Clear Sky Science · zh
叙事对话数据集:带说话人和情感标注的会话语料库
为什么会话体故事很重要
当我们阅读一个故事时,会自然而然地记住是谁在说话以及他们的情绪。然而,计算机在处理这种微妙的情感对话时经常吃力。本文引入了一个新数据集,帮助机器以人类的方式理解故事对话:不仅识别文字,还标明是哪位角色在说话以及他们表达了何种情绪。该资源基于数千篇儿童故事构建,旨在为更自然、具情感感知能力的聊天机器人、讲故事系统和有声读物提供支持。
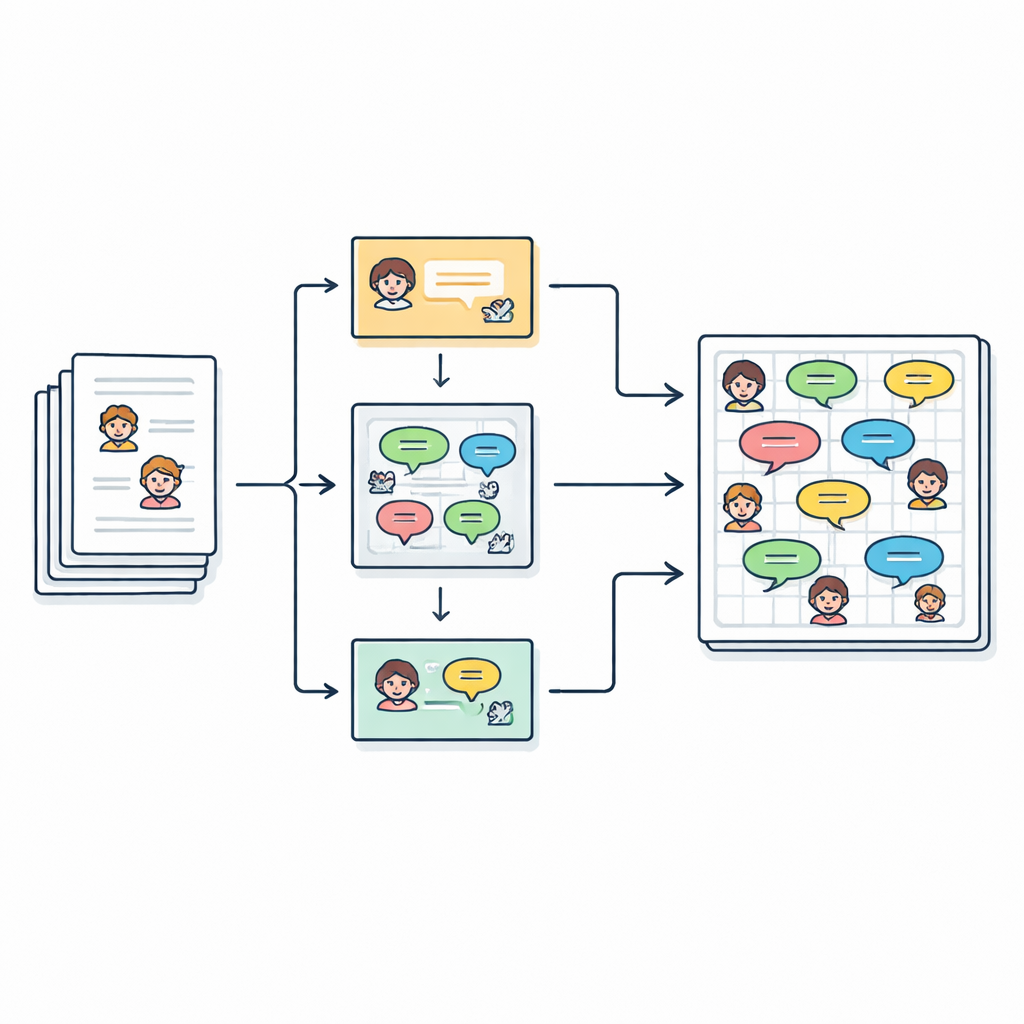
将故事转化为对话脚本
作者从在线仓库中收集了2,588篇英文儿童短篇故事。每篇故事都列出了主要角色,但正文通常以连贯散文写成,对话夹在引号中。团队的目标是把这种自由形式的写法转换成干净的脚本,呈现为“说话人(情绪):台词”这样的行,以便每句口语化的句子都能被研究、建模或由计算机语音演绎。最终,他们提取了超过27,000句对话行,关联到2,500多名不同角色。
辨认谁在说话
确定故事中说话者比看上去更棘手。作者常用代词如“she”或类似“the child”的表述来代替重复使用名字。为了解开这些线索,处理流程首先临时屏蔽每段带引号的台词,然后运行一个名为 FastCoref 的工具,将代词和描述追溯到正确的角色。恢复原始对话后,另一个工具 BookNLP 会为每行分配具体说话人,并给角色标注诸如性别等基本特征。未置于引号内的句子被视作叙述,由隐含的“旁白”发声并记为中性情感标签,从而可以把整篇故事表示为脚本形式。
教机器识别情绪
接下来,研究者为每句对话标注情绪基调。他们在一个大型推特数据集上训练了一个神经网络模型,该数据集中短文本被标注为六种情绪之一:喜悦、悲伤、愤怒、恐惧、爱与惊讶。模型使用双向 GRU,这是一种擅长处理句子中词序的循环神经网络。文本经过去噪与分词后,训练时对稀有情绪加大权重以降低偏差。在保留的推特测试集上,模型总体准确率约为94%。随后将该训练好的模型应用于故事对话,为每行分配情绪标签且不改变原文措辞,以保留原有的文学风格。
捕捉每个故事的核心
除了说话人和情绪外,数据集还记录了每个故事的主题。为此,作者使用了大型语言模型(Mistral-7B)并设计了精心的提示,要求从故事文本中精确提取五个关键词。这些关键词作为简洁摘要——诸如人物名、地点或核心物件——未来可用于“引导”新故事的生成。最终结果是对每篇故事的分层表示:一组关键词、角色列表,以及每行都带有说话人和情绪标签的脚本。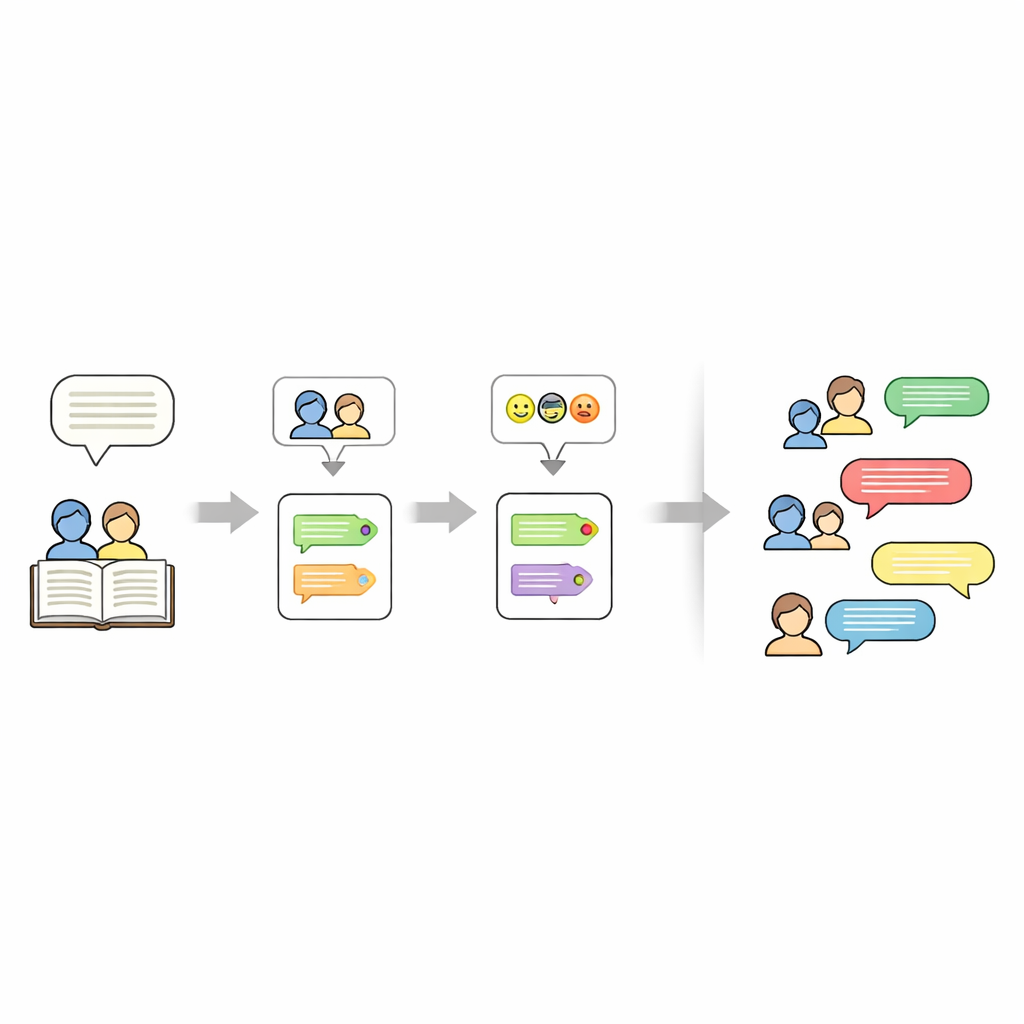
测试准确性与实际应用
为检验说话人标签的可靠性,团队对数百句对话进行了人工复核。单独使用 BookNLP 时,大约能正确归属73%的话语,但与 FastCoref 结合后,准确率跃升至约90%,在包含大量代词的段落中提升尤为明显。他们还分析了情绪在句间的流动,发现了符合现实的模式:例如,喜悦常在喜悦之后或导致惊讶,而悲伤更可能向愤怒发展,而不是瞬间转为喜悦。最后,他们在该数据上微调了生成式语言模型,展示其能生成在很大程度上保留所需情绪或故事关键词的新对话,并用于驱动情感文本转语音系统,听众评价其既自然又富有表现力。
这对未来故事意味着什么
简而言之,这项工作将普通儿童故事转化为一张丰富的地图,标明谁在说话、他们的情绪如何变化以及故事讲述的主题。数据集让计算机不再把文本视为平面的词流,而能跟踪角色及其逐句变化的情绪。这使其成为未来应用的有力构件,从以恰当语气表演各角色的有声书,到对儿童情绪作出敏感响应的创作工具和教育游戏。通过开放发布这一结构化且具情感感知的语料,作者为研究人员提供了研究与构建真正富有表现力的叙事系统的新途径。
引用: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
关键词: 情感感知对话, 讲故事数据集, 说话人归属, 情感语音合成, 叙事人工智能