Clear Sky Science · ar
مجموعة بيانات حوارية سردية: مجموعة محادثات معنونة بالمتحدث والعاطفة
لماذا تهم القصص المتكلمة
عندما نقرأ قصة، نتابع بطبيعة الحال مَنْ يتكلم وما الذي يشعر به. الحواسيب، مع ذلك، تواجه صعوبة مع هذا النوع من الحوار الدقيق والمشحون عاطفياً. تعرض هذه الورقة مجموعة بيانات جديدة تساعد الآلات على فهم حوار القصة كما يفعل البشر: ليس فقط الكلمات، بل أي شخصية تتكلم وما العاطفة التي تعبر عنها. تم بناء المصدر من آلاف قصص الأطفال وصُمم لتمكين روبوتات الدردشة، وأنظمة السرد، والكتب الناطقة من أن تكون أكثر طبيعية وواعية عاطفياً.
تحويل القصص إلى محادثات
بدأ الباحثون من 2588 قصة قصيرة إنجليزية للأطفال جُمعت من مستودع عبر الإنترنت. كل قصة كانت تسرد بالفعل شخصياتها الرئيسية، لكن النص نفسه مكتوب نثراً متواصلاً، مع أجزاء من الحوار محاطة بعلامات اقتباس. الهدف كان تحويل هذا الأسلوب الحر إلى نص سيناريو مرتب يتكون من سطور مثل «المتحدث (العاطفة): الحوار»، بحيث يمكن دراسة أو نمذجة أو حتى أداء كل جملة منطوقة بواسطة صوت حاسوبي. في المجموع، يستخرجون أكثر من 27,000 سطر حوار مرتبط بأكثر من 2,500 شخصية مميزة.
تحديد مَن قال ماذا
معرفة مَن يتكلم في القصة أكثر تعقيداً مما يبدو. غالباً ما يستخدم المؤلفون ضمائر مثل «هي» أو عبارات مثل «الطفل» بدلاً من تكرار الأسماء. لفك هذا الالتباس، تقوم سلسلة المعالجة أولاً بإخفاء كل سطر مقتبس مؤقتاً، ثم تشغّل أداة تسمى FastCoref لتعقب الضمائر والوصف والرجوع بها إلى الشخصية الصحيحة. بعد استعادة الحوار الأصلي، تعين أداة أخرى، BookNLP، كل سطر إلى متحدث محدد كما تضع وسمات أساسية للشخصيات مثل الجنس. تعتبر السطور غير المحاطة بعلامات اقتباس سرداً يصدر عن «الراوي» الضمني وتمنح وسم عاطفي محايد، حتى يمكن تمثيل القصة الكاملة على شكل سيناريو.
تعليم الآلات إدراك العواطف
بعد ذلك، يوسم الباحثون النبرة العاطفية لكل سطر حوار. يدربون نموذج شبكة عصبية على مجموعة تغريدات كبيرة حيث وُسِمت النصوص القصيرة بإحدى ست عواطف: الفرح، الحزن، الغضب، الخوف، الحب، والمفاجأة. يستخدم النموذج GRU ثنائي الاتجاه، وهو نوع من الشبكات المتكررة الجيدة في معالجة ترتيب الكلمات في الجمل. بعد تنظيف وتجزيء النصوص إلى وحدات، يدربون النموذج مع وزن إضافي للعواطف النادرة لتقليل التحيز. على بيانات تويتر المحجوزة للاختبار يصل النموذج إلى نحو 94% دقة إجمالاً. يُطبّق هذا النموذج المدرب بعد ذلك على حوارات القصص، معيناً عاطفة لكل سطر دون تغيير صياغته، حتى يبقى الأسلوب الأدبي الأصلي محفوظاً.
التقاط جوهر كل قصة
إلى جانب مَن يتكلم وكيف يشعر، تسجل مجموعة البيانات أيضاً ماذا تدور حوله كل قصة. لهذا الغرض يستخدم المؤلفون نموذج لغة كبير (Mistral-7B) مع موجه مصمم بعناية يطلب بالضبط خمس كلمات مفتاحية مأخوذة من نص القصة. تعمل هذه الكلمات المفتاحية كملخص مدمج—مثل أسماء، أماكن، أو أشياء مركزية—ويمكن استخدامها لاحقاً لـ«توجيه» توليدات قصة جديدة. النتيجة النهائية هي تمثيل متعدد الطبقات لكل قصة: مجموعة من الكلمات المفتاحية، قائمة بالشخصيات، ونص سيناريو حيث يحتوي كل سطر على وسم المتحدث والعاطفة. 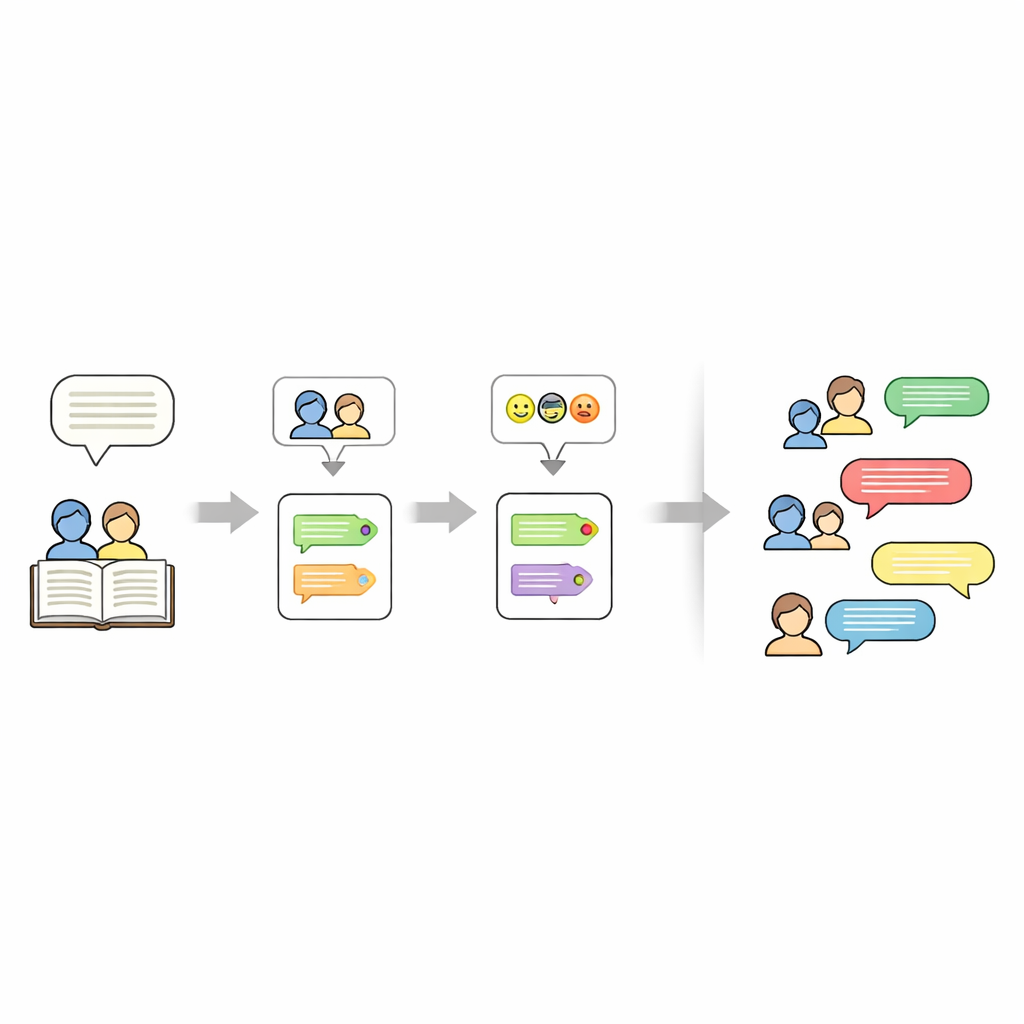
اختبار الدقة والاستخدام العملي
للتحقق من مدى موثوقية وسوم المتحدثين، يراجع الفريق يدوياً مئات السطور الحوارية. باستخدام BookNLP وحدها تُنسب نحو 73% من المقاطع بشكل صحيح، لكن عند دمجها مع FastCoref ترتفع الدقة لتصل إلى نحو 90%، خاصة في المقاطع التي تحتوي على الكثير من الضمائر. كما يحللون كيف تتدفق العواطف من سطر إلى التالي ويجدون أنماطاً واقعية: على سبيل المثال، الفرح غالباً ما يتبع الفرح أو يؤدي إلى المفاجأة، بينما من المرجح أن ينتقل الحزن نحو الغضب أكثر من أن يتحول فوراً إلى الفرح. أخيراً، يقومون بضبط نموذج لغوي توليدي على هذه البيانات، مظهرين أنه يمكنه إنتاج حوارات جديدة تحافظ إلى حد كبير على العاطفة المطلوبة أو كلمات القصة المفتاحية، ويشغلون نظام تحويل نص إلى كلام عاطفي يقيمه المستمعون على أنه طبيعي ومعبر بشكل مناسب.
ماذا يعني هذا للقصص المستقبلية
بعبارات بسيطة، يحول هذا العمل قصص الأطفال العادية إلى خريطة غنية لمن يتكلم، وكيف يشعر، وما تدور حوله الحكاية. بدلاً من معالجة النص كسيرٍ متساوٍ من الكلمات، تتيح مجموعة البيانات للحواسيب متابعة الشخصيات وتقلبات مشاعرها من سطر إلى آخر. هذا يجعلها لبنة قوية لتطبيقات مستقبلية، من الكتب الصوتية التي تؤدي كل شخصية بالنبرة المناسبة، إلى أدوات الكتابة الإبداعية والألعاب التعليمية التي تستجيب بحساسية لمزاج الطفل. من خلال الإفراج الحر عن هذه المجموعة المهيكلة والواعية عاطفياً، يمنح المؤلفون الباحثين وسيلة جديدة لدراسة وبناء أنظمة سردية معبرة بحق.
الاستشهاد: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
الكلمات المفتاحية: حوارات واعية بالعاطفة, مجموعة بيانات سردية, نسبة المتحدث, توليد كلام عاطفي, الذكاء الاصطناعي السردي