Clear Sky Science · es
Generación de audio a vídeo impulsada por IA para creación dinámica de contenido mediante stable diffusion y transformadores aumentados con CNN
Convertir voces en historias en movimiento
Imagínese hablar frente al portátil y ver al instante un breve vídeo que captura no solo lo que dijo, sino cómo se sintió al decirlo. Esa es la promesa de EchoVid, un nuevo sistema de inteligencia artificial que transforma audio hablado en clips de vídeo cortos con sensibilidad emocional. El trabajo se sitúa en la intersección de la tecnología del habla, la generación de imágenes y los efectos de vídeo, con el objetivo de hacer la creación de contenido digital tan simple como hablar en voz alta.
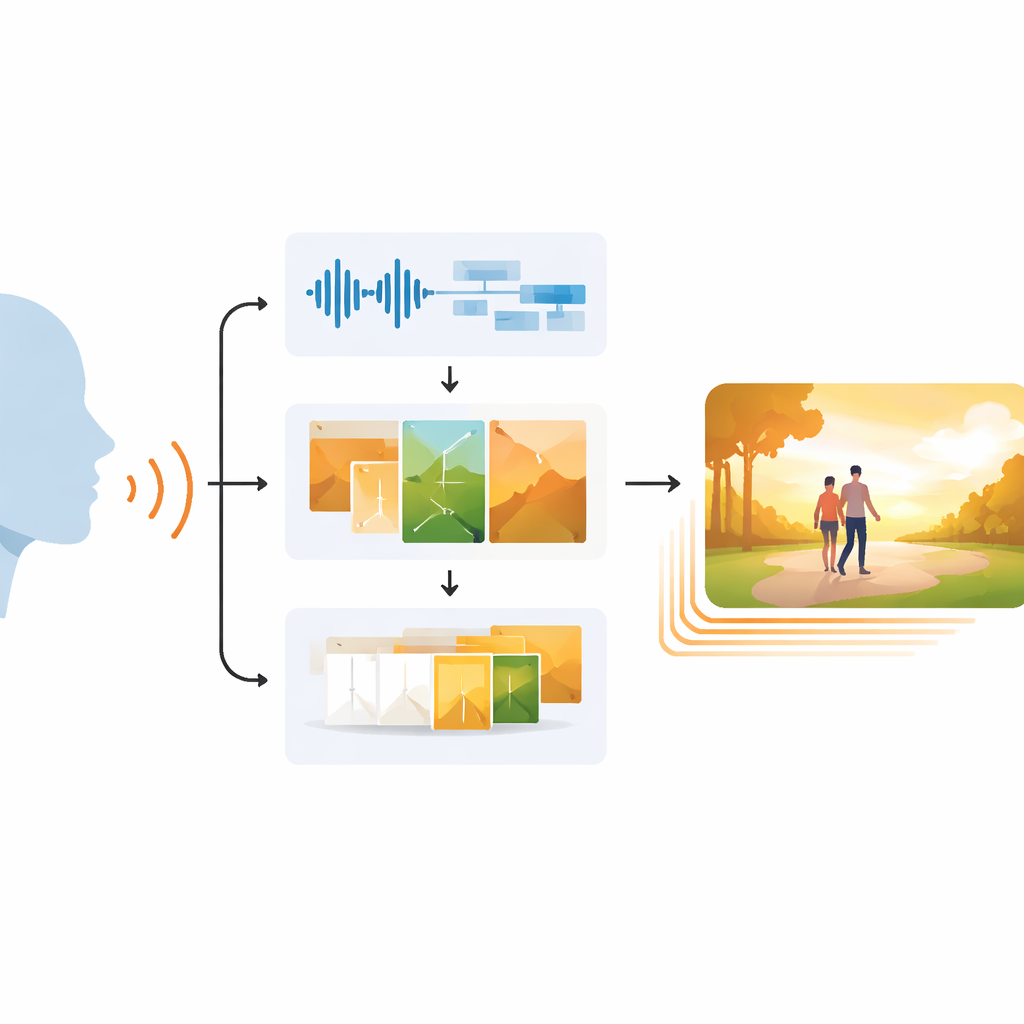
Por qué es difícil casar la vista y el sonido
Las personas combinan de forma natural el tono de voz, la expresión facial y las escenas del entorno para entenderse. Los sistemas de IA actuales que generan imágenes o vídeos a menudo pasan por alto esa riqueza. Muchos se centran en indicaciones textuales escritas, ignorando cómo las pausas, la entonación o la excitación en el habla señalan alegría, tristeza o suspense. Los generadores de vídeo anteriores tenían dificultades para mantener un movimiento fluido en el tiempo, produciendo con frecuencia escenas parpadeantes, personajes rígidos o visuales que no encajaban realmente con el sonido. Estas lagunas limitan la utilidad de tales herramientas para docentes, narradores y tecnologías de asistencia que dependen de visuales precisos y emocionalmente fieles.
Un camino de tres pasos del habla al vídeo
EchoVid aborda este problema con una canalización de tres etapas. Primero, el sistema escucha a una persona que habla mediante un micrófono. Limpia el audio para reducir el ruido de fondo y luego convierte el habla en texto mientras estima el estado de ánimo vocal a partir del ritmo, el tono y la intensidad. Segundo, mezcla las palabras reconocidas con estas señales emocionales para crear una indicación interna rica. Esa indicación se compara con una base de datos de temas—como naturaleza, vida urbana o fantasía—para mantener la escena en el tema. Usando un potente generador de imágenes conocido como Stable Diffusion, EchoVid produce entonces fotogramas individuales que reflejan visualmente tanto lo que se dijo como cómo se dijo. Finalmente, en la tercera etapa, el sistema crea fotogramas intermedios adicionales en un espacio “latente” especial, transformando suavemente una imagen en la siguiente para que el vídeo final se sienta fluido en lugar de entrecortado.
Dentro de la sala de máquinas
En el interior, EchoVid equilibra cuidadosamente calidad y velocidad. El front-end de voz está afinado para centrarse en el rango de frecuencias donde se sitúan las voces humanas, lo que ayuda a reducir errores de reconocimiento. El generador de imágenes opera a una resolución moderada que puede ampliarse, manteniendo el tiempo de procesamiento manejable sin dejar de producir resultados nítidos. Los investigadores usan pistas de indicación adicionales—como etiquetas para fondos coherentes o movimiento dinámico—para mantener estables los personajes y escenarios de fotograma a fotograma. También evitan técnicas caras y lentas, como transformadores de vídeo completamente autorregresivos, y en su lugar se basan en interpolación inteligente y reutilización de herramientas de generación de imágenes. Como resultado, en una tarjeta gráfica moderna, EchoVid puede producir clips terminados en solo un poco más de tiempo del que dura el audio original, haciendo concebible un uso casi en tiempo real.
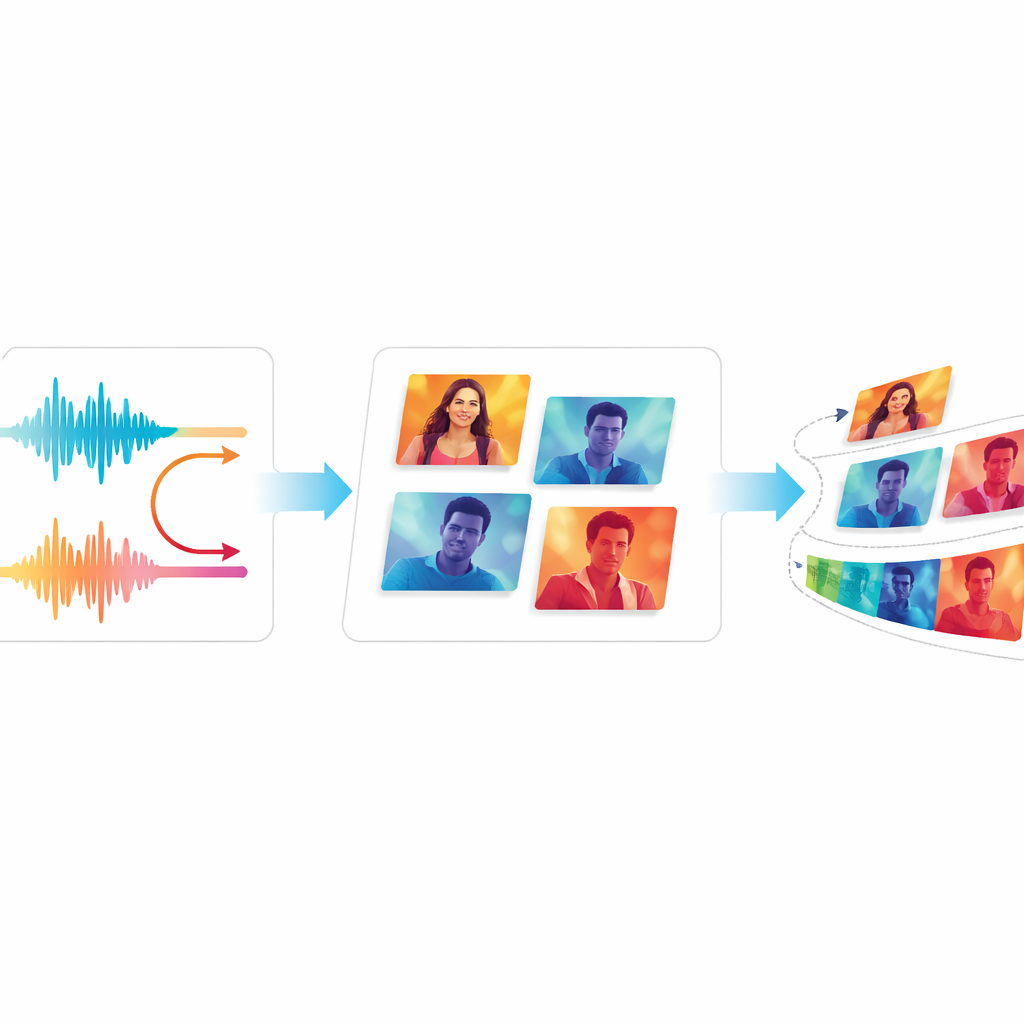
Evaluando calidad y suavidad
Para juzgar si EchoVid mejora realmente a los sistemas anteriores, los autores lo comparan con generadores de vídeo bien conocidos, incluidos modelos clásicos basados en GAN y herramientas modernas basadas en difusión. Usan medidas estándar que comparan vídeos generados con reales, así como un método de puntuación que verifica qué tan ajustados están los vídeos a las descripciones textuales. El equipo también introduce dos nuevas medidas: una rastrea la coherencia del contenido visual de fotograma a fotograma, y la otra estima cuánto parpadeo distractor podrían notar los espectadores. En dos conjuntos de datos de vídeo ampliamente usados, EchoVid obtiene mejores puntuaciones que los sistemas anteriores en alineación semántica y estabilidad temporal, todo ello manteniéndose computacionalmente eficiente. Expertos humanos que vieron clips de muestra coincidieron en que los vídeos parecían coherentes y que coincidían bien con las indicaciones.
Qué podría significar esto para los usuarios cotidianos
El mensaje principal de EchoVid es que la generación de vídeo guiada por la voz y de alta calidad está ahora al alcance sin costes masivos de entrenamiento ni habilidades de edición. Al convertir descripciones habladas ordinarias en vídeos cortos afinados emocionalmente, el sistema podría ayudar a docentes a transformar clases en historias visuales, hacer los pódcast más atractivos o apoyar a personas con pérdida auditiva mediante resúmenes visuales de conversaciones. Los autores reconocen desafíos abiertos—como manejar muchos idiomas, expresiones faciales de alta precisión y escenas muy largas o complejas—pero sus resultados muestran que combinar cuidadosamente análisis del habla, difusión de imagen e interpolación inteligente de fotogramas ya puede producir vídeos convincentes y con conciencia del estado de ánimo a partir de nada más que el sonido de una voz.
Cita: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Palabras clave: generación de audio a vídeo, vídeo guiado por voz, IA generativa, stable diffusion, narrativa multimodal