Clear Sky Science · ru
Генерация видео на основе аудио с использованием ИИ для динамичного создания контента через stable diffusion и CNN-усиленные трансформеры
Преобразование голосов в движущиеся истории
Представьте, что вы говорите в свой ноутбук и мгновенно видите короткое видео, которое передаёт не только сказанное, но и то, как вы это чувствовали. Именно это обещает EchoVid — новая система искусственного интеллекта, превращающая устное аудио в короткие эмоционально окрашенные видеоклипы. Работа находится на стыке речевых технологий, генерации изображений и видеоеффектов и нацелена на то, чтобы сделать создание цифрового контента таким же простым, как говорить вслух.
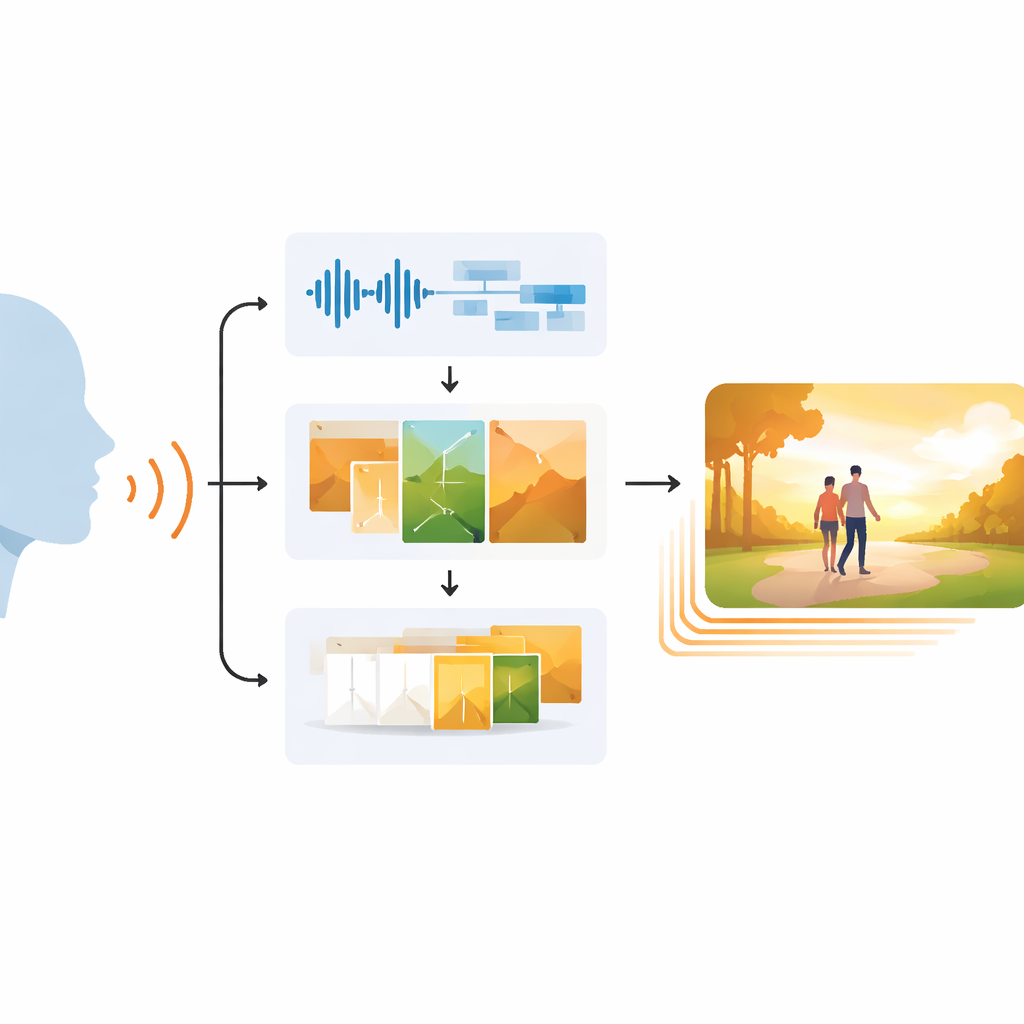
Почему согласование зрения и звука трудно
Люди естественно объединяют интонацию, мимику и окружающую сцену, чтобы понимать друг друга. Существующие ИИ-системы, генерирующие изображения или видео, часто упускают эту богатую палитру. Многие ориентируются на текстовые подсказки, игнорируя паузы, высоту голоса или возбуждение в речи, которые сигнализируют радость, печаль или напряжение. Ранние видеогенераторы испытывали сложности с плавностью движений во времени, часто порождая мерцающие сцены, застывших персонажей или визуалы, плохо сочетающиеся со звуком. Эти пробелы ограничивают полезность таких инструментов для преподавателей, рассказчиков и вспомогательных технологий, которые зависят от точной, эмоционально верной визуализации.
Трёхэтапный путь от речи к видео
EchoVid решает эту задачу через триэтапный конвейер. Сначала система слушает говорящего через микрофон. Она очищает аудио от фонового шума, затем преобразует речь в текст и одновременно оценивает вокальное настроение по ритму, высоте и интенсивности. Во втором этапе распознанные слова смешиваются с эмоциональными сигналами для составления подробной внутренней подсказки. Эта подсказка сопоставляется с базой тем — например, природа, городская жизнь или фэнтези — чтобы сцена оставалась в рамках темы. С помощью мощного генератора изображений, известного как Stable Diffusion, EchoVid затем создает отдельные кадры, которые визуально отражают и содержание сказанного, и эмоцию, с которой оно было произнесено. Наконец, на третьем этапе система генерирует дополнительные «промежуточные» кадры в специальном «латентном» пространстве, плавно превращая одно изображение в следующее, чтобы итоговое видео выглядело гладким, а не дерганым.
Внутри движка
Под капотом EchoVid аккуратно балансирует качество и скорость. Речевой фронтенд настроен на частотный диапазон, характерный для человеческого голоса, что помогает снизить количество ошибок распознавания. Генератор изображений работает на умеренном разрешении, которое можно увеличить, сохраняя приемлемое время обработки и при этом получая чёткие результаты. Исследователи используют дополнительные подсказки — например, теги для согласованных фонов или динамического движения — чтобы персонажи и окружение оставались стабильными от кадра к кадру. Они также избегают дорогих и медленных техник, таких как полностью авторегрессивные видеотрансформеры, и вместо этого полагаются на хитрую интерполяцию и повторное использование инструментов генерации изображений. В результате на современной графической карте EchoVid может производить готовые клипы всего за немного больше времени, чем длится исходное аудио, делая практически реалистичным использование в режиме близком к реальному времени.
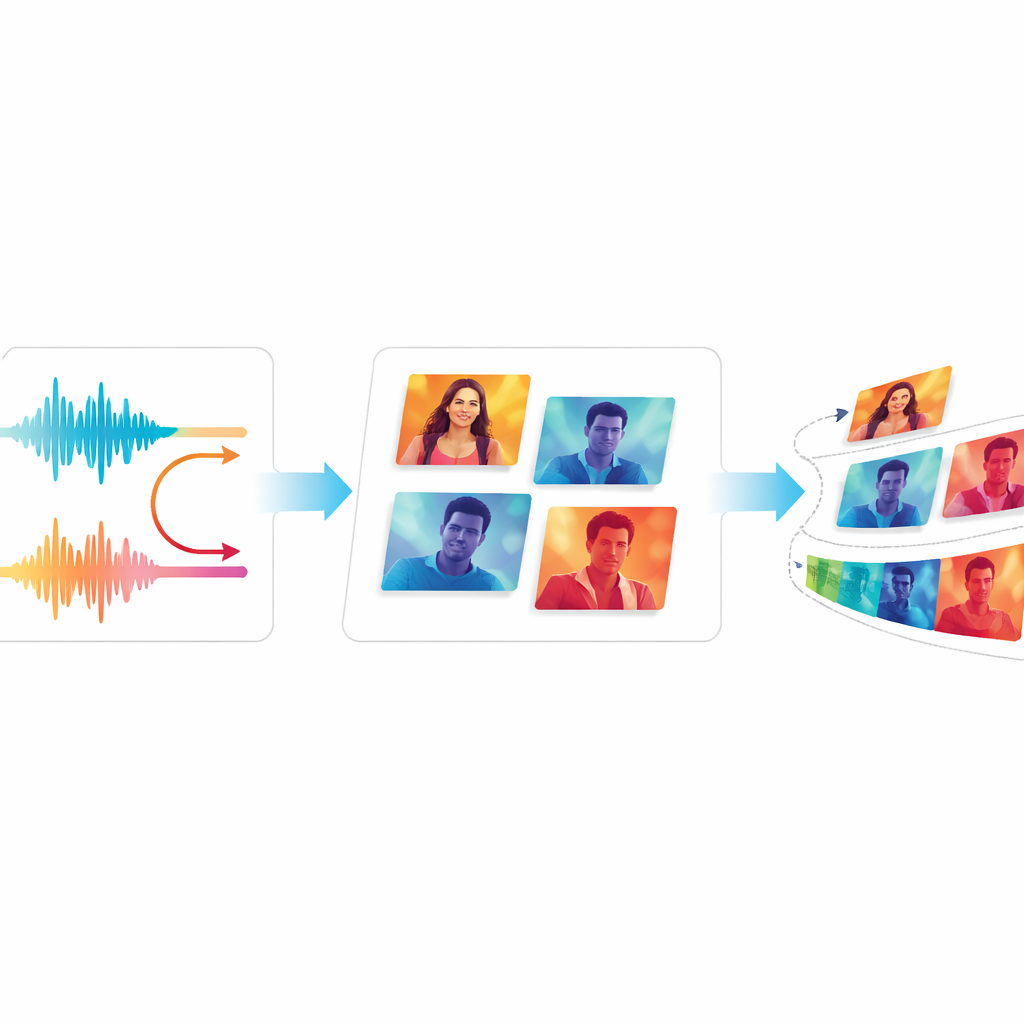
Тестирование качества и плавности
Чтобы оценить, действительно ли EchoVid превосходит прошлые системы, авторы сравнили его с известными видеогенераторами, включая классические модели на основе GAN и современные инструменты на основе диффузии. Они используют стандартные метрики, сопоставляющие сгенерированные видео с реальными, а также метод оценки, проверяющий, насколько точно видео соответствует текстовым описаниям. Команда также вводит две новые метрики: одна отслеживает, насколько последовательно сохраняется визуальный контент от кадра к кадру, а другая оценивает, насколько заметным может быть отвлекающее мерцание для зрителей. На двух широко используемых видеодатасетах EchoVid показал лучшие результаты по семантическому соответствию и временной стабильности, оставаясь при этом вычислительно эффективным. Эксперты‑люди, просмотревшие образцы, пришли к выводу, что видео выглядят целостными и хорошо соответствуют подсказкам.
Что это может значить для повседневных пользователей
Главная идея EchoVid — высококачественная генерация видео по речи теперь доступна без огромных затрат на обучение или навыков монтажа. Превращая обычные устные описания в короткие видеоролики с учётом настроения, система может помочь преподавателям превращать лекции в визуальные истории, сделать подкасты более увлекательными или поддержать людей с нарушениями слуха через визуальные сводки разговоров. Авторы признают существующие проблемы — например, работу со множеством языков, тонкую передачу мимики и очень длинные или сложные сцены — но их результаты показывают, что тщательное сочетание анализа речи, диффузии изображений и интеллектуальной интерполяции кадров уже способно создавать убедительное, настроенческое видео, исходя лишь из звука голоса.
Цитирование: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Ключевые слова: генерация аудио-видео, видео, управляемое речью, генеративный ИИ, stable diffusion, мультимодальное повествование