Clear Sky Science · ar
توليد فيديو من الصوت مدفوع بالذكاء الاصطناعي لإنشاء محتوى ديناميكي عبر الانتشار المستقر ومحولات معززة بشبكات CNN
تحويل الأصوات إلى قصص متحركة
تخيل أن تتكلم في حاسوبك المحمول وتشاهد فورًا مقطع فيديو قصيرًا يلتقط ليس ما قلته فحسب، بل شعورك أثناء قوله أيضًا. هذا هو وعد EchoVid، نظام ذكاء اصطناعي جديد يحول الصوت المنطوق إلى مقاطع فيديو قصيرة مدركة عاطفيًا. يقع العمل عند تقاطع تكنولوجيا الكلام، وتوليد الصور، وتأثيرات الفيديو، ويهدف إلى جعل إنشاء المحتوى الرقمي سهلاً مثل النطق.
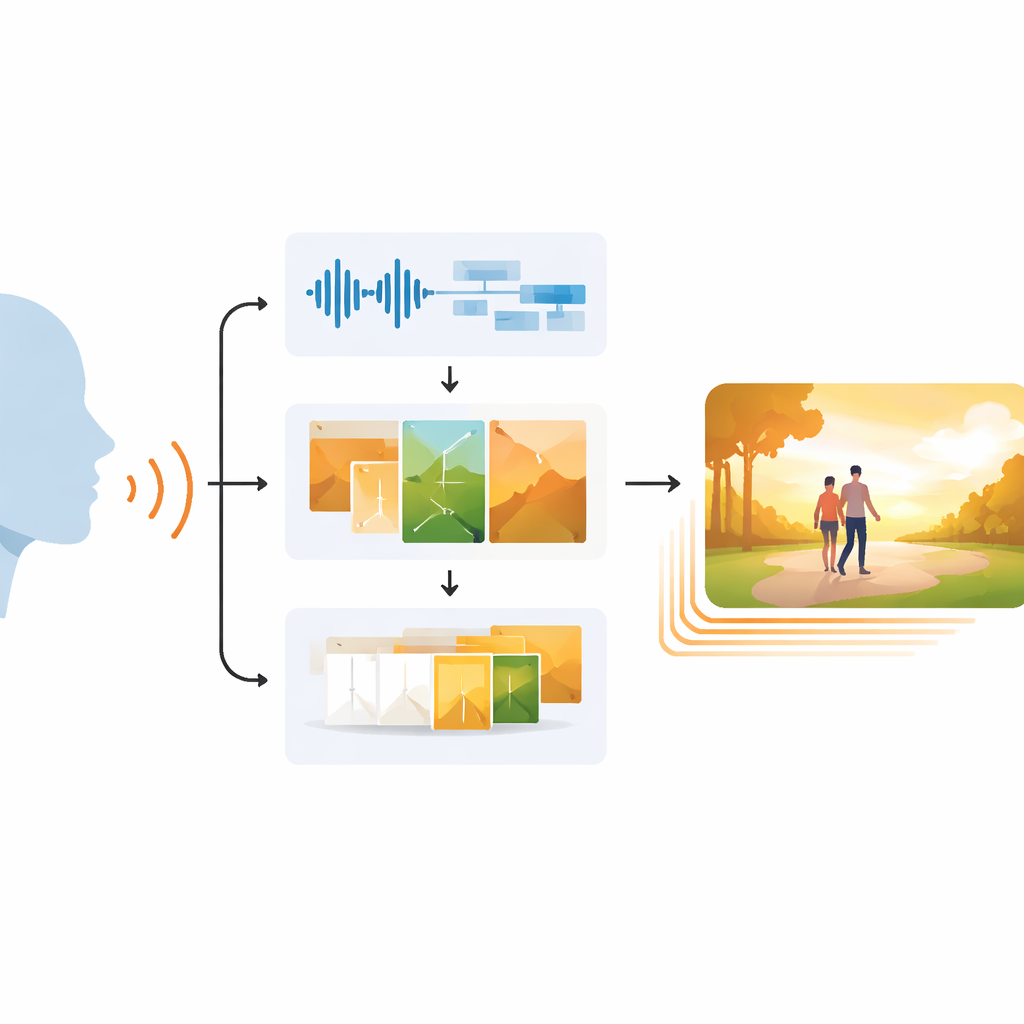
لماذا من الصعب مطابقة البصر مع الصوت
الناس يجمعون طبيعيًا نبرة الصوت، وتعابير الوجه، والمشاهد المحيطة لفهم بعضهم بعضًا. كثير من أنظمة الذكاء الاصطناعي الحالية التي تولد صورًا أو فيديوهات تفقد هذا الثراء. يركز العديد منها على مطالبات نصية مكتوبة، متجاهلاً كيف تشير التوقفات، والطبقة، أو الحماس في الكلام إلى الفرح أو الحزن أو التوتر. كانت مولدات الفيديو السابقة تكافح للحفاظ على سلاسة الحركة مع الزمن، وغالبًا ما تنتج مشاهد متقطعة، أو شخصيات جامدة، أو مرئيات لا تتناسب حقًا مع الصوت. هذه الفجوات تحد من فائدة مثل هذه الأدوات للمعلمين، ورواة القصص، وتقنيات المساعدة التي تعتمد على مرئيات دقيقة ومو faithfulة عاطفيًا.
مسار من ثلاث خطوات من الكلام إلى الفيديو
يتعامل EchoVid مع هذه المشكلة عبر خط أنابيب مكوّن من ثلاث مراحل. أولاً، يستمع النظام إلى المتحدث عبر ميكروفون. يقوم بتنقية الصوت لتقليل ضوضاء الخلفية ثم يحوّل الكلام إلى نص مع تقدير المزاج الصوتي من الإيقاع، والطبقة، والشدة. ثانيًا، يمزج الكلمات المعترَف بها مع هذه الإشارات العاطفية لصياغة مطالبة داخلية غنية. تُطابِق هذه المطالبة قاعدة بيانات من الموضوعات—مثل الطبيعة، أو حياة المدينة، أو الفانتازيا—للحفاظ على اتساق المشهد مع الموضوع. باستخدام مولد صور قوي يعرف باسم Stable Diffusion، ينتج EchoVid بعد ذلك إطارات فردية تعكس بصريًا ما قيل وكيف قيل. أخيرًا، في المرحلة الثالثة، ينشئ النظام إطارات وسيطة إضافية في فضاء "كامنة" خاص، محوّلًا برفق صورة إلى أخرى بحيث يبدو الفيديو النهائي سلسًا بدلًا من قفزيته.
داخل غرفة المحرك
تحت الغطاء، يوازن EchoVid بعناية بين الجودة والسرعة. تم ضبط واجهة الكلام للتركيز على نطاق التردد الذي تعيش فيه الأصوات البشرية، مما يساعد على تقليل أخطاء التعرف. يعمل مولد الصور بدقة معتدلة يمكن تكبيرها، مما يحافظ على وقت المعالجة قابلًا للإدارة مع إنتاج نتائج حادة. يستخدم الباحثون تلميحات مطالبة إضافية—مثل الوسوم لخلفيات متسقة أو حركة ديناميكية—للحفاظ على ثبات الشخصيات والإعدادات من إطار لآخر. كما يتجنبون تقنيات باهظة وبطيئة مثل محولات الفيديو التوليدية التلقائية بالكامل ويعتمدون بدلًا من ذلك على استيفاء ذكي وإعادة استخدام أدوات توليد الصور. ونتيجة لذلك، على بطاقة رسومات حديثة، يستطيع EchoVid إنتاج مقاطع جاهزة في وقت يزيد قليلاً فقط عن مدة الصوت الأصلي، مما يجعل الاستخدام في الوقت شبه الحقيقي قابلاً للتخيل.
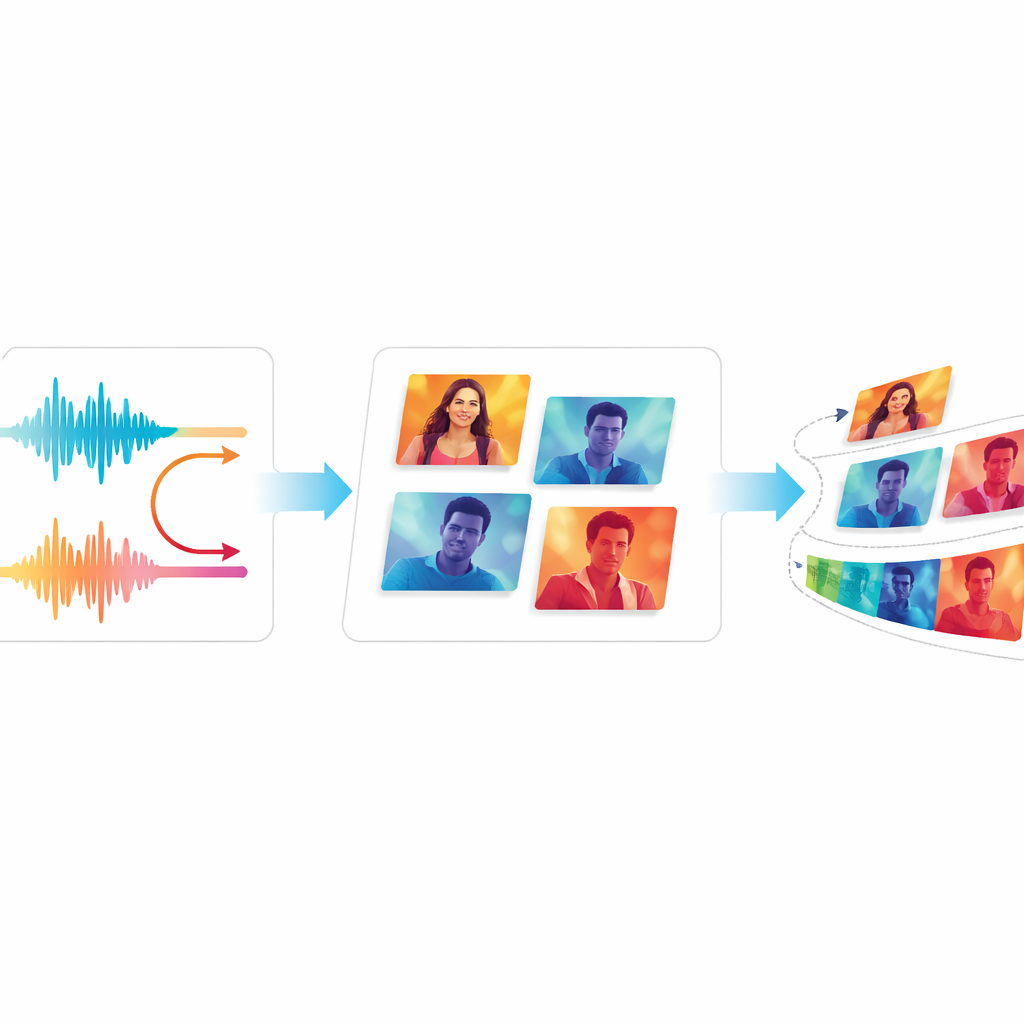
اختبار الجودة والسلاسة
لتقييم ما إذا كان EchoVid يتحسن فعلاً على الأنظمة السابقة، يقارن المؤلفون أداءه مع مولدات فيديو معروفة، بما في ذلك نماذج قائمة على GAN الكلاسيكية وأدوات حديثة قائمة على الانتشار. يستخدمون مقاييس معيارية تقارن الفيديوهات المولدة بالأصلية، بالإضافة إلى طريقة تسجيل تقيس مدى مطابقة الفيديو للنص الوصفي. قدّم الفريق أيضًا مقياسين جديدين: أحدهما يتعقّب مدى بقاء المحتوى البصري ثابتًا من إطار لآخر، والآخر يقدّر مقدار الوميض المشتت الذي قد يلاحظه المشاهدون. عبر مجموعتي بيانات فيديو مستخدمتين على نطاق واسع، يحقق EchoVid درجات أفضل من الأنظمة القديمة في المحاذاة الدلالية والثبات الزمني، كل ذلك مع الحفاظ على كفاءة حسابية. ووافق خبراء بشريون شاهدوا مقاطع عيّنة أن الفيديوهات بدت متماسكة وتطابقت جيدًا مع المطالبات.
ماذا قد يعني هذا للمستخدمين اليوميين
الرسالة الرئيسية لـ EchoVid هي أن توليد فيديو عالي الجودة مدفوع بالكلام بات الآن في المتناول دون تكاليف تدريب هائلة أو مهارات تحرير متقدمة. من خلال تحويل الأوصاف المنطوقة العادية إلى فيديوهات قصيرة مضبوطة عاطفيًا، يمكن للنظام مساعدة المعلمين على تحويل المحاضرات إلى قصص بصرية، وجعل البودكاست أكثر جذبًا، أو دعم الأشخاص ضعاف السمع من خلال ملخصات بصرية للمحادثات. يعترف المؤلفون بالتحديات المفتوحة—مثل التعامل مع لغات عديدة، وتعابير وجه دقيقة، والمشاهد الطويلة أو المعقدة جدًا—لكن نتائجهم تُظهر أن الجمع الدقيق بين تحليل الكلام، وانتشار الصور، واستيفاء الإطارات الذكي يمكنه بالفعل إنتاج فيديو مقنع وواعٍ بالمزاج من لا شيء سوى صوت الإنسان.
الاستشهاد: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
الكلمات المفتاحية: توليد من الصوت إلى الفيديو, فيديو مدفوع بالكلام, الذكاء الاصطناعي التوليدي, الانتشار المستقر, السرد متعدد الوسائط