Clear Sky Science · fr
Génération audio-vers-vidéo pilotée par l’IA pour une création de contenu dynamique via la diffusion stable et des transformers augmentés par CNN
Transformer les voix en histoires en mouvement
Imaginez parler dans votre ordinateur portable et voir instantanément une courte vidéo qui capture non seulement ce que vous avez dit, mais aussi ce que vous ressentiez en le disant. C’est la promesse d’EchoVid, un nouveau système d’intelligence artificielle qui transforme l’audio parlé en clips vidéo courts et sensibles aux émotions. Ce travail se situe à la croisée de la technologie vocale, de la génération d’images et des effets vidéo, et vise à rendre la création de contenu numérique aussi simple que parler à voix haute.
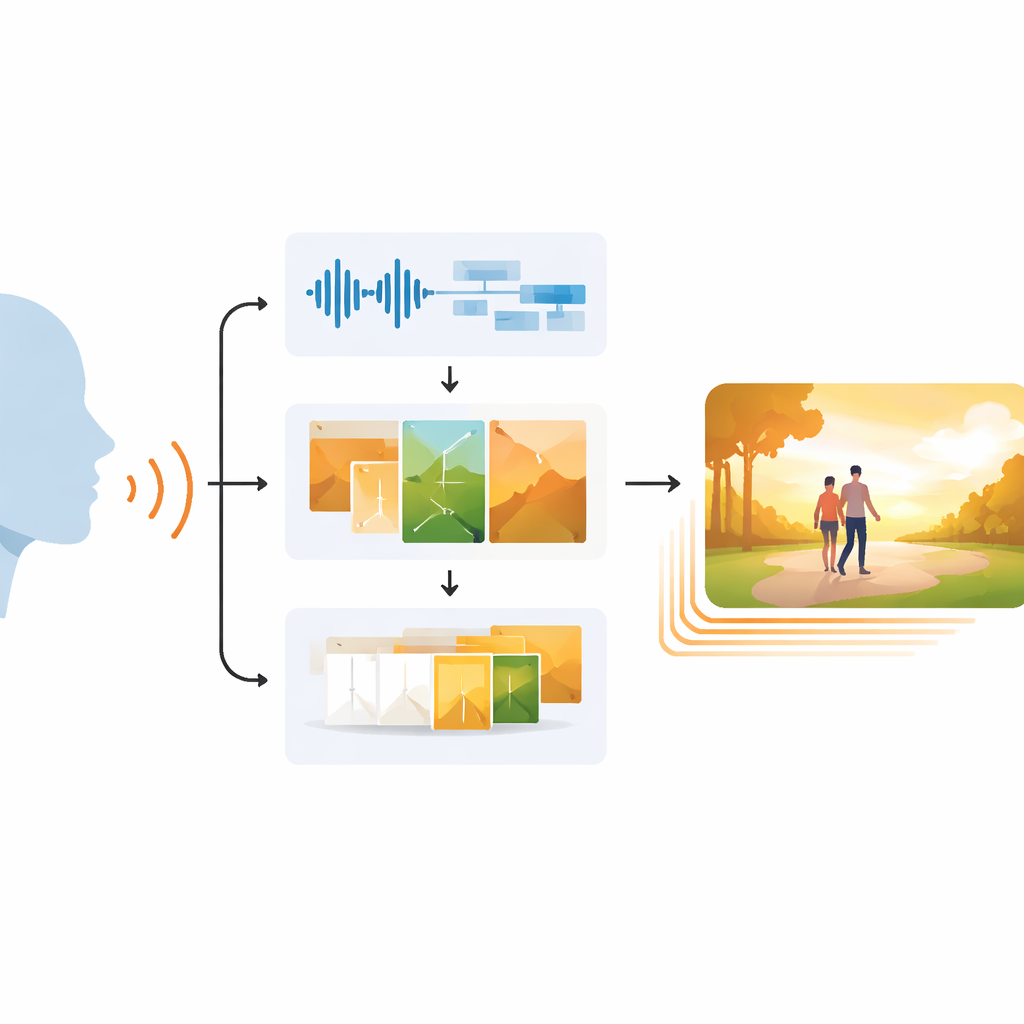
Pourquoi faire correspondre vue et son est difficile
Les personnes combinent naturellement le ton de la voix, l’expression faciale et l’environnement pour se comprendre mutuellement. Les systèmes d’IA existants qui génèrent des images ou des vidéos manquent souvent de cette richesse. Beaucoup se concentrent sur des invites textuelles écrites, en ignorant comment les pauses, la hauteur ou l’enthousiasme dans la voix signalent la joie, la tristesse ou le suspense. Les générateurs vidéo antérieurs peinaient à maintenir un mouvement fluide dans le temps, produisant souvent des scènes scintillantes, des personnages raides ou des visuels qui ne correspondaient pas vraiment au son. Ces lacunes limitent l’utilité de tels outils pour les enseignants, les conteurs et les technologies d’assistance qui dépendent de visuels précis et fidèles aux émotions.
Un parcours en trois étapes de la parole à la vidéo
EchoVid aborde ce problème avec une chaîne de traitement en trois étapes. D’abord, le système écoute la personne qui parle via un microphone. Il nettoie l’audio pour réduire le bruit de fond puis convertit la parole en texte tout en estimant l’humeur vocale à partir du rythme, de la hauteur et de l’intensité. Ensuite, il fusionne les mots reconnus avec ces indices émotionnels pour élaborer une invite interne riche. Cette invite est mise en correspondance avec une base de thèmes — comme la nature, la vie urbaine ou la fantaisie — pour maintenir la cohérence du décor. En utilisant un puissant générateur d’images connu sous le nom de Stable Diffusion, EchoVid produit ensuite des images individuelles qui reflètent visuellement à la fois ce qui a été dit et la manière dont cela a été dit. Enfin, dans la troisième étape, le système crée des images intermédiaires supplémentaires dans un espace « latent » spécial, métamorphosant doucement une image en la suivante afin que la vidéo finale paraisse fluide plutôt que saccadée.
Dans la salle des machines
Sous le capot, EchoVid équilibre soigneusement qualité et rapidité. Le front-end vocal est réglé pour se concentrer sur la plage de fréquences où se situent les voix humaines, ce qui aide à réduire les erreurs de reconnaissance. Le générateur d’images fonctionne à une résolution modérée pouvant être suréchantillonnée, ce qui garde le temps de traitement raisonnable tout en produisant des résultats nets. Les chercheurs utilisent des indices d’invite supplémentaires — comme des balises pour des arrière-plans cohérents ou des mouvements dynamiques — afin de maintenir la stabilité des personnages et des décors d’une image à l’autre. Ils évitent aussi des techniques coûteuses et lentes comme les transformers vidéo entièrement autorégressifs et s’appuient plutôt sur une interpolation intelligente et la réutilisation d’outils de génération d’images. En conséquence, sur une carte graphique moderne, EchoVid peut produire des clips finis en seulement un peu plus de temps que la durée de l’audio original, rendant un usage quasi temps réel concevable.
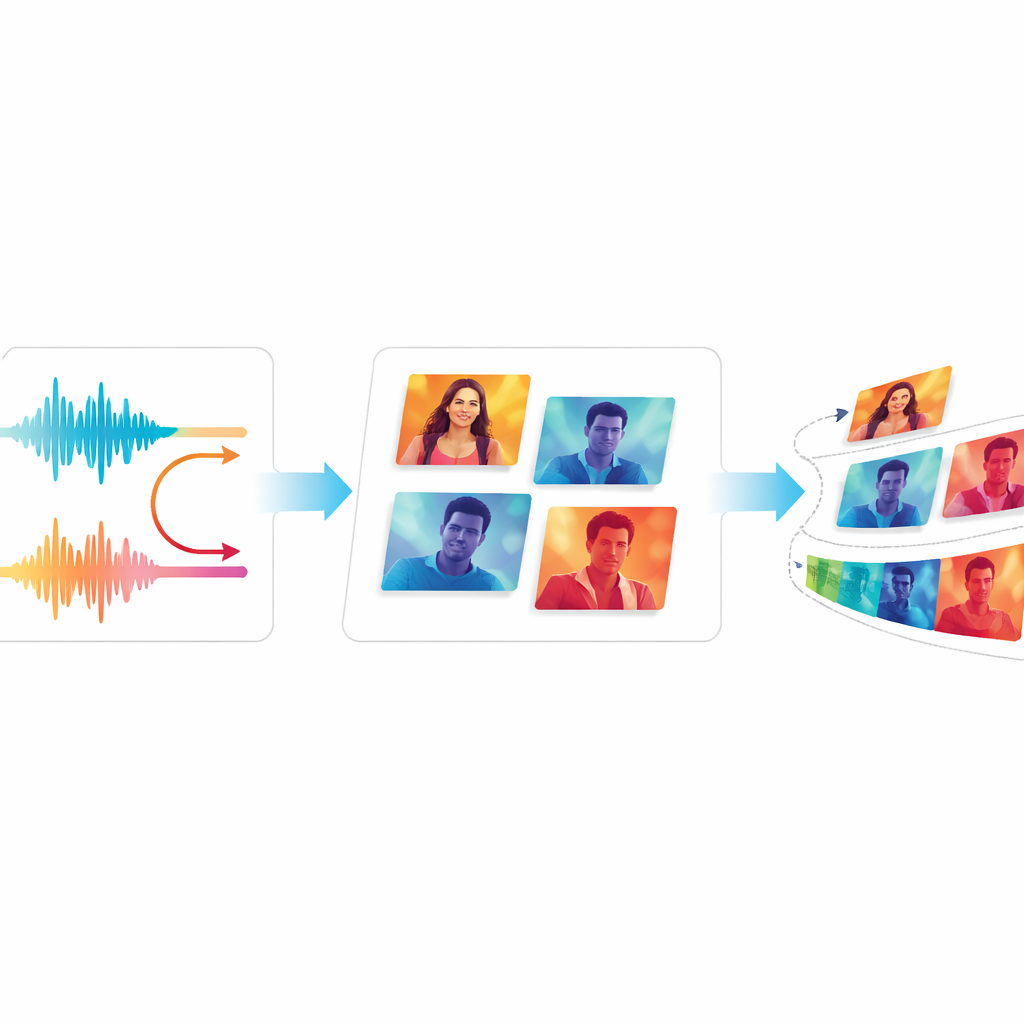
Tester la qualité et la fluidité
Pour évaluer si EchoVid améliore réellement les systèmes antérieurs, les auteurs le comparent à des générateurs vidéo bien connus, y compris des modèles classiques basés sur des GAN et des outils modernes basés sur la diffusion. Ils utilisent des mesures standards qui comparent les vidéos générées aux vidéos réelles, ainsi qu’une méthode de notation qui vérifie la correspondance entre les vidéos et les descriptions textuelles. L’équipe introduit également deux nouvelles mesures : l’une suit la cohérence du contenu visuel d’une image à l’autre, et l’autre estime l’importance du scintillement distrayant que les spectateurs peuvent remarquer. Sur deux ensembles de données vidéo largement utilisés, EchoVid obtient de meilleurs scores que les systèmes plus anciens en adéquation sémantique et en stabilité temporelle, tout en restant efficace sur le plan calculatoire. Des experts humains ayant regardé des extraits ont confirmé que les vidéos semblaient cohérentes et correspondaient bien aux invites.
Ce que cela pourrait signifier pour les utilisateurs quotidiens
Le message principal d’EchoVid est que la génération vidéo pilotée par la parole et de haute qualité est désormais à portée de main sans coûts massifs d’entraînement ni compétences en montage. En transformant des descriptions parlées ordinaires en courtes vidéos réglées sur l’émotion, le système pourrait aider les enseignants à transformer des cours en histoires visuelles, rendre les podcasts plus captivants ou aider les personnes malentendantes via des résumés visuels de conversations. Les auteurs reconnaissent des défis ouverts — comme la gestion de nombreuses langues, les expressions faciales fines et les scènes très longues ou complexes — mais leurs résultats montrent que la combinaison soignée d’analyse vocale, de diffusion d’images et d’interpolation d’images intelligente peut déjà produire, à partir de rien d’autre que la voix, des vidéos convaincantes et sensibles à l’humeur.
Citation: Dharrao, D., Dharrao, M., Padgaonkar, S. et al. AI-driven audio-to-video generation for dynamic content creation via stable diffusion and CNN-augmented transformers. Sci Rep 16, 10295 (2026). https://doi.org/10.1038/s41598-026-38758-3
Mots-clés: génération audio-vers-vidéo, vidéo pilotée par la parole, IA générative, diffusion stable, narration multimodale