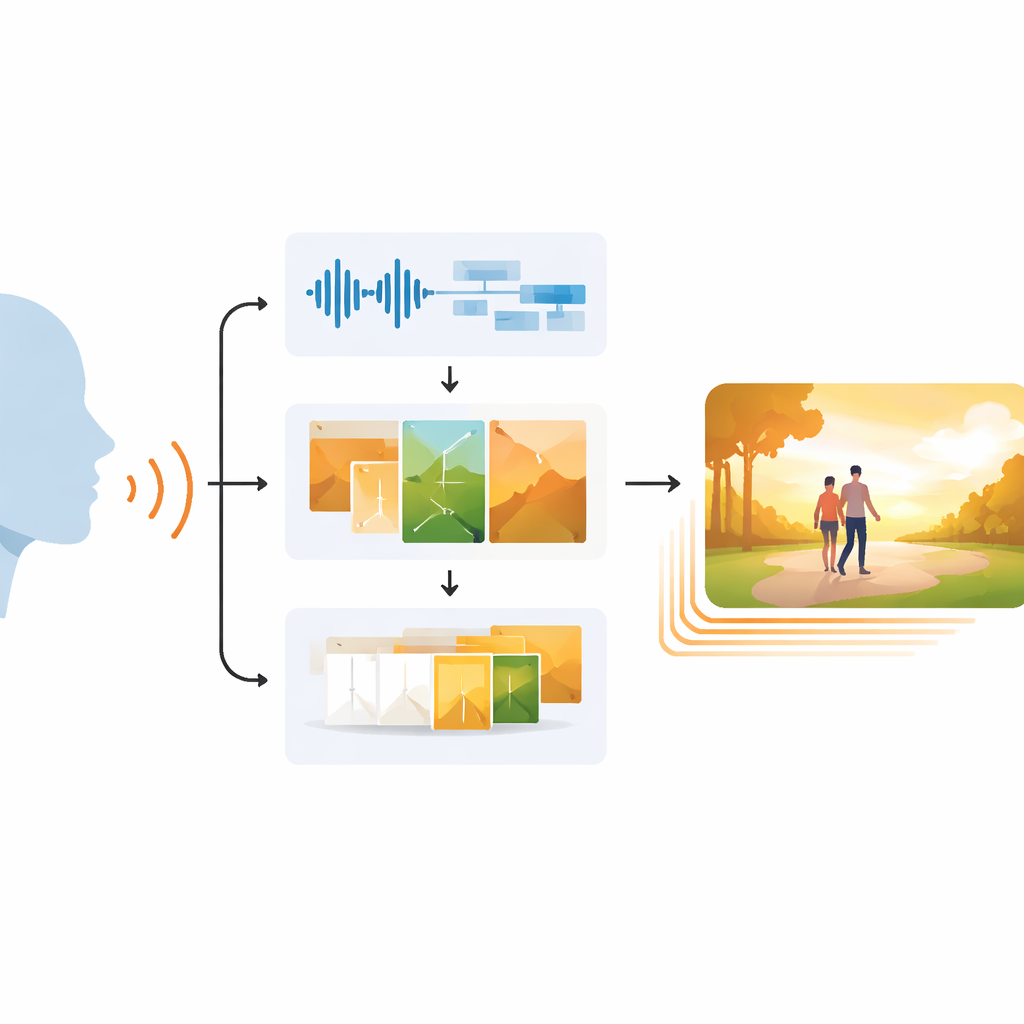
Waarom het koppelen van beeld en geluid moeilijk is
Mensen combineren van nature stemintonatie, gezichtsuitdrukking en omgevingsscènes om elkaar te begrijpen. Bestaande AI-systemen die afbeeldingen of video’s genereren missen vaak deze rijkdom. Veel systemen richten zich op geschreven tekstprompts en negeren hoe pauzes, toonhoogte of enthousiasme in spraak blijdschap, droefheid of spanning signaleren. Eerdere videogeneratoren hadden moeite om bewegingen soepel in de tijd te houden, en produceerden vaak flikkerende scènes, stijve karakters of beelden die niet goed bij het geluid pasten. Deze lacunes beperken het nut van zulke tools voor docenten, vertellers en ondersteunende technologieën die afhankelijk zijn van nauwkeurige, emotioneel getrouwe visuals.
Een driedelig traject van spraak naar video
EchoVid pakt dit probleem aan met een driedelig proces. Eerst luistert het systeem naar iemand die via een microfoon praat. Het zuivert de audio om achtergrondgeluid te verminderen en zet vervolgens de spraak om in tekst, terwijl het ook de vocale stemming inschat aan de hand van ritme, toonhoogte en intensiteit. Ten tweede mengt het de herkende woorden met deze emotionele aanwijzingen om een rijk intern prompt te vormen. Dat prompt wordt afgestemd op een database met thema’s—zoals natuur, stadsleven of fantasy—om de scène thematisch consistent te houden. Met behulp van een krachtige beeldgenerator bekend als Stable Diffusion produceert EchoVid vervolgens individuele frames die zowel visueel weergeven wat er gezegd is als hoe het gezegd is. Ten slotte creëert het systeem in de derde fase extra tussenframes in een speciale ‘latente’ ruimte, waarbij het zachtjes het ene beeld in het volgende morft zodat de uiteindelijke video soepel aanvoelt in plaats van schokkerig.
In de machinekamer
Onder de motorkap balanceert EchoVid zorgvuldig kwaliteit en snelheid. De spraakfrontend is afgestemd op het frequentiebereik waarin menselijke stemmen leven, wat helpt herkenningsfouten te verminderen. De beeldgenerator werkt op een gematigde resolutie die kan worden opgeschaald, waardoor de verwerkingstijd beheersbaar blijft en toch scherpe resultaten oplevert. De onderzoekers gebruiken extra prompt-aanwijzingen—zoals tags voor consistente achtergronden of dynamische beweging—om karakters en omgevingen frame na frame stabiel te houden. Ze vermijden ook dure, trage technieken zoals volledig autoregressieve videotransformers en vertrouwen in plaats daarvan op slimme interpolatie en hergebruik van beeldgeneratietools. Daardoor kan EchoVid op een moderne grafische kaart voltooide clips produceren in slechts iets meer tijd dan de originele audio duurt, waardoor bijna-realtime gebruik voorstelbaar wordt.
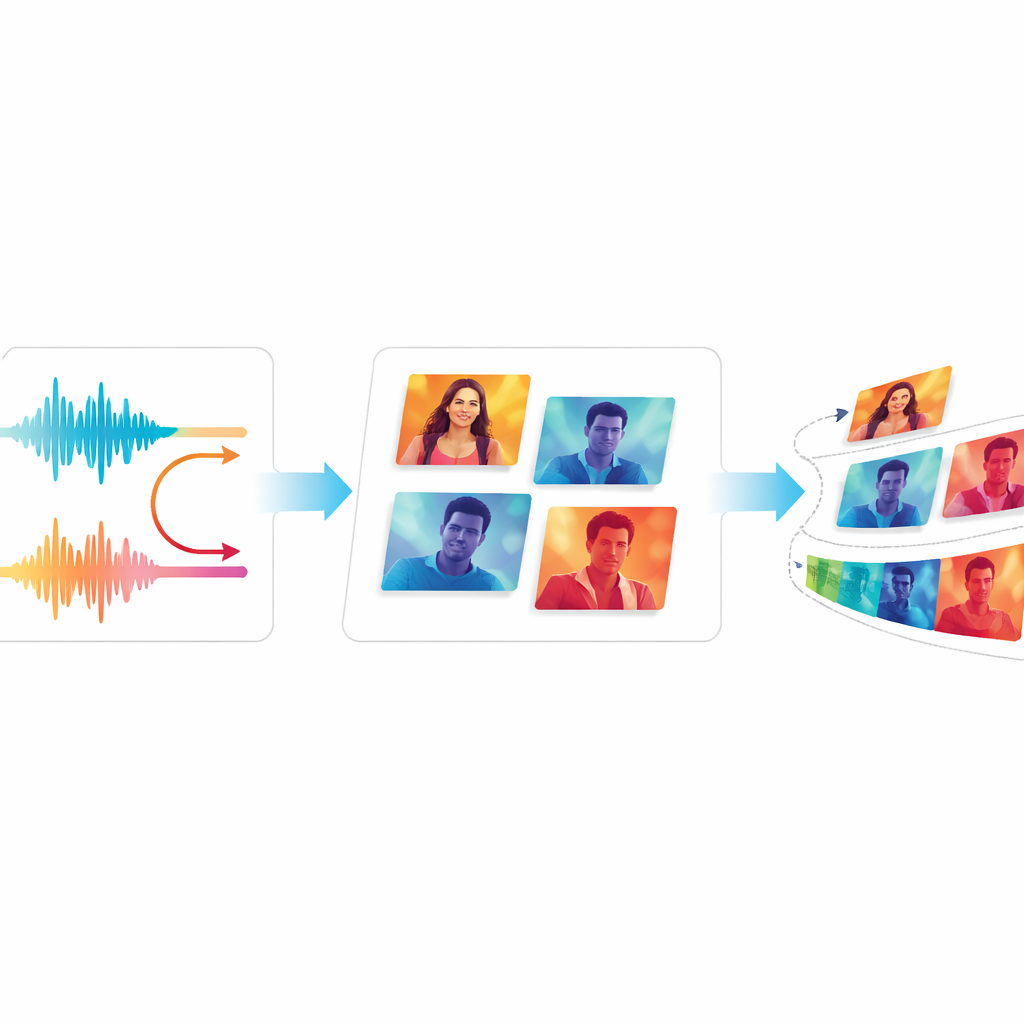
Testen van kwaliteit en soepelheid
Om te beoordelen of EchoVid echt beter is dan eerdere systemen, benchmarken de auteurs het tegen bekende videogeneratoren, waaronder klassieke GAN-gebaseerde modellen en moderne diffusion-gebaseerde tools. Ze gebruiken standaardmaten die gegenereerde video’s vergelijken met echte, evenals een scoringsmethode die controleert hoe nauwkeurig video’s bij tekstbeschrijvingen aansluiten. Het team introduceert ook twee nieuwe maatstaven: de ene volgt hoe consistent de visuele inhoud van frame naar frame blijft, en de andere schat in hoeveel storend flikkeren kijkers mogelijk opmerken. Over twee veelgebruikte videodatasets scoort EchoVid beter dan oudere systemen op semantische afstemming en temporele stabiliteit, terwijl het computationeel efficiënt blijft. Menselijke experts die voorbeeldclips bekeken waren het erover eens dat de video’s coherent leken en goed bij de prompts pasten.
Wat dit kan betekenen voor alledaagse gebruikers
De hoofdboodschap van EchoVid is dat hoogwaardige, spraakgestuurde videogeneratie nu haalbaar is zonder enorme trainingskosten of montagevaardigheden. Door gewone gesproken beschrijvingen om te zetten in korte, emotioneel afgestemde video’s, kan het systeem docenten helpen lezingen in visuele verhalen te veranderen, podcasts aantrekkelijker te maken of mensen met gehoorverlies te ondersteunen via visuele samenvattingen van gesprekken. De auteurs erkennen openstaande uitdagingen—zoals het verwerken van veel talen, fijnmazige gelaatsuitdrukkingen en zeer lange of complexe scènes—maar hun resultaten laten zien dat het zorgvuldige combineren van spraakanalyse, beelddiffusie en slimme frame-interpolatie al overtuigende, stemmingbewuste video’s kan produceren uit niets anders dan het geluid van een stem.
Bronvermelding: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Trefwoorden: audio-naar-video generatie, spraakgestuurde video, generatieve AI, stable diffusion, multimodale vertelkunst