Clear Sky Science · en
AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers
Turning Voices into Moving Stories
Imagine speaking into your laptop and instantly watching a short video that captures not just what you said, but how you felt when you said it. That is the promise of EchoVid, a new artificial intelligence system that turns spoken audio into short, emotionally aware video clips. The work sits at the crossroads of speech technology, image generation, and video effects, aiming to make digital content creation as simple as talking out loud.
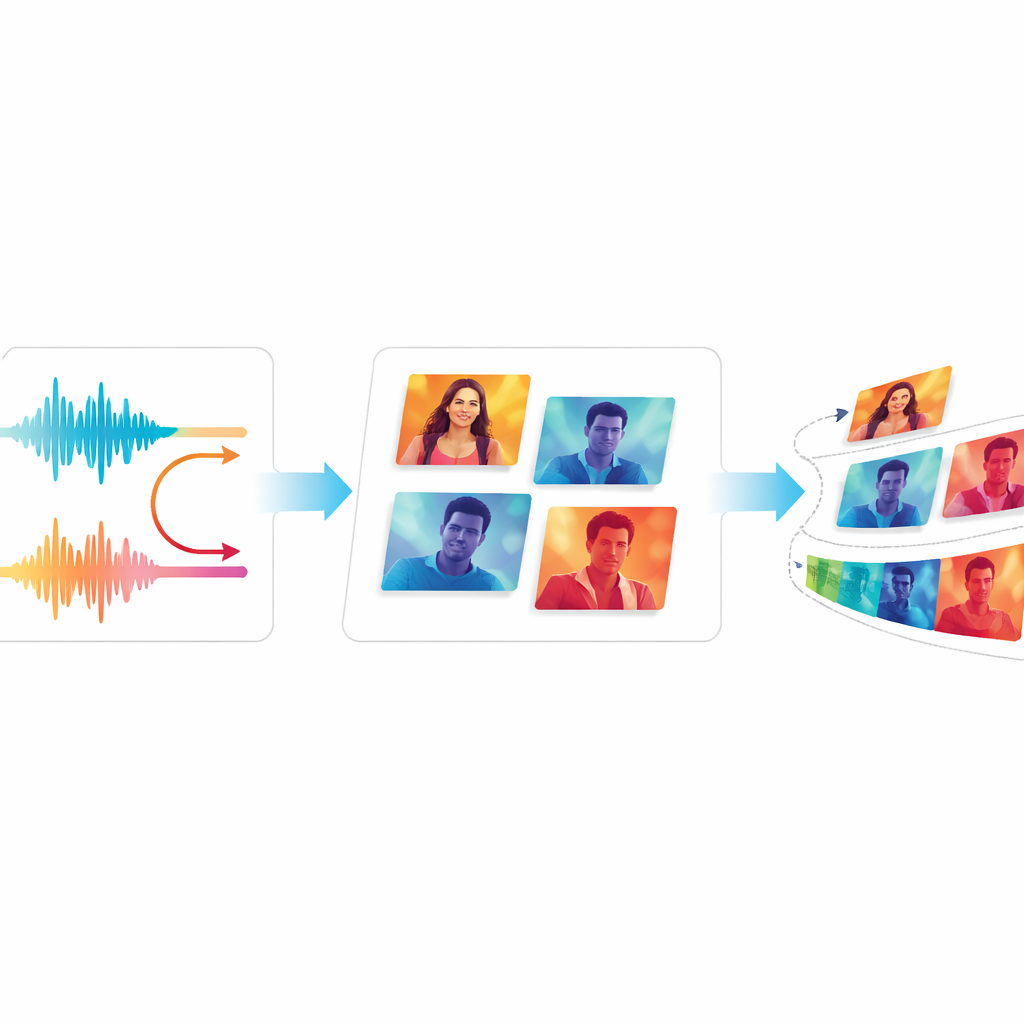
Why Matching Sight and Sound Is Hard
People naturally combine tone of voice, facial expression, and surrounding scenes to understand one another. Existing AI systems that generate images or videos often miss this richness. Many focus on written text prompts, ignoring how pauses, pitch, or excitement in speech signal joy, sadness, or suspense. Earlier video generators struggled to keep motion smooth over time, often producing flickering scenes, stiff characters, or visuals that did not really fit the sound. These gaps limit the usefulness of such tools for teachers, storytellers, and assistive technologies that rely on accurate, emotionally faithful visuals.
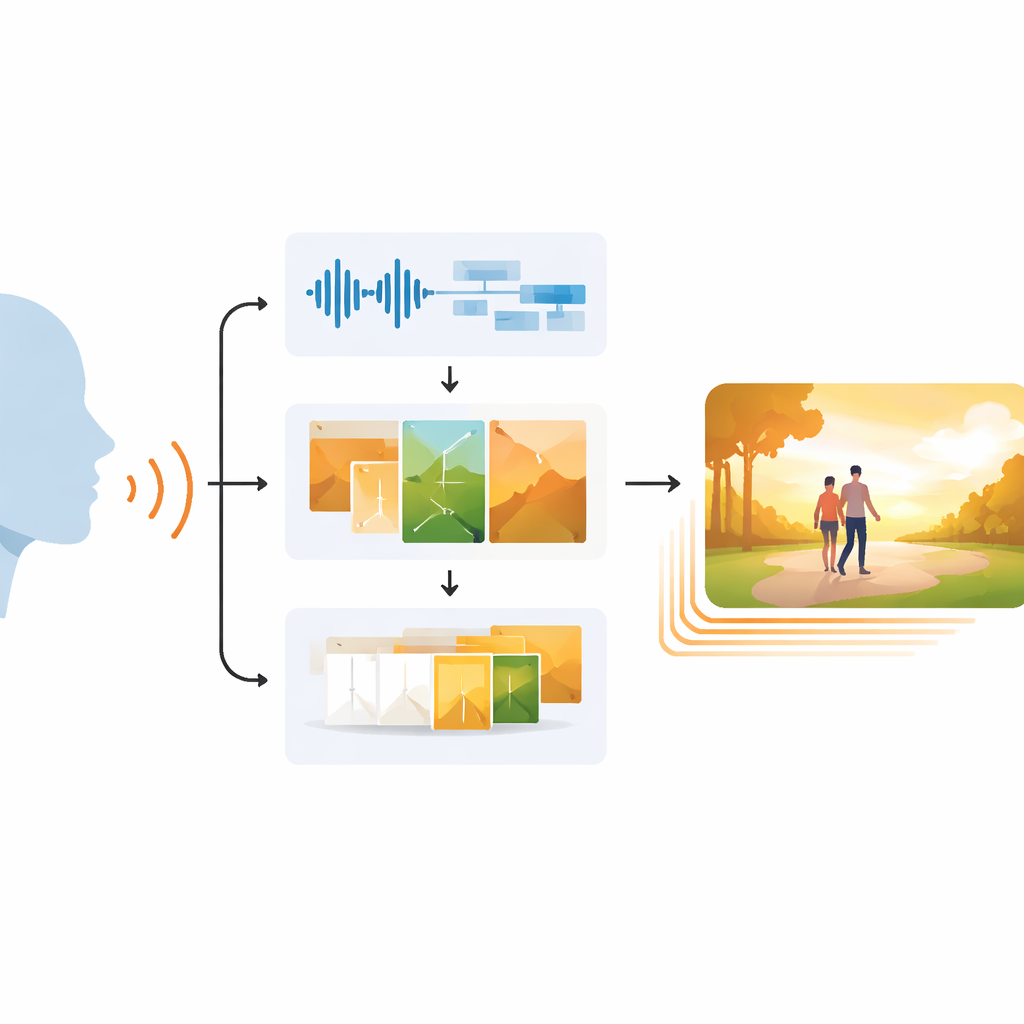
A Three-Step Path from Speech to Video
EchoVid tackles this problem with a three-stage pipeline. First, the system listens to a person speaking through a microphone. It cleans up the audio to reduce background noise and then converts the speech into text while also estimating vocal mood from rhythm, pitch, and intensity. Second, it blends the recognized words with these emotional cues to craft a rich internal prompt. That prompt is matched against a database of themes—such as nature, city life, or fantasy—to keep the scene on-topic. Using a powerful image generator known as Stable Diffusion, EchoVid then produces individual frames that visually reflect both what was said and how it was said. Finally, in the third stage, the system creates additional in-between frames in a special "latent" space, gently morphing one image into the next so that the final video feels smooth rather than jumpy.
Inside the Engine Room
Under the hood, EchoVid carefully balances quality and speed. The speech front end is tuned to focus on the frequency range where human voices live, which helps reduce recognition mistakes. The image generator operates at a moderate resolution that can be upscaled, keeping processing time manageable while still producing sharp results. The researchers use extra prompt hints—such as tags for consistent backgrounds or dynamic motion—to keep characters and settings stable from frame to frame. They also avoid expensive, slow techniques like fully autoregressive video transformers and instead rely on clever interpolation and reuse of image-generation tools. As a result, on a modern graphics card, EchoVid can produce finished clips in only a bit more time than the original audio lasts, making near-real-time use conceivable.
Testing Quality and Smoothness
To judge whether EchoVid truly improves on past systems, the authors benchmark it against well-known video generators, including classic GAN-based models and modern diffusion-based tools. They use standard measures that compare generated videos with real ones, as well as a scoring method that checks how closely videos match text descriptions. The team also introduces two new measures: one tracks how consistent the visual content stays from frame to frame, and the other estimates how much distracting flicker viewers might notice. Across two widely used video datasets, EchoVid scores better than older systems on semantic alignment and temporal stability, all while staying computationally efficient. Human experts who watched sample clips agreed that the videos looked coherent and matched the prompts well.
What This Could Mean for Everyday Users
EchoVid’s main message is that high-quality, speech-driven video generation is now within reach without massive training costs or editing skills. By turning ordinary spoken descriptions into short, emotionally tuned videos, the system could help teachers turn lectures into visual stories, make podcasts more engaging, or support people with hearing loss through visual summaries of conversations. The authors acknowledge open challenges—such as handling many languages, fine-grained facial expressions, and very long or complex scenes—but their results show that carefully combining speech analysis, image diffusion, and smart frame interpolation can already produce convincing, mood-aware video from nothing more than the sound of a voice.
Citation: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Keywords: audio-to-video generation, speech-driven video, generative AI, stable diffusion, multimodal storytelling