Clear Sky Science · he
יצירת וידאו מ-audio מונעת בינה מלאכותית ליצירת תוכן דינמי באמצעות Stable Diffusion וטרנספורמרים מועשרים ב-CNN
להפוך קולות לסיפורים זזים
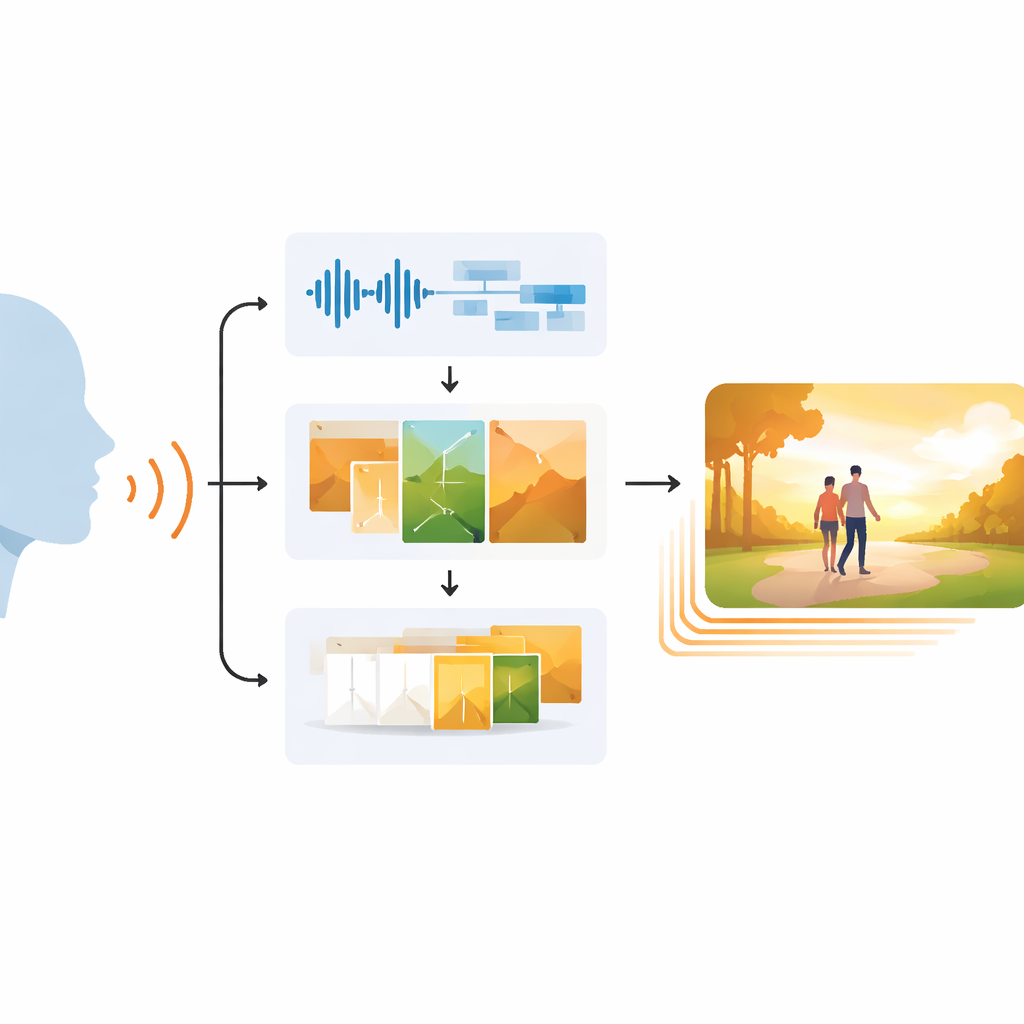
דמיין שאתה מדבר אל המחשב הנייד ורואה מייד סרטון קצר שמגלם לא רק את המילים שדיברת, אלא גם את התחושה שעמדה מאחוריהן. זו ההבטחה של EchoVid, מערכת בינה מלאכותית חדשה שממירה קלט דיבור לקליפים וידאו קצרים הרגישים רגשית. העבודה נעשית בצומת שבין טכנולוגיות דיבור, יצירת תמונות ואפקטי וידאו, במטרה להקל את יצירת התוכן הדיגיטלי לכדי פעולה פשוטה כמו דיבור בקול.
מדוע התאמת ראייה וקול קשה
אנשים משלבים בטבעיות גוון דיבור, הבעות פנים וסצנות סביבתיות כדי להבין זה את זה. מערכות בינה מלאכותית קיימות שמייצרות תמונות או וידאו לעתים מפספסות את העושר הזה. רבות מהן מתמקדות בפירומפטים טקסטואליים, ומתעלמות מהפסקות, גובה גוון הקול או התרגשות בדיבור שמאותתים שמחה, עצב או מתח. גנרטורים וידאו מוקדמים התקשו לשמור על תנועה חלקה לאורך זמן, לעתים הובילו לזזים מהבהבים, דמויות נוקשות או ויזואליות שאינן תואמות את הצליל. הפערים האלה מצמצמים את התועלת של הכלים עבור מורים, מספרי סיפורים וטכנולוגיות סיוע התלויות בייצוגים חזותיים מדויקים ורגשיים.
נתיב בשלושה שלבים מהדיבור לוידאו
EchoVid מטפלת בבעיה הזו באמצעות צינור עבודה בשלושה שלבים. ראשית, המערכת מאזינה לאדם המדבר דרך המיקרופון. היא מנקה את האודיו להפחתת רעשי רקע ואז ממירה את הדיבור לטקסט תוך הערכת מצב רגשי קולית על סמך קצב, גובה ועוצמה. שנית, היא משלבת את המילים המזוהות עם רמזים רגשיים אלה כדי ליצור פרומפט פנימי עשיר. פרומפט זה מושווה מול מאגר נושאים—כמו טבע, חיי עיר או פנטזיה—כדי לשמור על קוהרנטיות הסצנה. באמצעות גנרטור תמונה חזק הידוע כ-Stable Diffusion, EchoVid מייצרת מסגרות בודדות שמשקפות ויזואלית הן את תוכן הדיבור והן את מצבו הרגשי. לבסוף, בשלב השלישי, המערכת יוצרת מסגרות ביניים נוספות במרחב "לטנטי" מיוחד, מטשטשת בעדינות תמונה לתמונה כך שהווידאו הסופי ירגיש חלק ולא קופצני.
בתוך חדר המנוע
מתחת למכסה המנוע, EchoVid מאזנת בקפידה בין איכות ומהירות. חזית הדיבור מכויילת להתמקד בטווח התדרים שבו קולות אנושיים פועלים, מה שמסייע להפחית שגיאות בזיהוי. גנרטור התמונה פועל ברזולוציה מתונה שניתנת להגדלה, מה שמשמור על זמן עיבוד סביר תוך יצירת תוצאות חדה למדי. החוקרים משתמשים ברמזים נוספים בפרומפט—כגון תגיות לרקעים עקביים או תנועה דינמית—כדי לשמור על יציבות הדמויות והסביבות מקשה למסגרת. הם גם נמנעים מטכניקות יקרות ואיטיות כמו טרנספורמרים וידאו אוטורגרסיביים מלאים, ובמקום זאת מסתמכים על אינטרפולציה חכמה ושימוש חוזר בכלי יצירת תמונה. כתוצאה מכך, על כרטיס גרפי מודרני, EchoVid יכולה להפיק קליפים גמורים בזמן שאינו הרבה יותר מאריכות האודיו המקוריות, מה שהופך שימוש קרוב-לזמן-אמיתי לאפשרי.
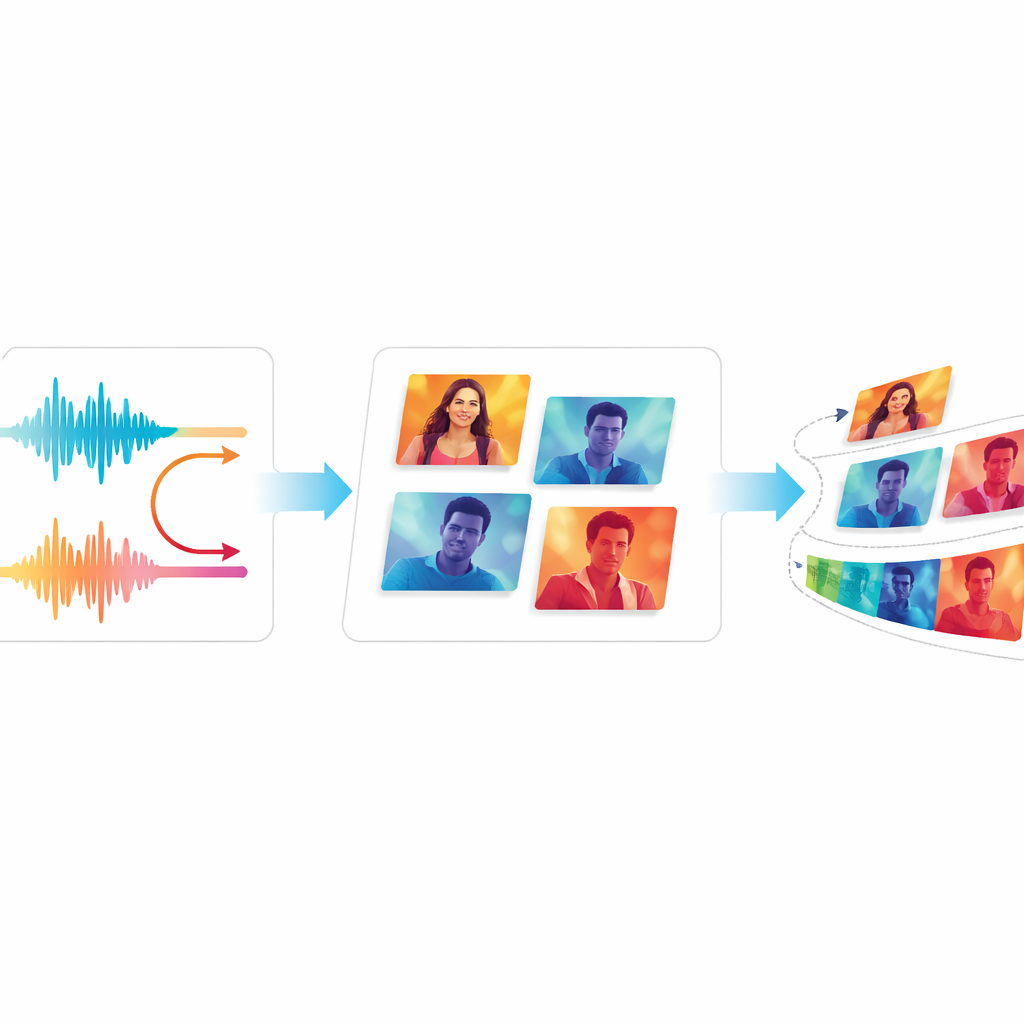
בדיקת איכות וחלקות
כדי לשפוט האם EchoVid אכן משתפרת על מערכות קודמות, המחברים השוו אותה לגנרטורים וידאו ידועים, כולל מודלים בסיסיים מבוססי GAN וכלים מודרניים מבוססי דיפוזיה. הם משתמשים במדדים סטנדרטיים שמשווים וידאו שנוצר לווידאו אמיתי, וכן בשיטת ניקוד שבודקת עד כמה הווידאו תואם תיאורי טקסט. הצוות גם מציג שני מדדים חדשים: אחד עוקב אחר כמה התוכן החזותי נשאר קבוע ממסגרת למסגרת, והשני מעריך עד כמה הבהוב מסיח את הדעת שעלול להיתפס על ידי הצופים. בשני מאגרים נפוצים, EchoVid הציגה ציונים טובים יותר ממערכות ישנות בהתאמה סמנטית ויציבות זמנית, וכל זאת תוך יעילות חישובית. מומחים אנושיים שצפו בקטעי דגימה הסכימו שהסרטונים נראו קוהרנטיים ותאמו היטב את הפרומפטים.
מה זה עשוי לומר למשתמשים היומיומיים
המסר המרכזי של EchoVid הוא שיצירת וידאו איכותית מונחית דיבור היא כעת בהישג יד ללא עלויות אימון מופרזות או צורך במיומנויות עריכה. על ידי המרת תיאורים מדוברים רגילים לווידאוים קצרים המכוונים רגשית, המערכת עשויה לסייע למורים להפוך הרצאות לסיפורים חזותיים, להפוך פודקאסטים למרתקים יותר או לתמוך באנשים עם לקות שמיעה באמצעות סיכומים ויזואליים של שיחות. הכותבים מודים בקשיים שנותרו—כמו טיפול בריבוי שפות, הבעות פנים עדינות וסצנות ארוכות או מורכבות מאוד—אבל התוצאות שלהם מראות ששילוב קפדני של ניתוח דיבור, דיפוזיית תמונה ואינטרפולציית מסגרות חכמה כבר יכול להפיק וידאו משכנע ועם הבנת מצב רוח מתוך קול בלבד.
ציטוט: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
מילות מפתח: יצירת וידאו מ-audio, וידאו מונחה דיבור, בינה מלאכותית יוצרת, Stable Diffusion, סיפור רב-ממדי