Clear Sky Science · sv
AI-driven ljud-till-video-generering för dynamiskt innehållsskapande via stable diffusion och CNN-förstärkta transformatorer
Förvandla röster till rörliga berättelser
Föreställ dig att du talar in i din laptop och omedelbart ser en kort video som fångar inte bara vad du sa, utan också hur du kände när du sa det. Det är löftet från EchoVid, ett nytt artificiellt intelligenssystem som förvandlar talat ljud till korta, känslomässigt medvetna videoklipp. Arbetet ligger i skärningspunkten mellan talteknologi, bildgenerering och videoeffekter, med målet att göra digitalt innehållsskapande lika enkelt som att tala högt.
Varför det är svårt att matcha syn och ljud
Människor kombinerar naturligt tonfall, ansiktsuttryck och omgivande scener för att förstå varandra. Befintliga AI-system som genererar bilder eller videor missar ofta denna rikedom. Många fokuserar på textpromptar och ignorerar hur pauser, tonhöjd eller upphetsning i tal signalerar glädje, sorg eller spänning. Tidigare video-generatorer hade svårt att bibehålla mjuka rörelser över tid och producerade ofta flimrande scener, stela karaktärer eller visuella element som inte riktigt passade ljudet. Dessa brister begränsar verktygens användbarhet för lärare, historieberättare och hjälpteknik som förlitar sig på korrekta, känslomässigt trogna bilder.
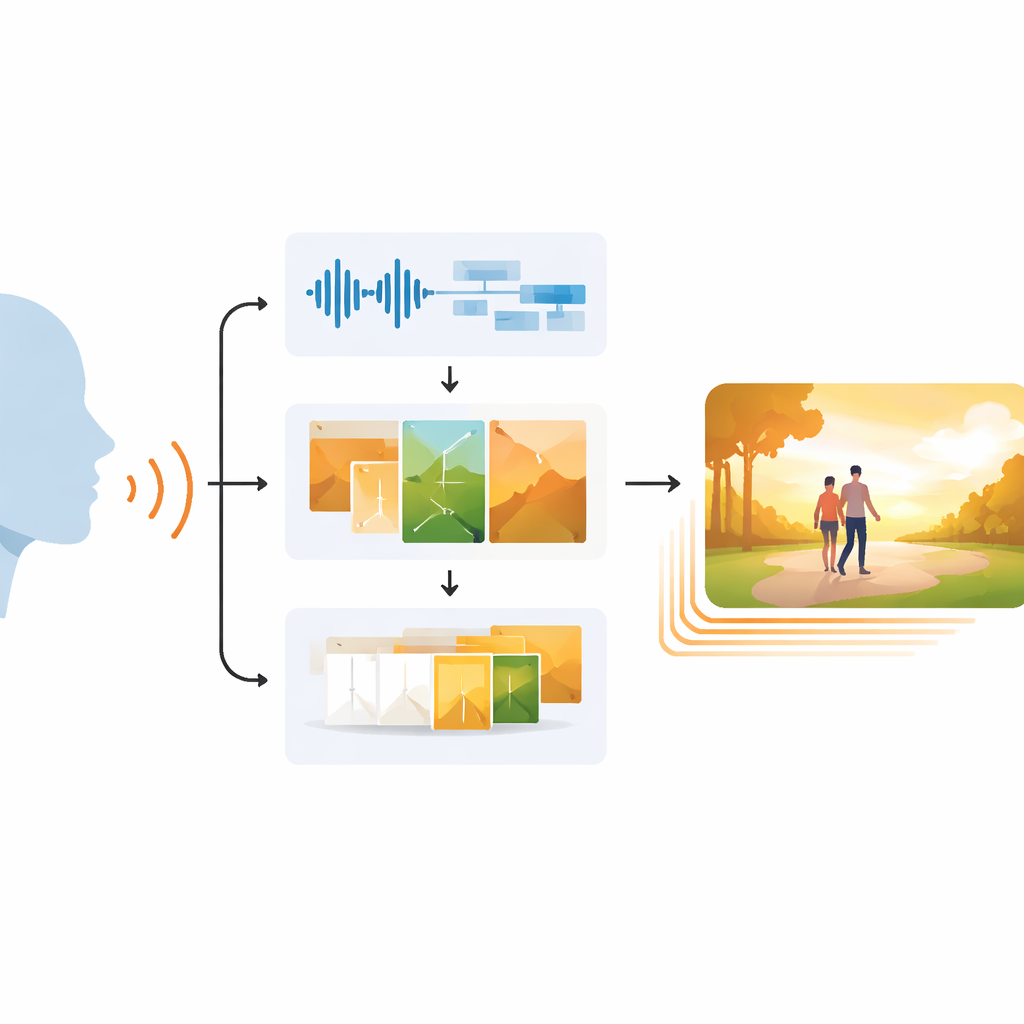
En tredelad väg från tal till video
EchoVid angriper problemet med en trestegs-pipeline. Först lyssnar systemet på en person som talar via en mikrofon. Det rengör ljudet för att reducera bakgrundsbrus och konverterar sedan talet till text samtidigt som det uppskattar vokal stämning utifrån rytm, tonhöjd och intensitet. Därefter blandar det igenkända orden med dessa emotionella ledtrådar för att skapa en rik intern prompt. Denna prompt matchas mot en databas av teman — såsom natur, stadsliv eller fantasy — för att hålla scenen relevant. Med hjälp av en kraftfull bildgenerator känd som Stable Diffusion producerar EchoVid därefter individuella bildrutor som visuellt speglar både vad som sades och hur det sades. Slutligen, i tredje steget, skapar systemet ytterligare mellanliggande rutor i ett särskilt "latent"-utrymme och morfar försiktigt en bild till nästa så att slutvideon känns mjuk snarare än hoppig.
Inne i maskinrummet
Under skalet balanserar EchoVid noggrant kvalitet och hastighet. Talgränssnittet är inställt för att fokusera på det frekvensområde där mänskliga röster finns, vilket minskar igenkänningsfel. Bildgeneratorn körs i en måttlig upplösning som kan skalas upp, vilket håller bearbetningstiden hanterbar samtidigt som skarpa resultat uppnås. Forskarna använder extra prompttips — såsom taggar för konsekventa bakgrunder eller dynamisk rörelse — för att hålla karaktärer och miljöer stabila från ruta till ruta. De undviker också dyra, långsamma tekniker som fullt autoregressiva videotransformatorer och förlitar sig istället på smart interpolation och återanvändning av bildgenereringsverktyg. Som en följd kan EchoVid på ett modernt grafikkort producera färdiga klipp på bara något mer tid än det ursprungliga ljudets längd, vilket gör nära realtidsanvändning tänkbar.
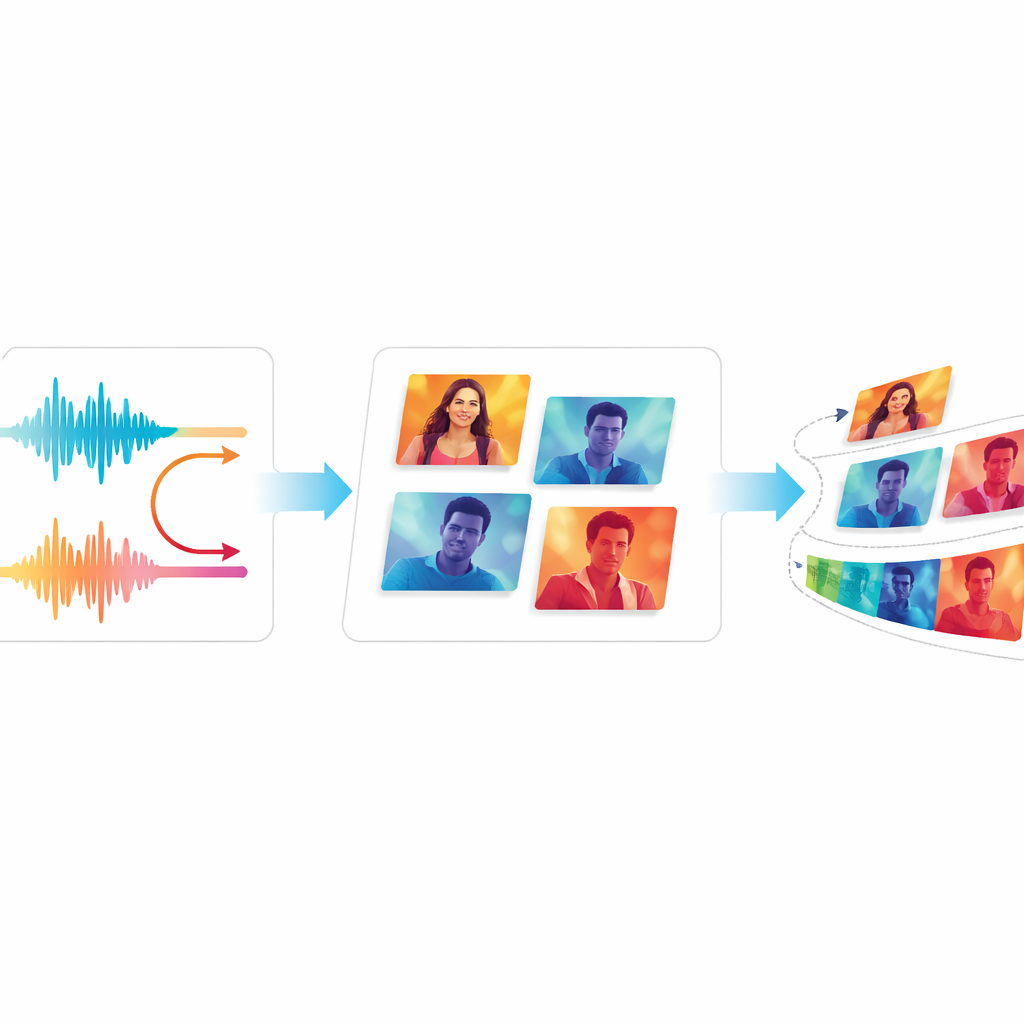
Testning av kvalitet och jämnhet
För att avgöra om EchoVid verkligen förbättrar tidigare system jämför författarna det med välkända videogeneratorer, inklusive klassiska GAN-baserade modeller och moderna diffusionsbaserade verktyg. De använder standardmått som jämför genererade videor med riktiga, samt en poängmetod som kontrollerar hur väl videor stämmer med textbeskrivningar. Teamet introducerar också två nya mått: ett spårar hur konsekvent det visuella innehållet är från ruta till ruta, och det andra uppskattar hur mycket distraherande flimmer tittare kan märka. Över två brett använda videodatamängder presterar EchoVid bättre än äldre system vad gäller semantisk anpassning och temporal stabilitet, samtidigt som det förblir beräkningsmässigt effektivt. Mänskliga experter som tittade på provklipp instämde i att videorna såg koherenta ut och matchade promptarna väl.
Vad detta kan betyda för vardagsanvändare
EchoVids huvudbudskap är att högkvalitativ, talstyrd videogenerering nu är inom räckhåll utan massiva träningskostnader eller redigeringskunskaper. Genom att förvandla vanliga talade beskrivningar till korta, känslomässigt tonade videor kan systemet hjälpa lärare att förvandla föreläsningar till visuella berättelser, göra poddar mer engagerande eller stödja personer med hörselnedsättning genom visuella sammanfattningar av samtal. Författarna erkänner öppna utmaningar — såsom hantering av många språk, finstämda ansiktsuttryck och mycket långa eller komplexa scener — men deras resultat visar att en omsorgsfull kombination av talanalys, bilddiffusion och smart bildrutinterpolation redan kan producera övertygande, stämningsmedveten video från inget annat än rösten.
Citering: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Nyckelord: ljud-till-video-generering, talstyrd video, generativ AI, stable diffusion, multimodalt berättande