Clear Sky Science · tr
Dinamik içerik oluşturma için kararlı difüzyon ve CNN destekli dönüştürücüler aracılığıyla sesten videoya AI destekli üretim
Sesleri Hareketli Hikâyelere Dönüştürmek
Dizüstü bilgisayarınıza konuştuğunuzu hayal edin ve hemen sadece söylediklerinizi değil, bunu söylerken nasıl hissettiğinizi de yakalayan kısa bir video izliyorsunuz. Bu, konuşulan sesi kısa, duyguya duyarlı video kliplere dönüştüren yeni bir yapay zeka sistemi olan EchoVid’in vaadidir. Bu çalışma konuşma teknolojisi, görüntü üretimi ve video efektlerinin kesişiminde yer alır ve dijital içerik oluşturmayı yüksek sesle konuşmak kadar basit hale getirmeyi amaçlar.
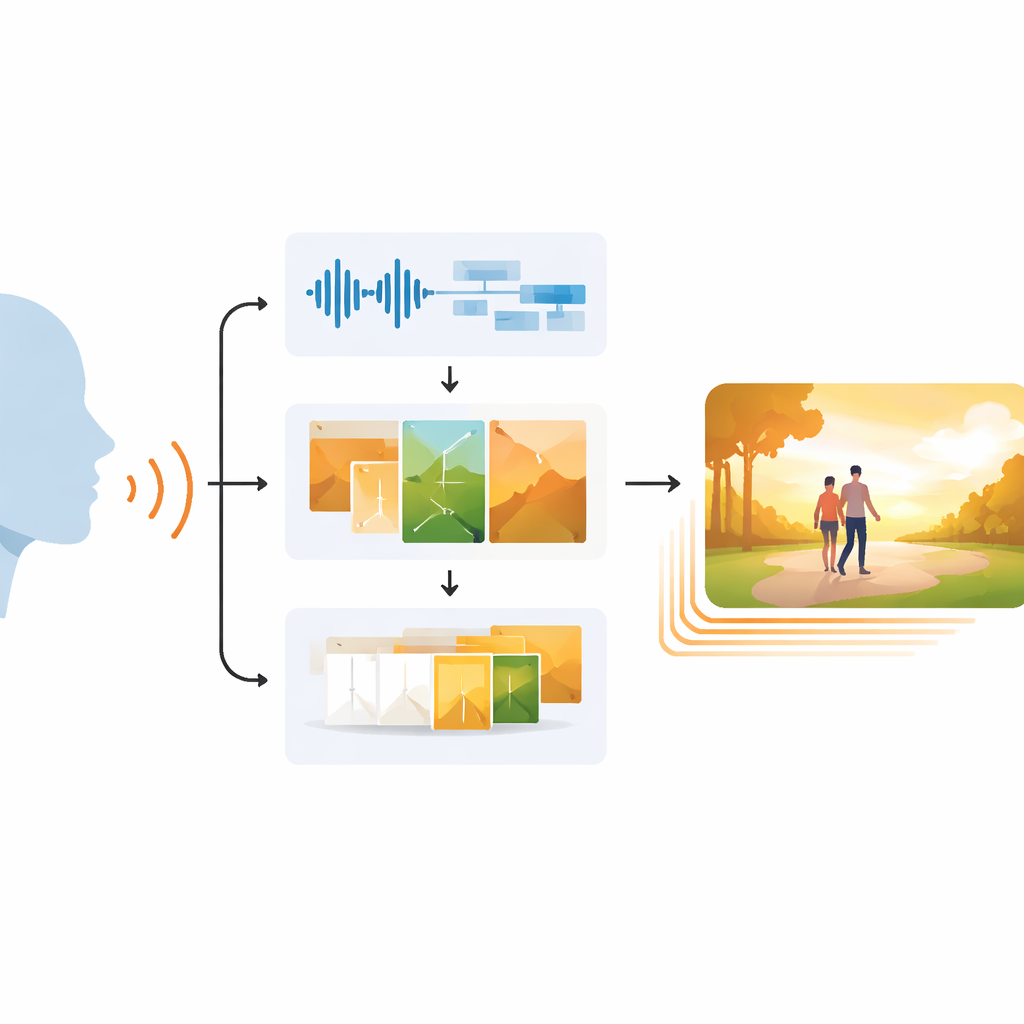
Görsellik ve İşitselliği Eşleştirmek Neden Zordur
İnsanlar birbirlerini anlamak için doğal olarak ses tonu, yüz ifadeleri ve çevredeki sahneleri birleştirir. Görüntü veya video üreten mevcut yapay zeka sistemleri sıklıkla bu zenginliği kaçırır. Birçoğu yazılı metin istemlerine odaklanır; konuşmadaki duraklamalar, perde aralığı veya heyecan gibi unsurların sevinç, üzüntü veya gerilim sinyali verdiğini göz ardı eder. Önceki video üreticileri hareketi zaman içinde düzgün tutmakta zorlanır, genellikle titreyen sahneler, sert karakterler veya sese gerçekten uymayan görseller üretir. Bu eksiklikler, öğretmenler, hikâye anlatıcılar ve doğru, duyguya sadık görsellere dayanan yardımcı teknolojiler için bu araçların kullanılabilirliğini sınırlar.
Konuşmadan Videoya Üç Aşamalı Yol
EchoVid bu sorunu üç aşamalı bir hat ile ele alır. İlk olarak sistem bir mikrofondan konuşan kişiyi dinler. Arkaplan gürültüsünü azaltmak için sesi temizler ve ardından konuşmayı yazıya çevirirken ritim, perde ve yoğunluktan vokal ruh halini de tahmin eder. İkinci olarak tanınan kelimeleri bu duygusal ipuçlarıyla harmanlayıp zengin bir iç istem oluşturur. Bu istem, sahnenin konuya uygun kalmasını sağlamak için doğa, şehir yaşamı veya fantazi gibi temalar içeren bir veritabanıyla eşleştirilir. Güçlü bir görüntü üreteci olan Stable Diffusion kullanılarak EchoVid, hem söylenenleri hem de bunların nasıl söylendiğini görsel olarak yansıtan tek tek kareler üretir. Son olarak üçüncü aşamada sistem, özel bir “latent” (gizil) uzayda ek ara kareler yaratarak bir görüntünün diğerine nazikçe dönüşmesini sağlar, böylece son video atlamalı değil akıcı hisseder.
Motor Odasının İçinde
Kaputun altında EchoVid kalite ile hızı dikkatlice dengeler. Konuşma önyüzü insan seslerinin bulunduğu frekans aralığına odaklanacak şekilde ayarlanmıştır; bu da tanıma hatalarını azaltmaya yardımcı olur. Görüntü üreteci, yükseltilebilen orta düzeyde bir çözünürlükte çalışır; bu, işlem süresini yönetilebilir kılarken yine de keskin sonuçlar üretir. Araç, kareden kareye karakterleri ve ortamları tutarlı tutmak için tutarlı arka planlar veya dinamik hareket için etiketler gibi ekstra istem ipuçları kullanır. Ayrıca tamamen otoregresif video dönüştürücüleri gibi pahalı, yavaş tekniklerden kaçınır ve bunun yerine akıllı enterpolasyon ve görüntü üretim araçlarının yeniden kullanımına dayanır. Sonuç olarak, modern bir grafik kartında EchoVid, bitmiş klipleri orijinal sesin süresinden yalnızca biraz daha fazla bir sürede üretebilir; bu da neredeyse gerçek zamanlı kullanımın düşünülebilir olduğu anlamına gelir.
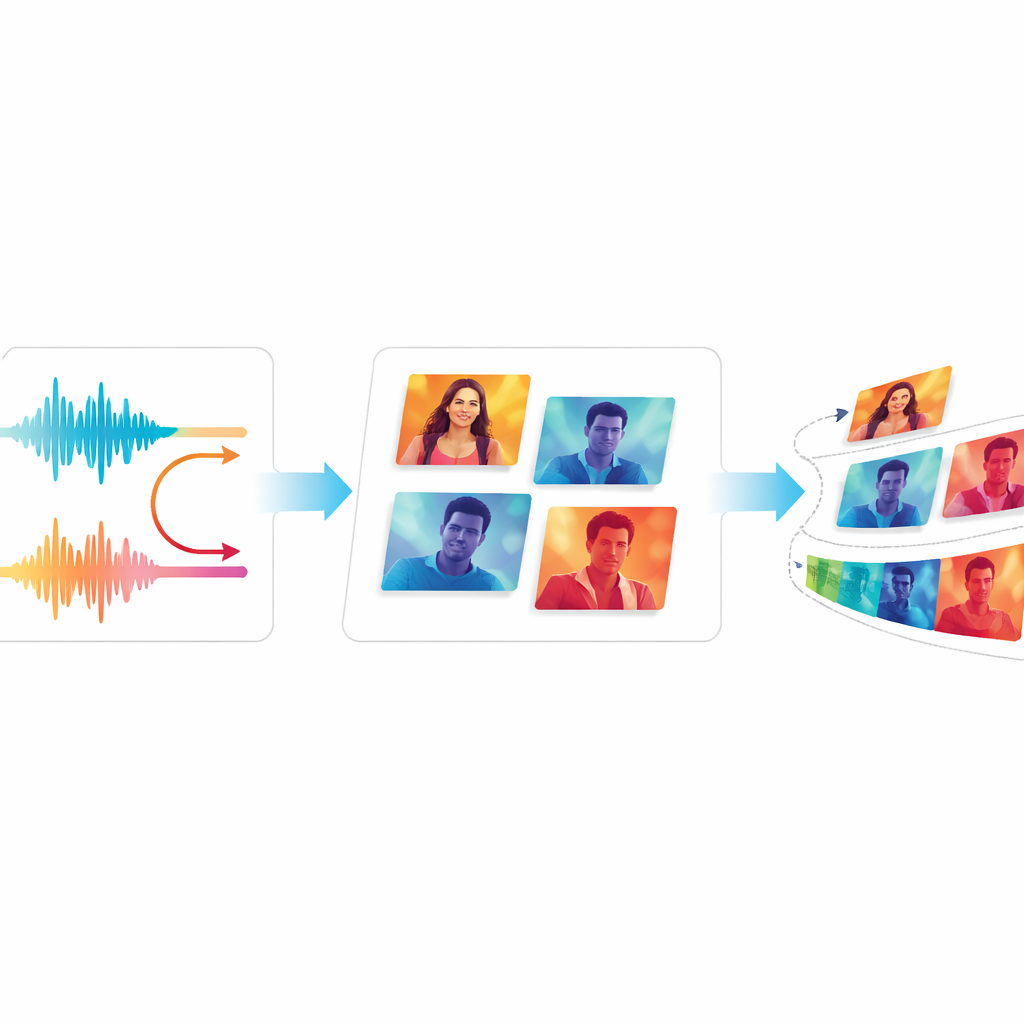
Kalite ve Akıcılığı Test Etmek
EchoVid’in gerçekten geçmiş sistemlerden daha iyi olup olmadığını değerlendirmek için yazarlar onu klasik GAN tabanlı modeller ve modern difüzyon tabanlı araçlar da dahil olmak üzere iyi bilinen video üreticilere karşı kıyaslar. Üretilen videoları gerçeklerle karşılaştıran standart ölçütler ile videoların metin betimlemelerine ne kadar yakın olduğunu kontrol eden bir puanlama yöntemi kullanırlar. Ekip ayrıca iki yeni ölçüt tanıtır: biri görsel içeriğin kareden kareye ne kadar tutarlı kaldığını izler, diğeri izleyicilerin fark edebileceği rahatsız edici titremeyi tahmin eder. İki yaygın kullanılan video veri kümesi genelinde EchoVid, anlamsal uyum ve zamansal kararlılık açısından eski sistemlerden daha iyi puanlar alırken hesaplamalı verimliliği korur. Örnek klipleri izleyen insan uzmanlar da videoların tutarlı göründüğü ve istemlerle iyi eşleştiği konusunda hemfikirdir.
Günlük Kullanıcılar İçin Ne Anlama Gelebilir
EchoVid’in ana mesajı, yüksek kaliteli, konuşma ile yönlendirilen video üretiminin artık muazzam eğitim maliyetleri veya düzenleme becerileri olmadan ulaşılabilir olduğu yönündedir. Sıradan konuşulan betimlemeleri kısa, duyguya göre ayarlanmış videolara dönüştürerek sistem, öğretmenlerin dersleri görsel hikâyelere dönüştürmesine yardımcı olabilir, podcast’leri daha ilgi çekici hale getirebilir veya konuşmaların görsel özetleriyle işitme engelli insanları destekleyebilir. Yazarlar birçok dilin işlenmesi, ince yüz ifadeleri ve çok uzun veya karmaşık sahnelerin ele alınması gibi açık zorlukları kabul eder; ancak elde ettikleri sonuçlar, konuşma analizi, görüntü difüzyonu ve akıllı kare enterpolasyonunun dikkatlice birleştirilmesinin yalnızca bir ses kaydından bile ikna edici, ruh haline duyarlı videolar üretebileceğini gösterir.
Atıf: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Anahtar kelimeler: sesten videoya üretim, konuşma ile yönlendirilen video, üretken yapay zeka, kararlı difüzyon, çokmodlu hikâye anlatımı