Clear Sky Science · sv
Datasätt för berättande dialog: Konversationskorpus med talar- och känsloannotering
Varför talande berättelser är viktiga
När vi läser en berättelse håller vi intuitivt reda på vem som talar och hur denne känner sig. Datorer har däremot svårt med denna typ av subtila, emotionella samtal. Denna artikel introducerar ett nytt dataset som hjälper maskiner att förstå berättelsedialog som människor gör: inte bara orden, utan också vilken karaktär som talar och vilken känsla som uttrycks. Resursen bygger på tusentals barnberättelser och är utformad för att driva mer naturliga, känslomedvetna chattbotar, berättandesystem och talande böcker.
Att förvandla berättelser till konversationer
Författarna utgår från 2 588 engelska barnkortberättelser insamlade från ett onlinearkiv. Varje berättelse listar redan sina huvudkaraktärer, men själva texten är skriven som kontinuerlig prosa med insprängda dialogpartier inom citationstecken. Teamets mål är att omvandla detta friformsskrivna material till ett rent manus bestående av rader som “Talare (Känsla): Dialog”, så att varje uttalad mening kan studeras, modelleras eller till och med framföras av en datorröst. Totalt extraherar de över 27 000 dialograder kopplade till mer än 2 500 distinkta karaktärer.
Att hitta vem som sa vad
Att avgöra vem som talar i en berättelse är mer komplicerat än det låter. Författare använder ofta pronomen som “hon” eller fraser som “barnet” istället för att upprepa namn. För att reda ut detta maskerar pipelinen först temporärt varje citerad replik, kör sedan ett verktyg kallat FastCoref för att spåra pronomen och beskrivningar tillbaka till rätt karaktär. Efter att ha återställt den ursprungliga dialogen tilldelar ett annat verktyg, BookNLP, varje rad till en specifik talare och märker även karaktärerna med grundläggande egenskaper som kön. Rader som inte står inom citationstecken behandlas som berättande, talade av en implicit “Berättare” och får en neutral känselapp, så att hela berättelsen kan representeras i manusform.
Att lära maskiner att uppfatta känslor
Nästa steg är att forskarna etiketterar den emotionella tonen i varje dialograd. De tränar en neuralt nätverksmodell på ett stort Twitter-dataset där korta texter märkts med en av sex känslor: glädje, sorg, ilska, rädsla, kärlek och överraskning. Modellen använder en bidirektionell GRU, en typ av återkommande neuralt nätverk som är bra på att hantera ordningsföljd i meningar. Efter rensning och tokenisering av texten tränar de modellen med extra vikt på ovanligare känslor för att minska bias. På hållutdata från Twitter når den ungefär 94 % noggrannhet totalt. Denna tränade modell appliceras sedan på berättelsedialogerna och tilldelar en känsla till varje rad utan att ändra ordalydelsen, så att den ursprungliga litterära stilen bevaras.
Att fånga varje berättelses kärna
Utöver vem som talar och hur de känner sig, registrerar datasetet också vad varje berättelse handlar om. För detta använder författarna en stor språkmodell (Mistral-7B) med en väl utformad prompt som ber om exakt fem nyckelord hämtade ur berättelsetexten. Dessa nyckelord fungerar som en kompakt sammanfattning—till exempel namn, platser eller centrala föremål—och kan senare användas för att “styra” ny berättelsegenerering. Slutresultatet är en lagerindelad representation för varje berättelse: en uppsättning nyckelord, en lista över karaktärer och ett manus där varje rad har en talare och en känsletagg. 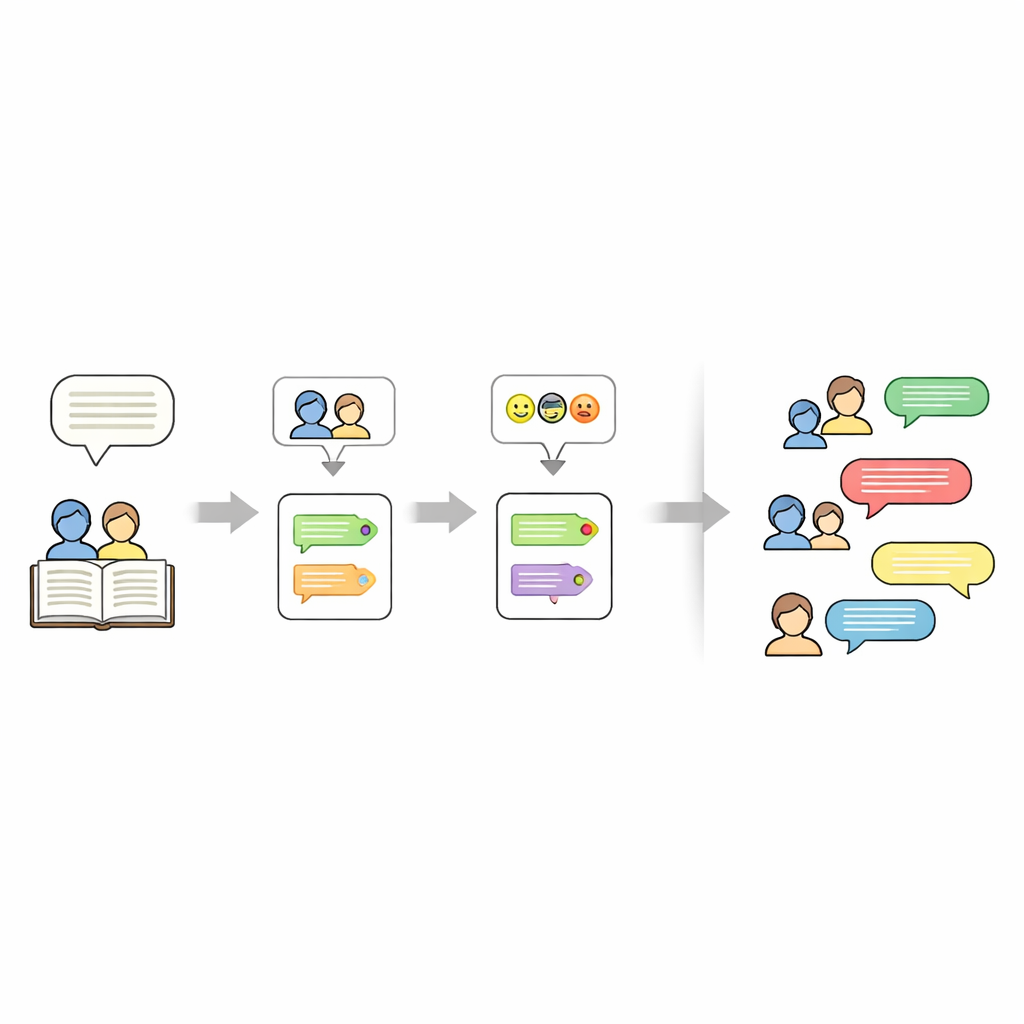
Test av noggrannhet och användning i verkligheten
För att kontrollera hur tillförlitliga talaretiketterna är granskar teamet manuellt hundratals dialograder. Med enbart BookNLP tilldelas ungefär 73 % av yttrandena korrekt, men när det kombineras med FastCoref skjuter noggrannheten upp till omkring 90 %, särskilt i passager med många pronomen. De analyserar också hur känslor flyter från en rad till nästa och finner realistiska mönster: till exempel följer glädje ofta på glädje eller leder till överraskning, medan sorg är mer benägen att röra sig mot ilska än att omedelbart växla till glädje. Slutligen finjusterar de en generativ språkmodell på denna data och visar att den kan producera ny dialog som i hög grad bevarar den begärda känslan eller berättelsens nyckelord, och de driver ett emotionellt text-till-tal-system som lyssnare bedömer som både naturligt och uttrycksfullt lämpligt.
Vad detta innebär för framtida berättelser
Enkelt uttryckt förvandlar detta arbete vanliga barnberättelser till en rik karta över vem som talar, hur de känner och vad sagan handlar om. Istället för att behandla text som ett platt flöde av ord låter datasetet datorer följa karaktärer och deras skiftande känslor rad för rad. Detta gör det till en kraftfull byggsten för framtida tillämpningar, från ljudböcker som framför varje karaktär med rätt ton, till kreativa skrivverktyg och pedagogiska spel som reagerar känsligt på ett barns sinnesstämning. Genom att fritt tillgängliggöra detta strukturerade, känslomedvetna korpus ger författarna forskare ett nytt sätt att studera och bygga verkligt uttrycksfulla narrativa system.
Citering: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Nyckelord: känsloanpassad dialog, dataset för berättande, talarattribuering, emotionell talsyntes, berättande AI