Clear Sky Science · de
KI‑gesteuerte Audio‑zu‑Video‑Erzeugung für dynamische Inhaltserstellung mittels Stable Diffusion und CNN‑unterstützten Transformern
Stimmen in bewegte Geschichten verwandeln
Stellen Sie sich vor, Sie sprechen in Ihren Laptop und sehen sofort ein kurzes Video, das nicht nur wiedergibt, was Sie gesagt haben, sondern auch, wie Sie sich dabei gefühlt haben. Das ist das Versprechen von EchoVid, einem neuen künstlichen Intelligenzsystem, das gesprochene Audiodaten in kurze, emotional nuancierte Videoclips umwandelt. Die Arbeit liegt an der Schnittstelle von Sprachverarbeitung, Bildgenerierung und Videoeffekten und zielt darauf ab, digitale Inhaltserstellung so einfach zu machen wie lautes Aussprechen.
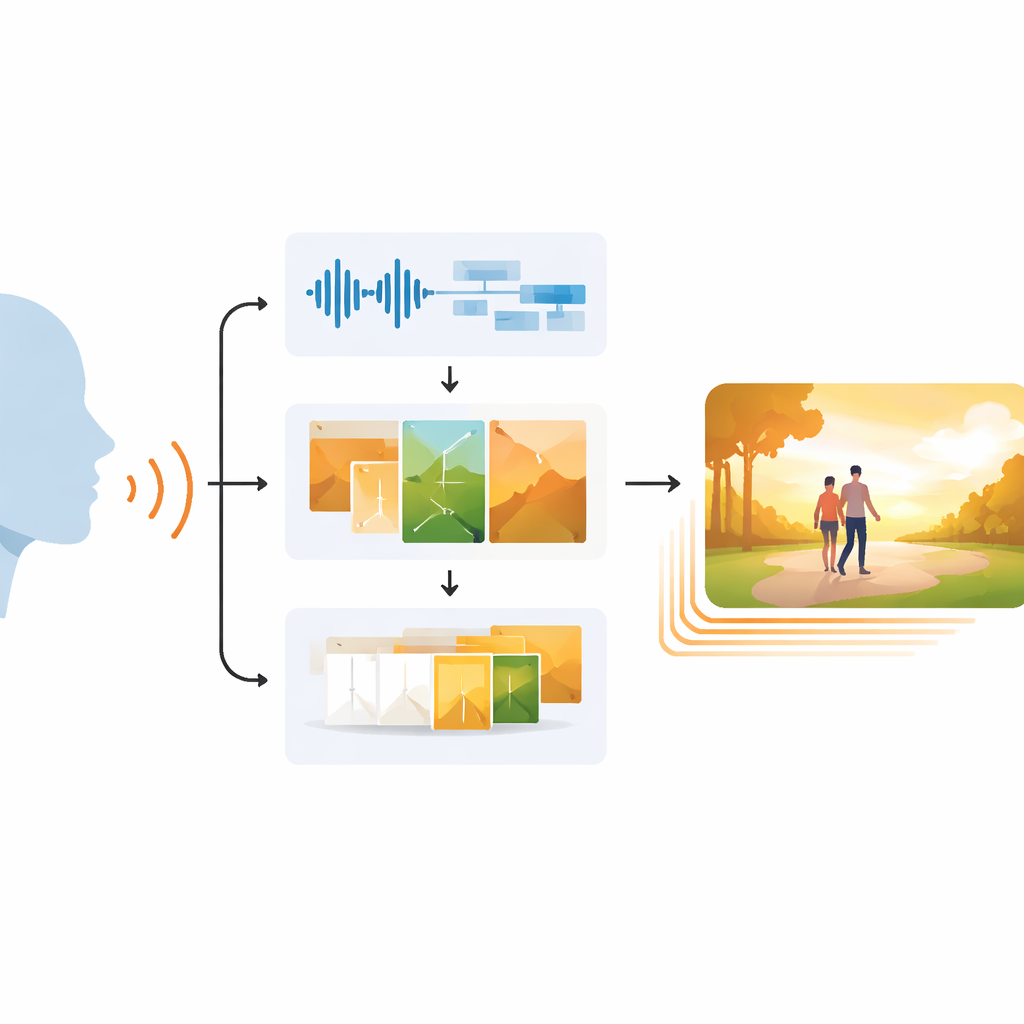
Warum Sicht und Klang abzustimmen schwierig ist
Menschen kombinieren natürlich Stimmlage, Mimik und Umgebungsszenen, um einander zu verstehen. Bestehende KI‑Systeme zur Bild‑ oder Videoerzeugung verpassen oft diese Vielschichtigkeit. Viele konzentrieren sich auf schriftliche Text‑Prompts und ignorieren, wie Pausen, Tonhöhe oder Erregung in der Sprache Freude, Traurigkeit oder Spannung signalisieren. Frühere Videoerzeuger hatten Probleme, Bewegung über die Zeit glatt zu halten, und produzierten häufig flimmernde Szenen, steife Figuren oder visuelle Eindrücke, die nicht wirklich zum Ton passten. Diese Lücken schränken den Nutzen solcher Werkzeuge für Lehrende, Geschichtenerzähler und unterstützende Technologien ein, die auf genaue, emotional treue Visualisierungen angewiesen sind.
Ein dreistufiger Weg von Sprache zu Video
EchoVid geht das Problem mit einer dreistufigen Pipeline an. Zuerst hört das System einer Person zu, die ins Mikrofon spricht. Es säubert das Audio, um Hintergrundgeräusche zu reduzieren, und wandelt die Sprache in Text um, während zugleich aus Rhythmus, Tonhöhe und Intensität die Stimmung abgeschätzt wird. Zweitens verbindet es die erkannten Wörter mit diesen emotionalen Hinweisen zu einem reichen internen Prompt. Dieser Prompt wird mit einer Datenbank von Themen – etwa Natur, Stadtleben oder Fantasy – abgeglichen, um das Szenenmotiv beizubehalten. Mit einem leistungsfähigen Bildgenerator namens Stable Diffusion erzeugt EchoVid dann einzelne Frames, die sowohl den Inhalt als auch die Stimmung des Gesagten visuell widerspiegeln. Schließlich erstellt das System in einer dritten Stufe zusätzliche Zwischenbilder in einem speziellen „latenten“ Raum und morphsiert behutsam von einem Bild zum nächsten, sodass das endgültige Video glatt wirkt statt ruckartig.
Ein Blick unter die Motorhaube
Unter der Haube balanciert EchoVid sorgfältig Qualität und Geschwindigkeit. Die Sprachvorderseite ist auf den Frequenzbereich abgestimmt, in dem menschliche Stimmen liegen, was Erkennungsfehler reduziert. Der Bildgenerator arbeitet in einer moderaten Auflösung, die hochskaliert werden kann, wodurch die Verarbeitungszeit überschaubar bleibt und dennoch scharfe Ergebnisse entstehen. Die Forschenden nutzen zusätzliche Prompt‑Hinweise – etwa Tags für konsistente Hintergründe oder dynamische Bewegung – um Figuren und Szenerien von Frame zu Frame stabil zu halten. Sie vermeiden außerdem teure, langsame Techniken wie vollständig autoregressive Video‑Transformer und setzen stattdessen auf clevere Interpolation und Wiederverwendung von Bildgenerierungswerkzeugen. Infolgedessen kann EchoVid auf einer modernen Grafikkarte fertige Clips in nur wenig mehr Zeit produzieren als die ursprüngliche Audiodauer, sodass eine nahezu Echtzeitnutzung denkbar ist.
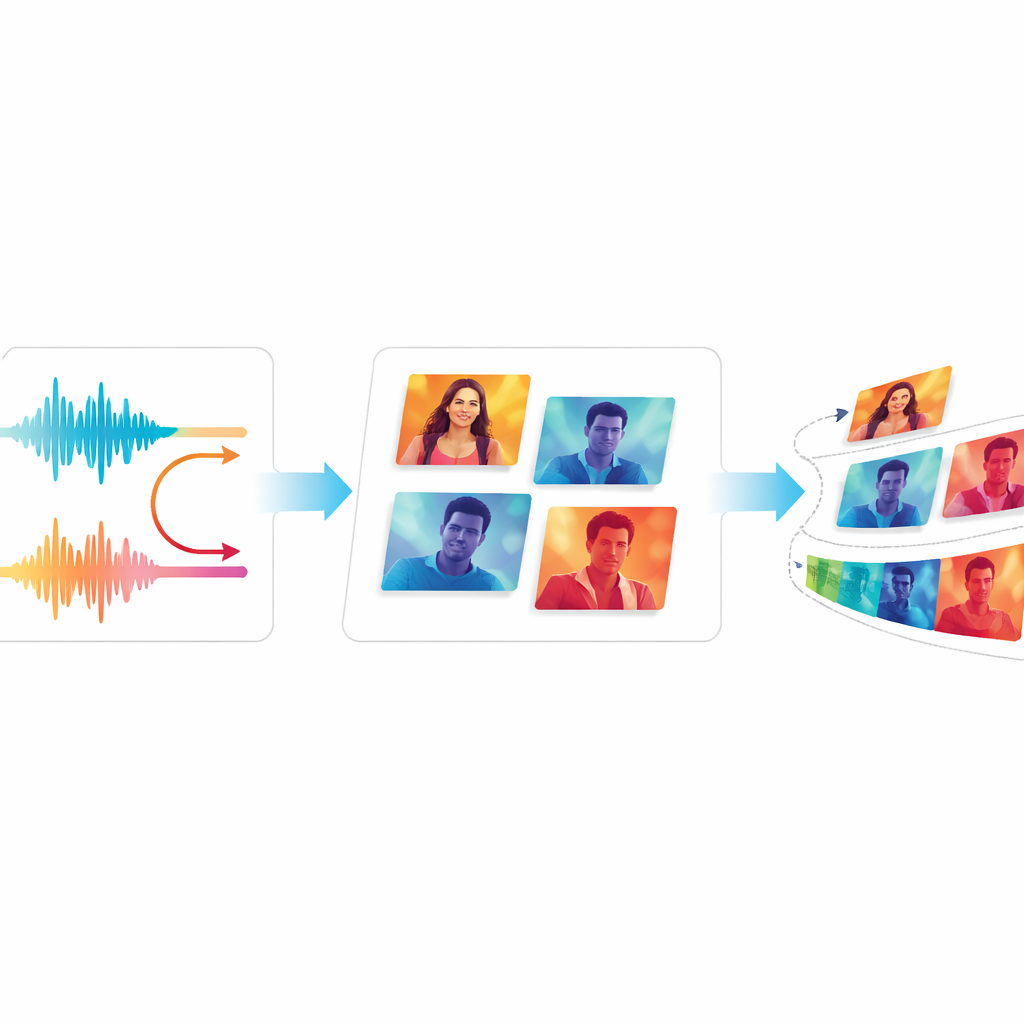
Qualität und Glätte testen
Um zu beurteilen, ob EchoVid wirklich besser ist als frühere Systeme, vergleichen die Autor:innen es mit bekannten Videoerzeugern, darunter klassische GAN‑Modelle und moderne diffusionsbasierte Werkzeuge. Sie verwenden standardisierte Maße, die generierte Videos mit realen vergleichen, sowie eine Bewertungsmethode, die prüft, wie eng Videos Textbeschreibungen entsprechen. Das Team führt außerdem zwei neue Messgrößen ein: eine misst, wie konsistent die visuellen Inhalte von Frame zu Frame bleiben, die andere schätzt, wie stark störendes Flimmern für Zuschauer wahrnehmbar ist. Über zwei weit verbreitete Videodatensätze erzielt EchoVid bessere Werte als ältere Systeme hinsichtlich semantischer Übereinstimmung und zeitlicher Stabilität, und das bei geringerem Rechenaufwand. Menschliche Expert:innen, die Musterclips anschauten, waren sich einig, dass die Videos kohärent wirkten und gut zu den Prompts passten.
Was das für alltägliche Nutzer bedeuten könnte
Die zentrale Aussage von EchoVid ist, dass hochwertige, sprachgesteuerte Videoerzeugung nun ohne enorme Trainingskosten oder Schnittkenntnisse erreichbar ist. Indem normale gesprochene Beschreibungen in kurze, emotional abgestimmte Videos verwandelt werden, könnte das System Lehrenden helfen, Vorlesungen in visuelle Geschichten umzusetzen, Podcasts ansprechender zu machen oder Menschen mit Hörverlust durch visuelle Zusammenfassungen von Gesprächen zu unterstützen. Die Autor:innen räumen offene Herausforderungen ein – etwa die Behandlung vieler Sprachen, feinste Gesichtsausdrücke und sehr lange oder komplexe Szenen – doch ihre Ergebnisse zeigen, dass die sorgfältige Kombination aus Sprachanalyse, Bilddiffusion und intelligenter Frame‑Interpolation bereits überzeugende, stimmungsbewusste Videos allein aus der Stimme erzeugen kann.
Zitation: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Schlüsselwörter: Audio‑zu‑Video‑Erzeugung, sprachgesteuertes Video, generative KI, Stable Diffusion, multimodales Erzählen