Clear Sky Science · pt
Geração de áudio-para-vídeo orientada por IA para criação dinâmica de conteúdo via stable diffusion e transformers aumentados por CNN
Transformando Vozes em Histórias em Movimento
Imagine falar ao seu laptop e imediatamente ver um vídeo curto que captura não apenas o que você disse, mas como você se sentiu ao dizê-lo. Essa é a promessa do EchoVid, um novo sistema de inteligência artificial que transforma áudio falado em clipes de vídeo curtos e sensíveis ao aspecto emocional. O trabalho se situa na interseção entre tecnologia de fala, geração de imagens e efeitos de vídeo, com o objetivo de tornar a criação de conteúdo digital tão simples quanto falar em voz alta.
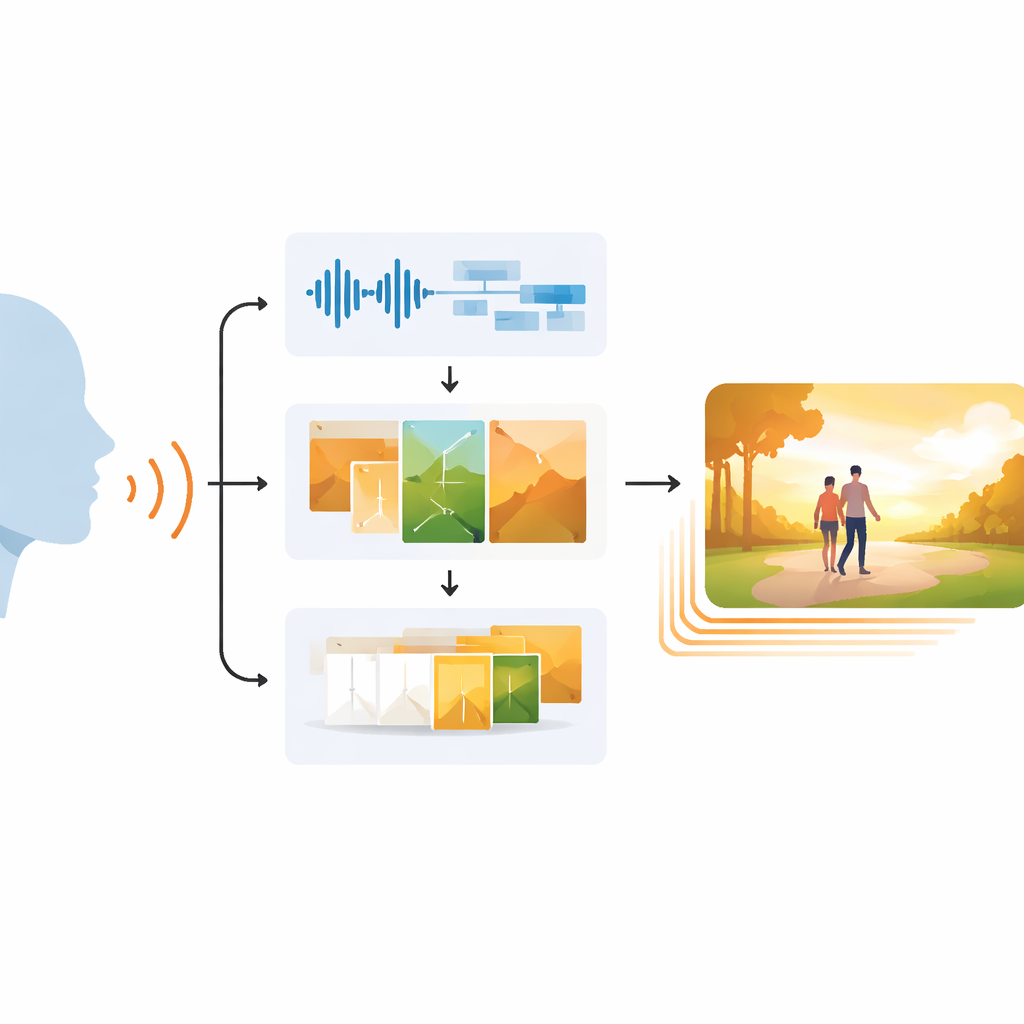
Por que Combinar Visão e Som é Difícil
As pessoas naturalmente combinam tom de voz, expressão facial e cenas ao redor para se entenderem. Sistemas de IA existentes que geram imagens ou vídeos frequentemente perdem essa riqueza. Muitos se concentram em promptes de texto escritos, ignorando como pausas, entonação ou excitação na fala sinalizam alegria, tristeza ou suspense. Geradores de vídeo anteriores tiveram dificuldade em manter o movimento suave ao longo do tempo, frequentemente produzindo cenas tremeluzentes, personagens rígidos ou visuais que não combinavam com o som. Essas lacunas limitam a utilidade dessas ferramentas para professores, contadores de histórias e tecnologias assistivas que dependem de visuais precisos e emocionalmente fiéis.
Um Caminho em Três Etapas da Fala ao Vídeo
EchoVid enfrenta esse problema com um fluxo de trabalho em três estágios. Primeiro, o sistema escuta uma pessoa falando por um microfone. Ele limpa o áudio para reduzir ruídos de fundo e então converte a fala em texto enquanto também estima o estado emocional vocal a partir do ritmo, da entonação e da intensidade. Em segundo lugar, combina as palavras reconhecidas com esses sinais emocionais para criar um prompt interno rico. Esse prompt é comparado com um banco de temas — como natureza, vida urbana ou fantasia — para manter a cena no tópico. Usando um poderoso gerador de imagens conhecido como Stable Diffusion, o EchoVid então produz quadros individuais que refletem visualmente tanto o que foi dito quanto como foi dito. Finalmente, no terceiro estágio, o sistema cria quadros adicionais intermediários em um espaço "latente" especial, morfando suavemente uma imagem na outra para que o vídeo final pareça fluido em vez de saltado.
Dentro da Sala das Máquinas
Por baixo do capô, o EchoVid equilibra cuidadosamente qualidade e velocidade. A frente de fala é ajustada para focar na faixa de frequência onde as vozes humanas residem, o que ajuda a reduzir erros de reconhecimento. O gerador de imagens opera em uma resolução moderada que pode ser aumentada, mantendo o tempo de processamento gerenciável enquanto ainda produz resultados nítidos. Os pesquisadores usam dicas extras no prompt — como etiquetas para fundos consistentes ou movimento dinâmico — para manter personagens e cenários estáveis de quadro a quadro. Eles também evitam técnicas caras e lentas, como transformers de vídeo totalmente autorregressivos, e em vez disso dependem de interpolação inteligente e reaproveitamento de ferramentas de geração de imagens. Como resultado, em uma placa de vídeo moderna, o EchoVid pode produzir clipes finalizados em apenas um pouco mais de tempo do que a duração original do áudio, tornando o uso quase em tempo real concebível.
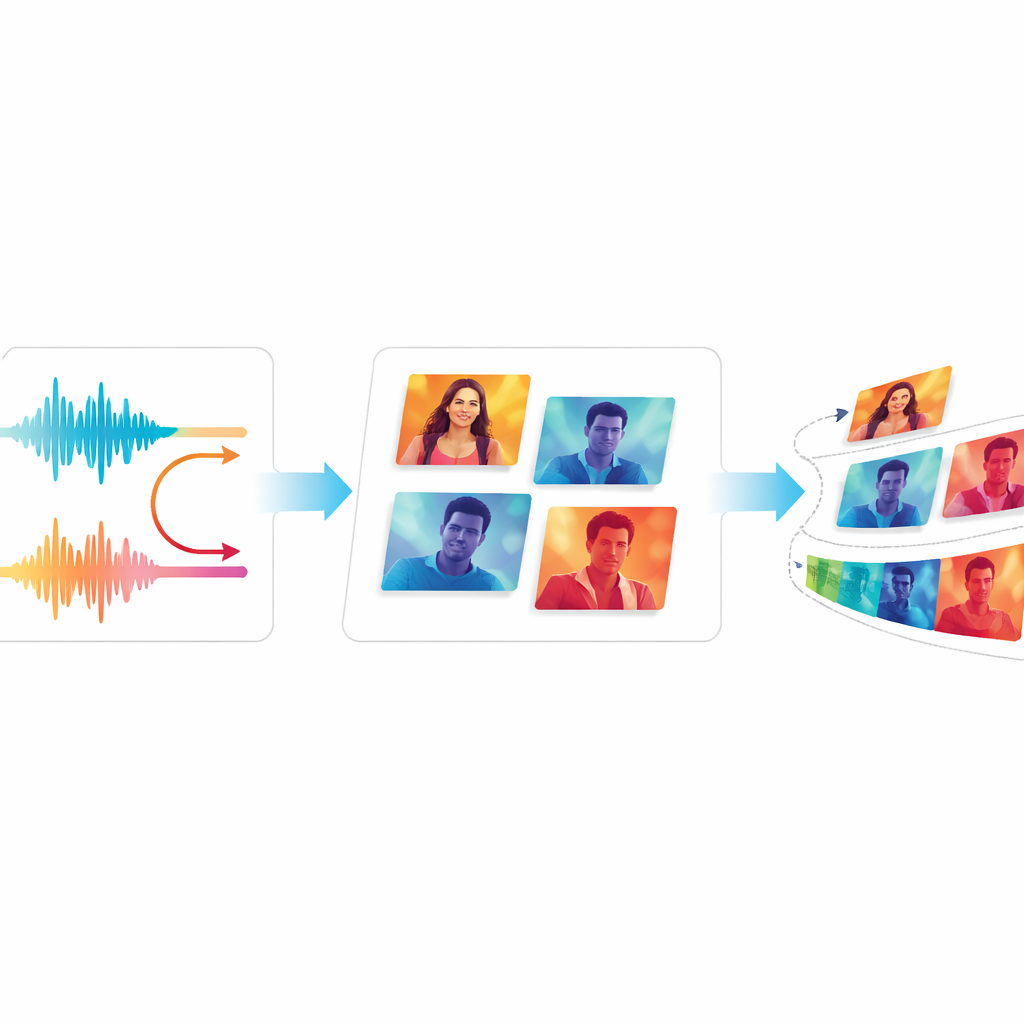
Avaliando Qualidade e Fluidez
Para julgar se o EchoVid realmente melhora em relação a sistemas anteriores, os autores o comparam com geradores de vídeo bem conhecidos, incluindo modelos clássicos baseados em GAN e ferramentas modernas baseadas em difusão. Eles usam medidas padrão que comparam vídeos gerados com vídeos reais, assim como um método de pontuação que verifica quão bem os vídeos correspondem a descrições textuais. A equipe também introduz duas novas métricas: uma acompanha quão consistente o conteúdo visual se mantém de quadro a quadro, e a outra estima quanto de tremulação distrativa os espectadores podem notar. Em dois conjuntos de dados de vídeo amplamente usados, o EchoVid obtém pontuações melhores que sistemas mais antigos em alinhamento semântico e estabilidade temporal, tudo isso mantendo eficiência computacional. Especialistas humanos que assistiram aos clipes de amostra concordaram que os vídeos pareciam coerentes e compatíveis com os prompts.
O Que Isso Pode Significar para Usuários Cotidianos
A principal mensagem do EchoVid é que a geração de vídeo de alta qualidade guiada por fala está agora ao alcance sem custos massivos de treinamento ou habilidades de edição. Ao transformar descrições faladas ordinárias em vídeos curtos e ajustados emocionalmente, o sistema pode ajudar professores a transformar aulas em histórias visuais, tornar podcasts mais envolventes ou apoiar pessoas com deficiência auditiva por meio de resumos visuais de conversas. Os autores reconhecem desafios em aberto — como lidar com muitos idiomas, expressões faciais de alta precisão e cenas muito longas ou complexas — mas seus resultados mostram que combinar cuidadosamente análise de fala, difusão de imagem e interpolação inteligente de quadros já pode produzir vídeos convincentes e sensíveis ao humor a partir de nada além do som de uma voz.
Citação: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Palavras-chave: geração de áudio-para-vídeo, vídeo guiado por fala, IA generativa, stable diffusion, narrativa multimodal