Clear Sky Science · tr
Anlatı Diyalog Veriseti: Konuşmacı ve Duygu İlişkilendirilmiş Konuşma Korposu
Neden konuşan hikâyeler önemli
Bir hikâyeyi okurken kim konuşuyor ve nasıl hissettiğini içgüdüsel olarak takip ederiz. Ancak bilgisayarlar bu tür ince, duygusal konuşmaları anlamakta zorluk çeker. Bu makale, makinelerin hikâye diyaloglarını insanların anladığı şekilde —sadece sözcükleri değil, hangi karakterin konuştuğunu ve hangi duyguyu ifade ettiğini— kavramasına yardımcı olan yeni bir veri seti tanıtıyor. Kaynak, binlerce çocuk hikâyesinden derlenmiş olup daha doğal, duygu farkında sohbet botları, hikâye anlatım sistemleri ve konuşan kitaplar geliştirmek için tasarlandı.
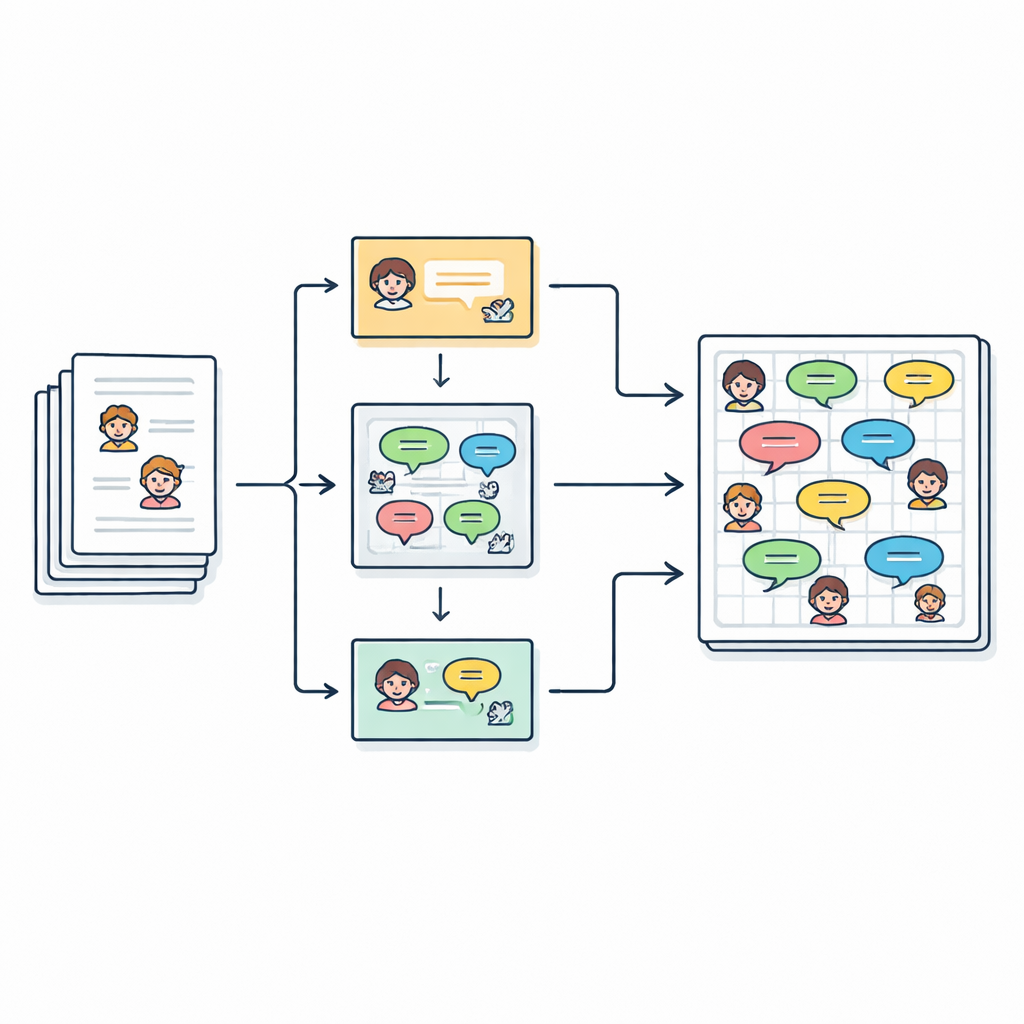
Hikâyeleri diyaloga dönüştürmek
Yazarlar, çevrimiçi bir arşivden toplanmış 2.588 İngilizce çocuk kısa hikâyesi ile başlıyor. Her hikâyede zaten ana karakterler listelenmiş olsa da metin sürekli düzyazı şeklindedir ve konuşma parçaları tırnak işaretleri içinde gömülüdür. Ekipin amacı, bu serbest biçimli yazıyı “Konuşmacı (Duygu): Diyalog” gibi satırlardan oluşan temiz bir senaryoya dönüştürmek; böylece her konuşulan cümle bilgisayar tarafından incelenebilsin, modellenebilsin veya hatta bir bilgisayar sesi tarafından seslendirilebilsin. Toplamda 2.500’den fazla ayrı karaktere bağlı 27.000’den fazla diyalog satırı çıkarılıyor.
Kim ne söylemişi bulmak
Bir hikâyede kimin konuştuğunu belirlemek göründüğünden daha zordur. Yazarlar genellikle isimleri tekrar etmek yerine “o” gibi zamirler veya “çocuk” gibi ifadeler kullanır. Bunu çözmek için iş akışı önce her tırnak içindeki konuşma satırını geçici olarak maskeler, ardından zamirleri ve betimlemeleri doğru karaktere geri izlemek için FastCoref adlı bir araç çalıştırır. Orijinal diyalog geri yüklendikten sonra başka bir araç olan BookNLP her satırı belirli bir konuşmacıya atar ve karakterleri cinsiyet gibi temel özelliklerle etiketler. Tırnak işareti olmayan satırlar anlatı olarak ele alınır, örtük bir “Anlatıcı” tarafından söylenmiş sayılır ve nötr bir duygusal etiket verilir; böylece tüm hikâye senaryo biçiminde temsil edilebilir.
Makinelere duyguyu duyurmayı öğretmek
Sonraki adımda araştırmacılar her diyalog satırının duygusal tonunu etiketler. Altı duygudan biriyle etiketlenmiş kısa metinler içeren büyük bir Twitter veri seti üzerinde bir sinir ağı modeli eğitirler: neşe, üzüntü, öfke, korku, sevgi ve şaşkınlık. Model, cümlelerdeki sözcük sırasını iyi işleyebilen çift yönlü bir GRU (Gated Recurrent Unit) türü tekrarlayan sinir ağı kullanır. Metin temizlendikten ve tokenleştirdikten sonra daha nadir duyguların etkisini azaltmak için eğitim sırasında bu duygulara ekstra ağırlık verirler. Ayrılmış Twitter verisi üzerinde model genel olarak yaklaşık %94 doğruluk elde eder. Bu eğitimli model daha sonra hikâye diyaloglarına uygulanır ve her satıra, orijinal edebi üslubu değiştirmeden bir duygu atar.
Her öykünün özünü yakalamak
Kim konuşuyor ve nasıl hissettikleri dışında veri seti her hikâyenin ne hakkında olduğunu da kaydeder. Bunun için yazarlar, hikâye metninden tam olarak beş anahtar kelime istemek üzere dikkatle tasarlanmış bir istem kullanan büyük bir dil modeli (Mistral-7B) kullanır. Bu anahtar kelimeler isimler, mekanlar veya merkezî nesneler gibi kompakt bir özet işlevi görür ve daha sonra yeni hikâye üretimlerini “yönlendirmek” için kullanılabilir. Nihai sonuç her hikâye için katmanlı bir temsildir: bir anahtar kelime seti, bir karakter listesi ve her satırın konuşmacı ve duygu etiketi taşıdığı bir senaryo. 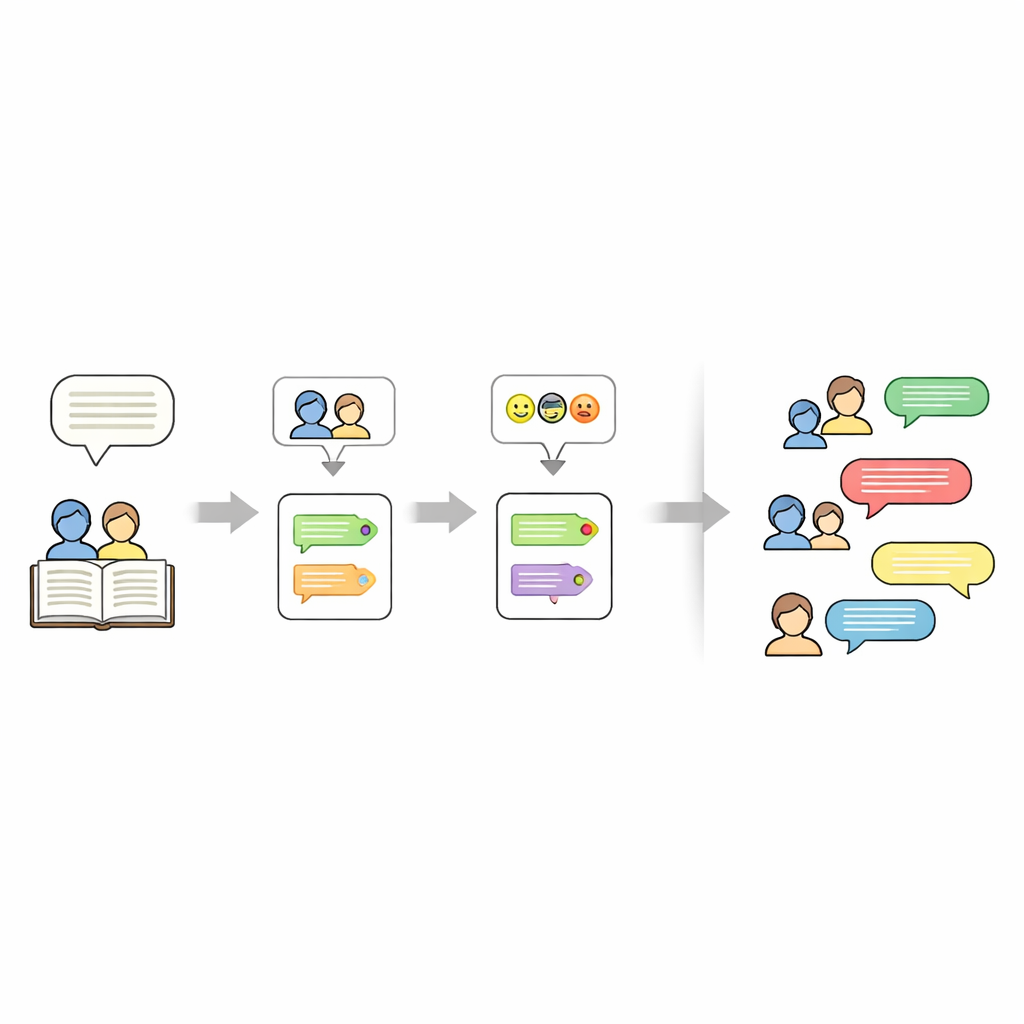
Doğruluk testi ve gerçek dünya kullanımı
Konuşmacı etiketlerinin ne kadar güvenilir olduğunu kontrol etmek için ekip yüzlerce diyalog satırını elle gözden geçirir. Yalnızca BookNLP kullanıldığında söylemlerin yaklaşık %73’ü doğru atanırken, FastCoref ile birleştirildiğinde doğruluk yaklaşık %90’a çıkar; özellikle çok sayıda zamirin bulunduğu pasajlarda bu artış belirgindir. Ayrıca duyguların bir satırdan diğerine nasıl aktığını analiz ederler ve gerçekçi desenler bulurlar: örneğin neşe genellikle neşeyi takip eder veya şaşkınlığa yol açar, oysa üzüntü aniden neşeye dönmekten ziyade öfkeye doğru kayma eğilimindedir. Son olarak, bu veri üzerinde bir üretken dil modelini ince ayar yaparak, istenen duygu veya hikâye anahtar kelimelerini büyük ölçüde koruyan yeni diyaloglar üretebildiğini gösterirler ve bir duygusal metin-konuşma sistemini yönlendirirler; dinleyiciler bu çıkışı hem doğal hem de ifadeye uygun olarak değerlendirir.
Gelecek hikâyeler için bunun anlamı
Basitçe söylemek gerekirse, bu çalışma sıradan çocuk hikâyelerini kim konuşuyor, nasıl hissediyor ve öykü neyle ilgili gibi zengin bir haritaya dönüştürüyor. Metni düz bir sözcük akışı olarak ele almak yerine veri seti bilgisayarların karakterleri ve satır satır değişen duygularını takip etmesini sağlıyor. Bu da doğru tonla her karakteri seslendiren sesli kitaplardan, yaratıcı yazım araçlarına ve çocuğun ruh haline duyarlı yanıt veren eğitim oyunlarına kadar gelecekteki uygulamalar için güçlü bir yapı taşı yapıyor. Yazarlar bu yapılandırılmış, duygu farkında korpusu özgürce erişilebilir kılarak araştırmacılara gerçekten ifadeli anlatı sistemleri incelemek ve inşa etmek için yeni bir yol sunuyor.
Atıf: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Anahtar kelimeler: duygu farkında diyalog, hikâye anlatımı veri seti, konuşmacı atıfı, duygusal konuşma sentezi, anlatısal yapay zeka