Clear Sky Science · it
Generazione audio‑to‑video guidata dall’IA per la creazione di contenuti dinamici tramite stable diffusion e transformer potenziati da CNN
Trasformare le voci in storie in movimento
Immagina di parlare al tuo portatile e di vedere all’istante un breve video che cattura non solo quello che hai detto, ma anche come ti sentivi mentre lo dicevi. Questa è la promessa di EchoVid, un nuovo sistema di intelligenza artificiale che trasforma l’audio parlato in brevi clip video con consapevolezza emotiva. Il lavoro si colloca all’incrocio tra tecnologia del parlato, generazione di immagini ed effetti video, con l’obiettivo di rendere la creazione di contenuti digitali semplice come parlare ad alta voce.
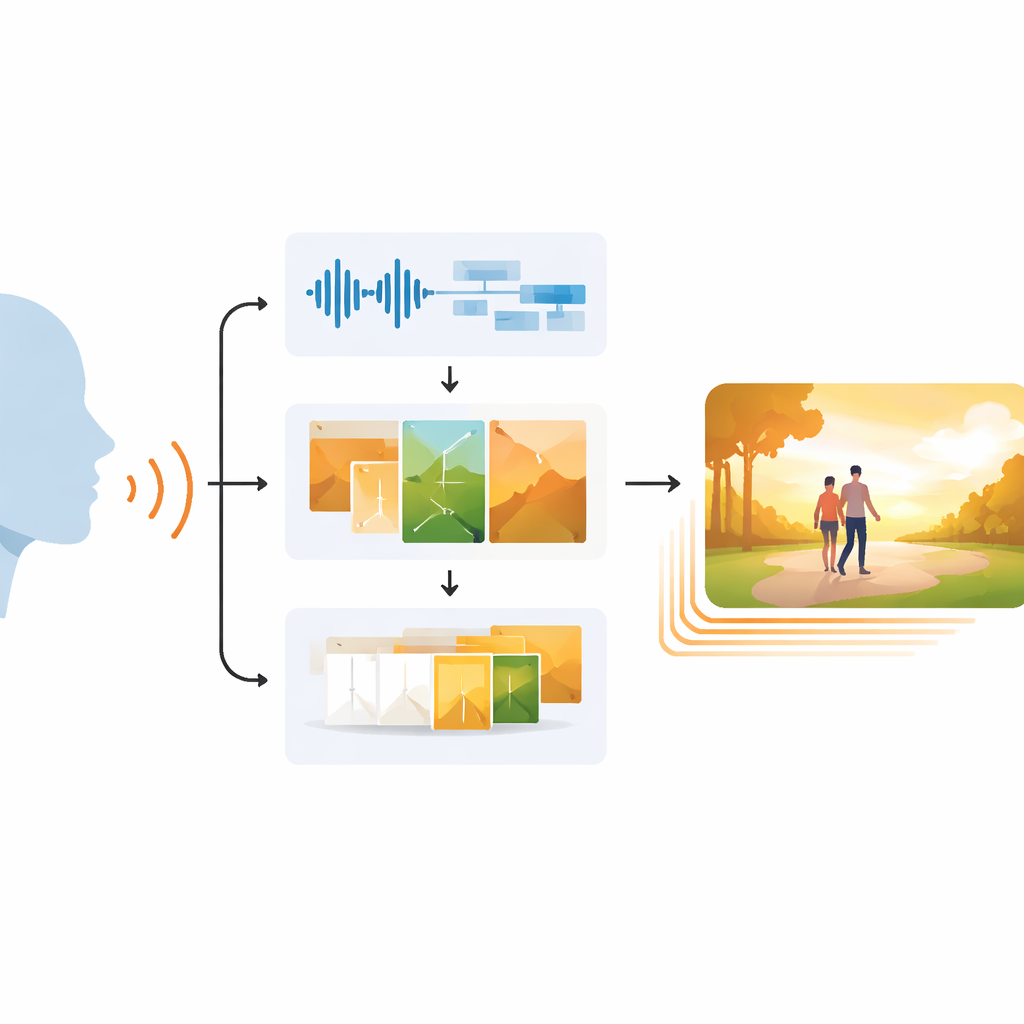
Perché far corrispondere vista e suono è difficile
Le persone combinano naturalmente tono di voce, espressione facciale e scene circostanti per capirsi a vicenda. I sistemi di IA esistenti che generano immagini o video spesso perdono questa ricchezza. Molti si concentrano su prompt testuali scritti, ignorando come pause, intonazione o entusiasmo nel parlato segnalino gioia, tristezza o suspense. I generatori video precedenti faticavano a mantenere il movimento fluido nel tempo, producendo spesso scene sfarfallanti, personaggi rigidi o immagini che non si adattavano realmente al suono. Queste lacune limitano l’utilità di tali strumenti per insegnanti, narratori e tecnologie assistive che fanno affidamento su visuali accurate ed emotivamente fedeli.
Un percorso in tre fasi dal parlato al video
EchoVid affronta il problema con una pipeline in tre stadi. Per prima cosa, il sistema ascolta una persona che parla tramite microfono. Pulisce l’audio per ridurre il rumore di fondo e poi converte il parlato in testo stimando al contempo l’umore vocale da ritmo, pitch e intensità. In secondo luogo, fonde le parole riconosciute con questi segnali emotivi per costruire un prompt interno ricco. Quel prompt viene confrontato con un database di temi — come natura, vita cittadina o fantasy — per mantenere la scena coerente con l’argomento. Usando un potente generatore di immagini noto come Stable Diffusion, EchoVid produce quindi singoli fotogrammi che riflettono visivamente sia ciò che è stato detto sia come è stato detto. Infine, nel terzo stadio, il sistema crea fotogrammi intermedi in uno speciale spazio «latente», trasformando dolcemente un’immagine nell’altra in modo che il video finale risulti fluido anziché scattoso.
Dentro la sala macchine
Sotto il cofano, EchoVid bilancia con cura qualità e velocità. Il front end del parlato è ottimizzato per concentrarsi sulla gamma di frequenze in cui vivono le voci umane, il che aiuta a ridurre gli errori di riconoscimento. Il generatore di immagini opera a una risoluzione moderata che può essere ingrandita, mantenendo i tempi di elaborazione gestibili pur producendo risultati nitidi. I ricercatori utilizzano indizi extra nel prompt — come tag per sfondi coerenti o movimento dinamico — per mantenere stabili personaggi e ambientazioni da un fotogramma all’altro. Evitano inoltre tecniche costose e lente come i transformer video completamente autoritativi e si affidano invece a interpolazione intelligente e al riutilizzo di strumenti di generazione d’immagini. Di conseguenza, su una moderna scheda grafica, EchoVid può produrre clip finite in poco più tempo rispetto alla durata dell’audio originale, rendendo concepibile un uso quasi in tempo reale.
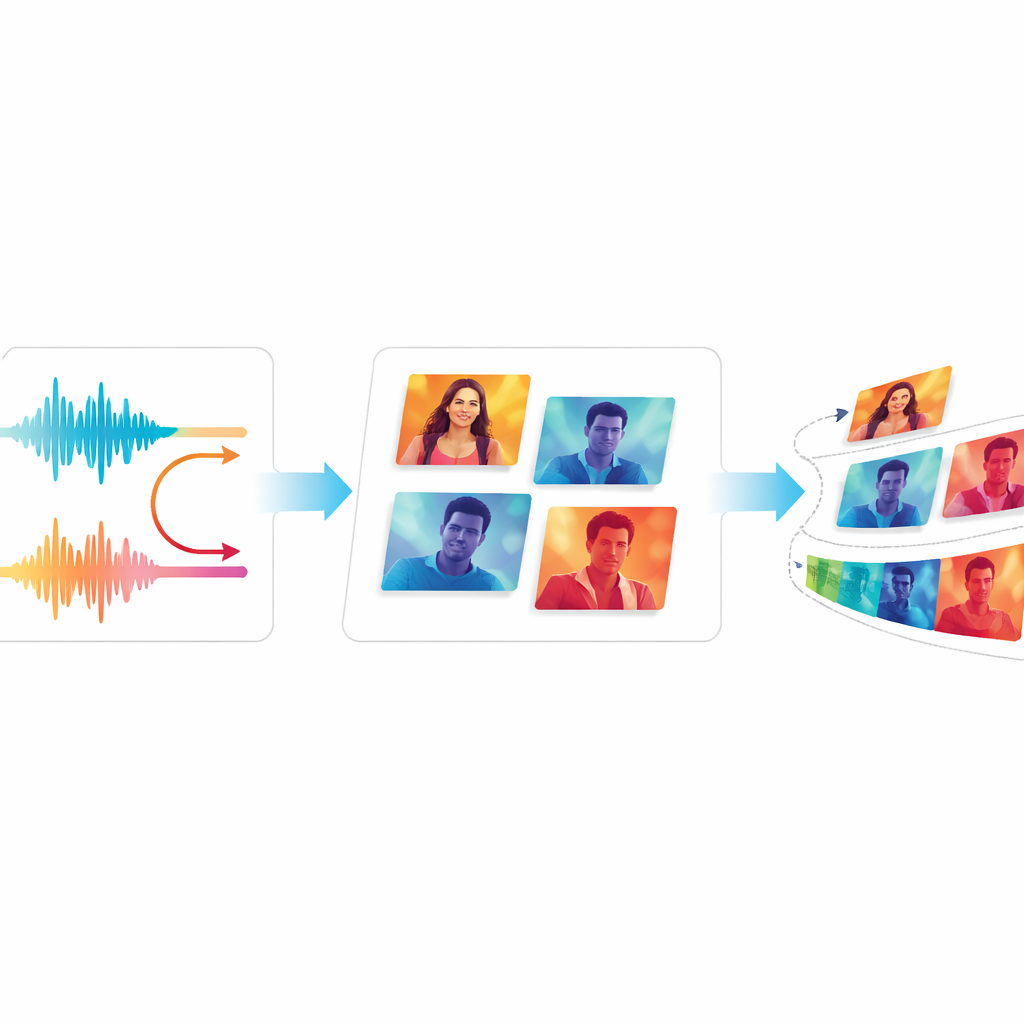
Testare qualità e fluidità
Per valutare se EchoVid migliora veramente rispetto ai sistemi precedenti, gli autori lo mettono a confronto con noti generatori video, inclusi modelli classici basati su GAN e strumenti moderni basati su diffusion. Usano misure standard che confrontano i video generati con quelli reali, oltre a un metodo di valutazione che verifica quanto i video corrispondano alle descrizioni testuali. Il team introduce anche due nuove misure: una monitora quanto il contenuto visivo rimane coerente fotogramma dopo fotogramma, e l’altra stima quanto sfarfallio distraente gli spettatori potrebbero notare. Su due dataset video ampiamente usati, EchoVid ottiene risultati migliori rispetto ai sistemi più vecchi in allineamento semantico e stabilità temporale, restando al contempo efficiente dal punto di vista computazionale. Esperti umani che hanno visto clip campione hanno concordato che i video apparivano coerenti e ben aderenti ai prompt.
Cosa potrebbe significare per gli utenti comuni
Il messaggio principale di EchoVid è che la generazione video di alta qualità guidata dal parlato è ora alla portata senza costi di addestramento massivi o competenze di montaggio. Trasformando descrizioni parlate ordinarie in brevi video sintonizzati emotivamente, il sistema potrebbe aiutare insegnanti a trasformare lezioni in storie visive, rendere più coinvolgenti i podcast o supportare persone con perdita uditiva attraverso riepiloghi visivi delle conversazioni. Gli autori riconoscono sfide aperte — come gestire molte lingue, espressioni facciali molto dettagliate e scene molto lunghe o complesse — ma i risultati mostrano che combinare con cura analisi del parlato, diffusion di immagini e interpolazione intelligente dei fotogrammi può già produrre video convincenti e sensibili all’umore partendo dal semplice suono di una voce.
Citazione: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Parole chiave: generazione audio‑to‑video, video guidato dal parlato, IA generativa, stable diffusion, narrazione multimodale