Clear Sky Science · pt
Conjunto de Dados de Diálogo Narrativo: Corpus Conversacional Anotado por Falante e Emoção
Por que histórias faladas importam
Quando lemos uma história, instintivamente acompanhamos quem está falando e como essa pessoa se sente. Computadores, no entanto, têm dificuldade com esse tipo de conversa sutil e carregada de emoção. Este artigo apresenta um novo conjunto de dados que ajuda máquinas a entender diálogos em histórias do modo como as pessoas fazem: não apenas as palavras, mas qual personagem está falando e qual emoção ele está expressando. O recurso foi construído a partir de milhares de histórias infantis e foi projetado para alimentar chatbots mais naturais e sensíveis emocionalmente, sistemas de narração e livros falantes.
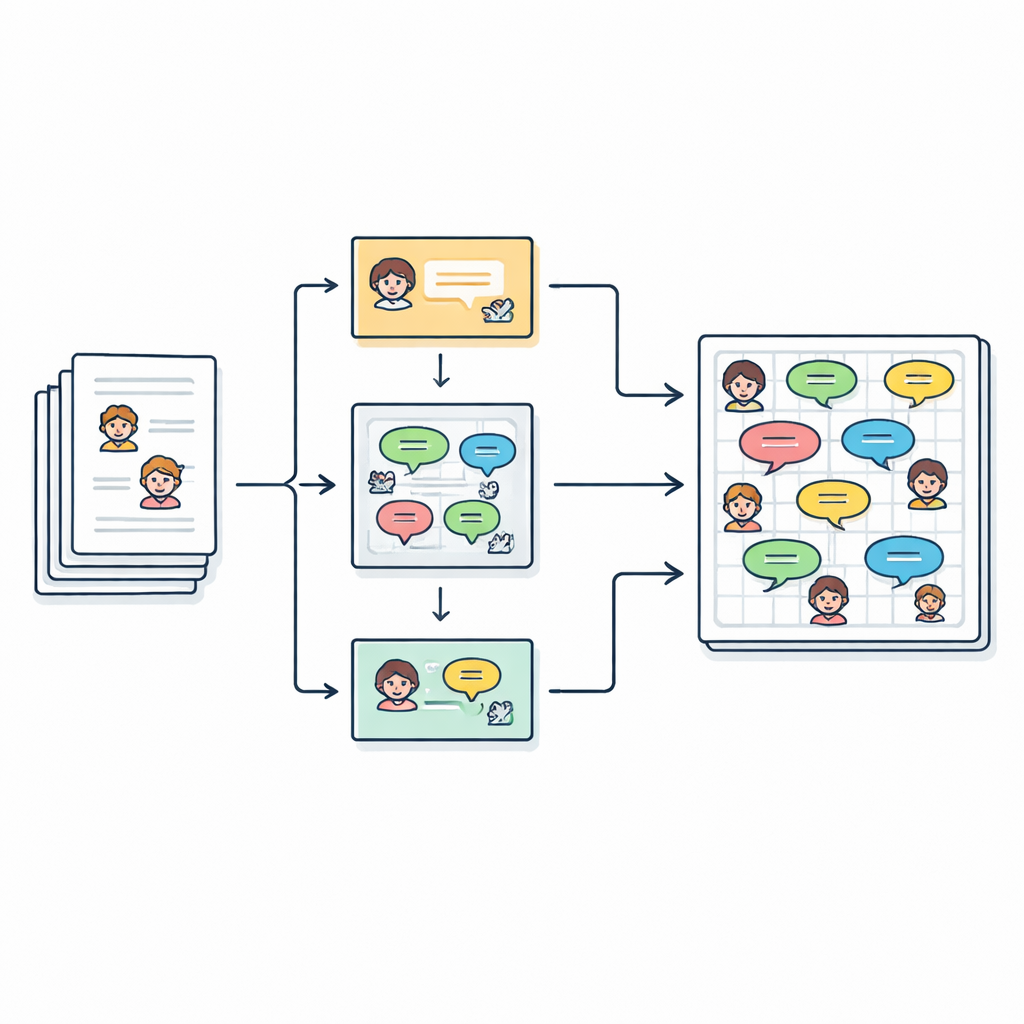
Transformando histórias em conversas
Os autores partem de 2.588 contos infantis em inglês coletados de um repositório online. Cada história já lista seus personagens principais, mas o texto em si é escrito em prosa contínua, com trechos de diálogo entre aspas. O objetivo da equipe é transformar essa escrita em forma livre em um roteiro limpo composto por linhas do tipo “Falante (Emoção): Diálogo”, de modo que cada frase dita possa ser estudada, modelada ou mesmo interpretada por uma voz computacional. No total, eles extraem mais de 27.000 linhas de diálogo vinculadas a mais de 2.500 personagens distintos.
Descobrindo quem disse o quê
Determinar quem está falando numa história é mais complicado do que parece. Autores frequentemente usam pronomes como “ela” ou frases como “a criança” em vez de repetir nomes. Para desenredar isso, o pipeline primeiramentes mascara temporariamente cada linha entre aspas e então executa uma ferramenta chamada FastCoref para rastrear pronomes e descrições até o personagem correto. Depois de restaurar o diálogo original, outra ferramenta, BookNLP, atribui cada linha a um falante específico e também marca personagens com traços básicos, como gênero. Linhas que não estão entre aspas são tratadas como narração, ditas por um “Narrador” implícito e recebem um rótulo emocional neutro, para que a história completa possa ser representada em forma de roteiro.
Ensinando máquinas a reconhecer emoções
Em seguida, os pesquisadores rotulam o tom emocional de cada linha de diálogo. Eles treinam um modelo de rede neural em um grande conjunto de dados do Twitter onde textos curtos foram etiquetados com uma de seis emoções: alegria, tristeza, raiva, medo, amor e surpresa. O modelo usa um GRU bidirecional, um tipo de rede recorrente adequada para lidar com a ordem das palavras nas frases. Após limpar e tokenizar o texto, treinam o modelo dando peso extra às emoções mais raras para reduzir viés. Em dados de Twitter retidos para validação, ele atinge cerca de 94% de acurácia geral. Esse modelo treinado é então aplicado aos diálogos das histórias, atribuindo uma emoção a cada linha sem alterar a redação, de modo que o estilo literário original é preservado.
Capturando a essência de cada conto
Além de quem fala e como se sente, o conjunto de dados também registra sobre o que cada história trata. Para isso, os autores usam um grande modelo de linguagem (Mistral-7B) com um prompt cuidadosamente elaborado que solicita exatamente cinco palavras-chave extraídas do texto da história. Essas palavras-chave funcionam como um resumo compacto — por exemplo, nomes, locais ou objetos centrais — e podem ser usadas posteriormente para “guiar” a geração de novas histórias. O resultado final é uma representação em camadas para cada história: um conjunto de palavras-chave, uma lista de personagens e um roteiro em que cada linha tem um falante e uma etiqueta de emoção. 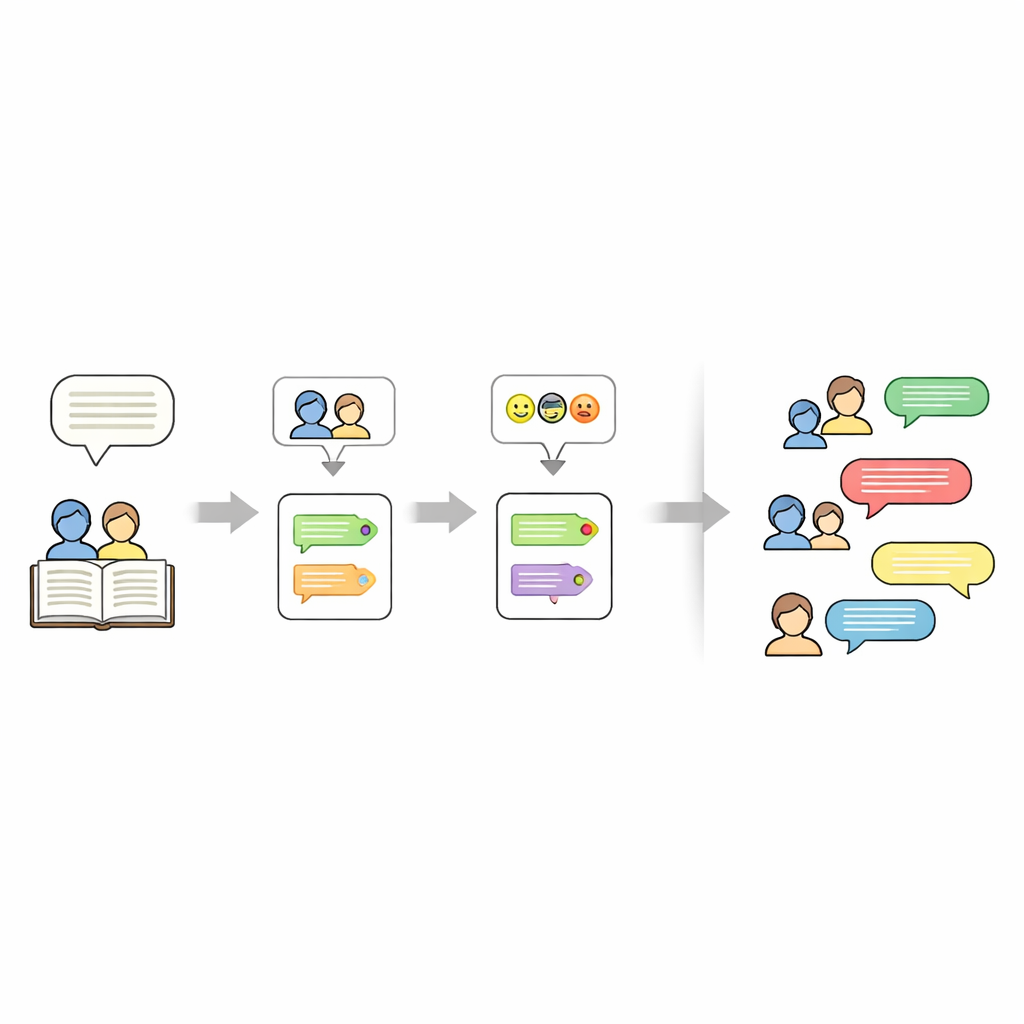
Testando acurácia e uso no mundo real
Para verificar quão confiáveis são os rótulos de falante, a equipe revisa manualmente centenas de linhas de diálogo. Usando apenas o BookNLP, cerca de 73% das falas são atribuídas corretamente, mas quando combinado com o FastCoref, a acurácia sobe para cerca de 90%, especialmente em trechos com muitos pronomes. Eles também analisam como as emoções fluem de uma linha para a seguinte e encontram padrões realistas: por exemplo, alegria frequentemente sucede alegria ou leva à surpresa, enquanto tristeza tende a evoluir para raiva com mais probabilidade do que mudar instantaneamente para alegria. Finalmente, eles afinam um modelo generativo de linguagem com esses dados, mostrando que ele pode produzir novos diálogos que em grande parte preservam a emoção ou as palavras-chave solicitadas, e alimentam um sistema de texto-para-fala emocional que ouvintes avaliam como natural e expressivamente apropriado.
O que isso significa para histórias futuras
Em termos simples, este trabalho transforma histórias infantis comuns em um mapa rico de quem está falando, como se sente e sobre o que trata o conto. Em vez de tratar o texto como um fluxo plano de palavras, o conjunto de dados permite que computadores sigam personagens e suas emoções mutantes de linha a linha. Isso o torna um bloco de construção poderoso para aplicações futuras, desde audiolivros que interpretam cada personagem com o tom correto até ferramentas de escrita criativa e jogos educativos que respondem sensivelmente ao humor da criança. Ao liberar gratuitamente esse corpus estruturado e sensível às emoções, os autores oferecem aos pesquisadores uma nova maneira de estudar e construir sistemas narrativos verdadeiramente expressivos.
Citação: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Palavras-chave: diálogo sensível à emoção, conjunto de dados de narrativa, atribuição de falante, síntese de fala emocional, IA narrativa