Clear Sky Science · ru
Набор диалогов в рассказах: корпус бесед с разметкой говорящих и эмоций
Почему говорящие истории важны
Когда мы читаем рассказ, мы инстинктивно отслеживаем, кто говорит и что при этом чувствует. Компьютерам же это даётся плохо: тонкая эмоциональная сторона диалога остаётся для них трудной. В этой статье представлен новый набор данных, который помогает машинам понимать диалоги в рассказах так, как это делают люди: не только фиксировать слова, но и определять, какой персонаж говорит и какую эмоцию он выражает. Ресурс создан на основе тысяч детских рассказов и предназначен для обеспечения более естественных, эмоционально чувствительных чатботов, систем рассказов и говорящих книг.
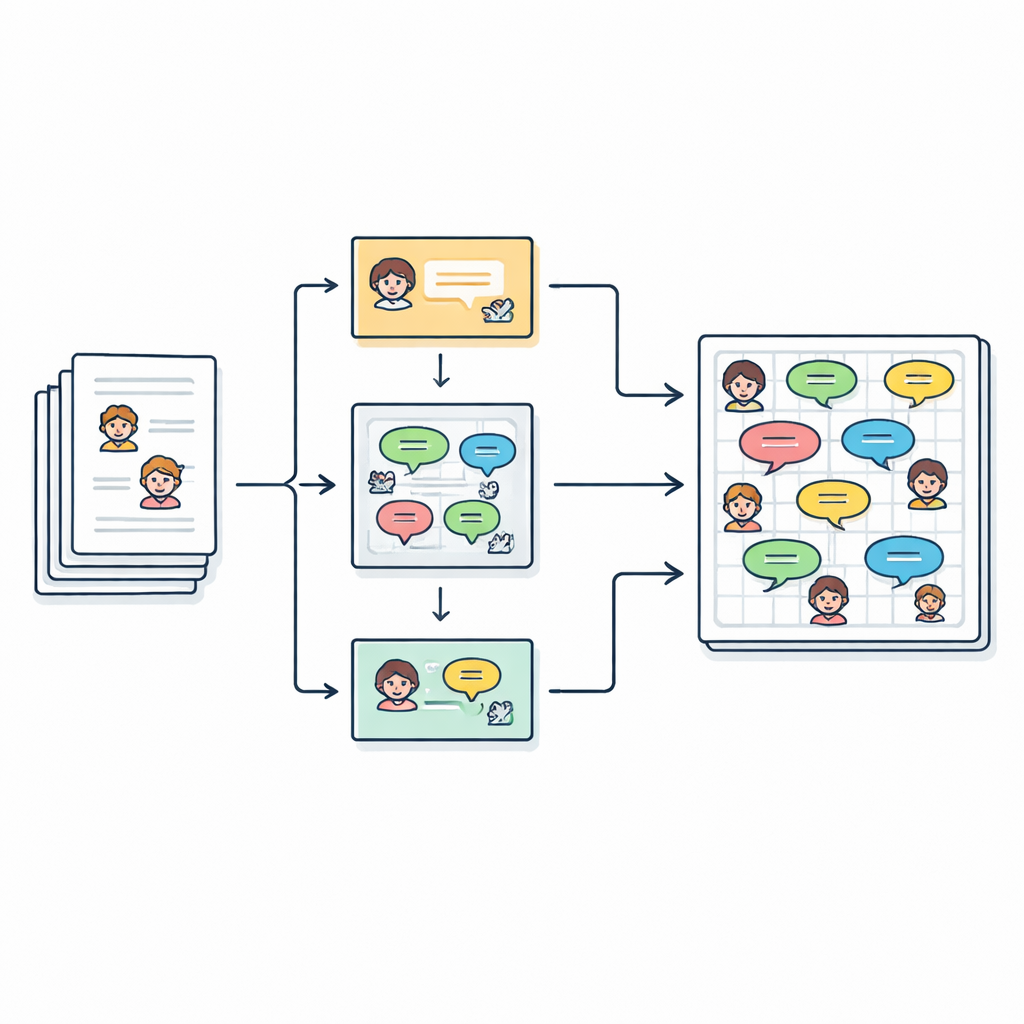
Преобразование рассказов в диалоги
Авторы начинают с 2 588 коротких английских детских рассказов, собранных из онлайн-репозитория. В каждом рассказе уже перечислены основные персонажи, но сам текст написан как непрерывная проза, с кусками диалогов в кавычках. Цель команды — превратить этот свободный текст в аккуратный сценарий вида «Говорящий (Эмоция): Реплика», чтобы каждую произнесённую фразу можно было изучать, моделировать или даже воспроизводить голосом компьютера. В сумме они извлекают более 27 000 реплик, связанных с более чем 2 500 различными персонажами.
Определение, кто что сказал
Выяснить, кто говорит в рассказе, сложнее, чем кажется. Авторы часто используют местоимения вроде «она» или описания вроде «ребёнок» вместо повторения имени. Чтобы распутать это, конвейер сначала временно маскирует каждую цитируемую строку речи, затем запускает инструмент FastCoref, который отслеживает местоимения и описания и связывает их с нужным персонажем. После восстановления исходного диалога другой инструмент, BookNLP, назначает каждой реплике конкретного говорящего и также отмечает у персонажей базовые характеристики, например пол. Строки, не взятые в кавычки, рассматриваются как повествование, произносимое подразумеваемым «Нарратором», и получают нейтральную метку эмоции, чтобы весь рассказ можно было представить в виде сценария.
Обучение машин распознавать эмоции
Далее исследователи размечают эмоциональную окраску каждой реплики. Они обучают нейронную сеть на большом наборе твитов, где короткие тексты помечены одной из шести эмоций: радость, печаль, гнев, страх, любовь и удивление. Модель использует двунаправленный GRU — вид рекуррентной сети, хорошо учитывающий порядок слов в предложении. После очистки и токенизации текста модель обучают с дополнительным весом для редких эмоций, чтобы снизить смещение. На отложенных данных Twitter она достигает примерно 94% точности в целом. Эту обученную модель затем применяют к диалогам из рассказов, присваивая каждой реплике эмоцию без изменения формулировок, чтобы сохранить оригинальный литературный стиль.
Фиксация сути каждого рассказа
Помимо того, кто говорит и какие у него чувства, набор данных также фиксирует, о чём каждый рассказ. Для этого авторы используют большую языковую модель (Mistral-7B) с тщательно продуманным промптом, который запрашивает ровно пять ключевых слов, взятых из текста рассказа. Эти ключевые слова служат компактным резюме — например, имена, места или центральные объекты — и позднее могут использоваться для «управления» генерацией новых рассказов. Итогом является многослойное представление для каждого рассказа: набор ключевых слов, список персонажей и сценарий, где каждая строка снабжена метками говорящего и эмоции. 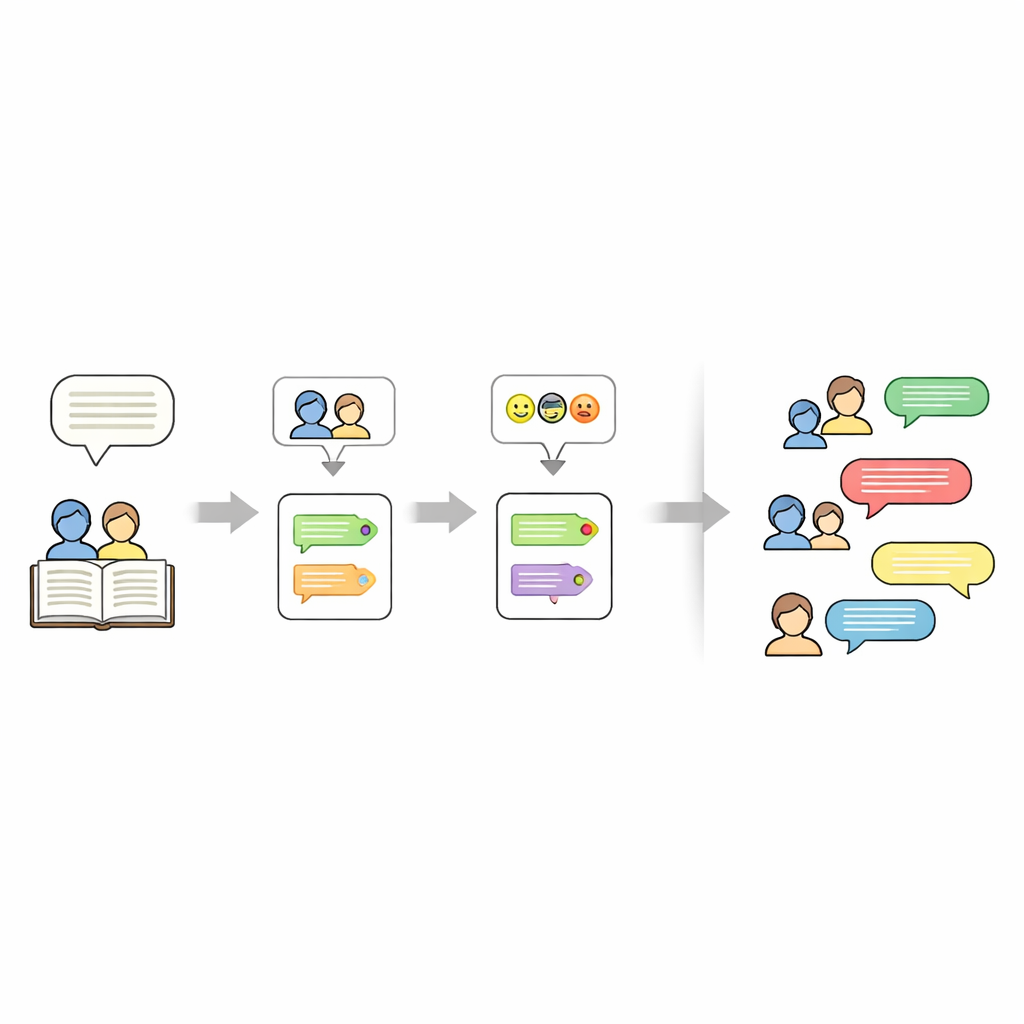
Проверка точности и практическое применение
Чтобы оценить надёжность меток говорящих, команда вручную проверяет сотни реплик. При использовании только BookNLP правильная атрибуция составляет около 73%, но в сочетании с FastCoref точность подскакивает примерно до 90%, особенно в отрывках с большим количеством местоимений. Они также анализируют, как эмоции переходят от одной реплики к следующей, и находят правдоподобные закономерности: например, радость часто следует за радостью или ведёт к удивлению, тогда как печаль чаще эволюционирует в гнев, чем мгновенно меняется на радость. Наконец, они дообучают генеративную языковую модель на этих данных и показывают, что она может создавать новые диалоги, которые в значительной степени сохраняют заданную эмоцию или ключевые слова рассказа, а также управляют системой эмоционального синтеза речи, которую слушатели оценивают как естественную и выразительно уместную.
Что это значит для будущих историй
Проще говоря, эта работа превращает обычные детские рассказы в богатую карту того, кто говорит, что испытывает и о чём повествование. Вместо того чтобы рассматривать текст как плоскую цепочку слов, набор данных позволяет компьютерам отслеживать персонажей и их меняющиеся эмоции от строки к строке. Это делает его мощным строительным блоком для будущих приложений: от аудиокниг, которые озвучивают каждого персонажа с подходящим тоном, до инструментов творческого письма и образовательных игр, чувствительно реагирующих на настроение ребёнка. Путём свободного распространения этой структурированной, эмоционально осознанной коллекции авторы дают исследователям новый способ изучать и создавать по-настоящему выразительные повествовательные системы.
Цитирование: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Ключевые слова: диалог с учётом эмоций, набор данных рассказов, определение говорящего, синтез эмоциональной речи, повествовательный ИИ