Clear Sky Science · de
Erzählte Dialogdaten: Gesprächskorpus mit Sprecher- und Emotionsannotationen
Warum sprechende Geschichten wichtig sind
Wenn wir eine Geschichte lesen, behalten wir instinktiv im Blick, wer spricht und wie sich die Person fühlt. Computer tun sich jedoch schwer mit dieser Art von subtilen, emotionalen Gesprächen. Dieses Paper stellt einen neuen Datensatz vor, der Maschinen hilft, Dialoge in Geschichten so zu verstehen, wie Menschen es tun: nicht nur die Worte, sondern auch welcher Charakter spricht und welche Emotion er ausdrückt. Die Ressource basiert auf Tausenden von Kindererzählungen und ist dazu gedacht, natürlichere, emotional bewusste Chatbots, Erzählsysteme und sprechende Bücher zu ermöglichen.
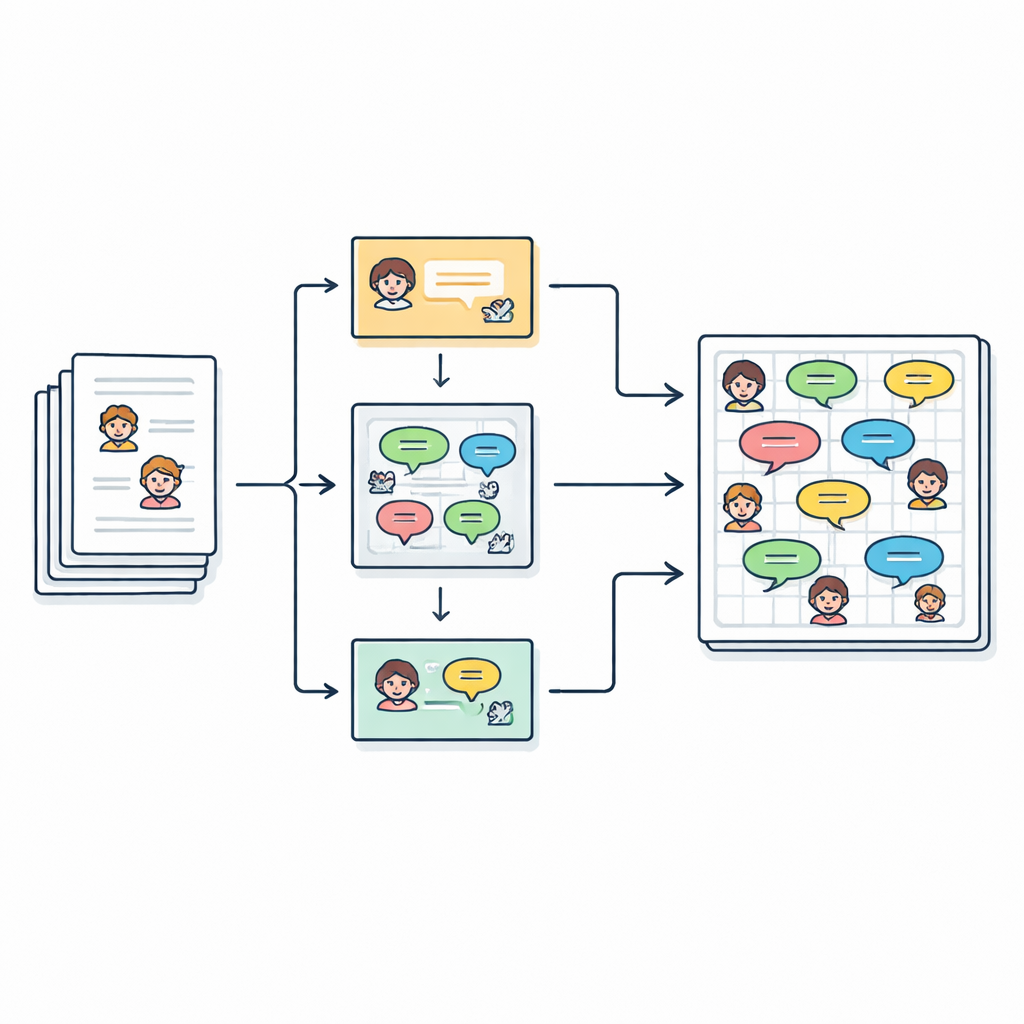
Geschichten in Gespräche verwandeln
Die Autorinnen und Autoren beginnen mit 2.588 englischen Kindergeschichten, die aus einem Online-Archiv gesammelt wurden. Jede Geschichte listet bereits die Hauptfiguren auf, doch der Text selbst ist als fortlaufende Prosa geschrieben, mit Dialogpassagen in Anführungszeichen. Das Ziel des Teams ist es, dieses freie Schreiben in ein sauberes Skript umzuwandeln, bestehend aus Zeilen wie „Sprecher (Emotion): Dialog“, damit jeder gesprochene Satz untersucht, modelliert oder sogar von einer Computerstimme vorgetragen werden kann. Insgesamt extrahieren sie über 27.000 Dialogzeilen, die mehr als 2.500 verschiedenen Charakteren zugeordnet sind.
Herausfinden, wer was gesagt hat
Zu ermitteln, wer in einer Geschichte spricht, ist komplizierter, als es klingt. Autorinnen und Autoren verwenden oft Pronomen wie „sie“ oder Beschreibungen wie „das Kind“ statt die Namen zu wiederholen. Um das zu entwirren, maskiert die Pipeline zunächst vorübergehend jede zitierte Redezeile und nutzt dann ein Tool namens FastCoref, um Pronomen und Beschreibungen zurück zu den richtigen Figuren zu verfolgen. Nach dem Wiederherstellen des ursprünglichen Dialogs weist ein weiteres Tool, BookNLP, jeder Zeile einen spezifischen Sprecher zu und versieht die Figuren zudem mit grundlegenden Merkmalen wie Geschlecht. Zeilen, die nicht in Anführungszeichen stehen, werden als Erzählen behandelt, von einem impliziten „Erzähler“ gesprochen und mit einem neutralen Emotionslabel versehen, sodass die gesamte Geschichte in Skriptform dargestellt werden kann.
Maschinen das Hören von Emotionen beibringen
Als Nächstes etikettieren die Forschenden den emotionalen Ton jeder Dialogzeile. Sie trainieren ein neuronales Netzwerk auf einem großen Twitter-Datensatz, in dem Kurztexte mit einer von sechs Emotionen versehen sind: Freude, Traurigkeit, Wut, Angst, Liebe und Überraschung. Das Modell verwendet ein bidirektionales GRU, eine Form eines rekurrenten neuronalen Netzwerks, das gut mit Wortreihenfolgen in Sätzen umgehen kann. Nach der Bereinigung und Tokenisierung des Textes trainieren sie das Modell mit zusätzlicher Gewichtung seltenerer Emotionen, um Verzerrungen zu verringern. Auf zurückgehaltenen Twitter-Daten erreicht es insgesamt etwa 94 % Genauigkeit. Dieses trainierte Modell wird dann auf die Dialoge der Geschichten angewandt und ordnet jeder Zeile eine Emotion zu, ohne die Wortwahl zu verändern, sodass der ursprüngliche literarische Stil erhalten bleibt.
Das Herz jeder Geschichte erfassen
Über die Frage, wer spricht und wie sich Figuren fühlen, hinaus zeichnet der Datensatz auch auf, worum es in jeder Geschichte geht. Dafür nutzen die Autorinnen und Autoren ein großes Sprachmodell (Mistral-7B) mit einer sorgfältig gestalteten Eingabeaufforderung, die genau fünf Schlüsselwörter verlangt, die dem Story-Text entnommen sind. Diese Schlüsselwörter dienen als kompakte Zusammenfassung — etwa Namen, Orte oder zentrale Gegenstände — und können später verwendet werden, um neue Generierungen zu „steuern“. Das Endergebnis ist eine mehrschichtige Repräsentation für jede Geschichte: eine Menge von Schlüsselwörtern, eine Liste von Figuren und ein Skript, in dem jede Zeile ein Sprecher- und ein Emotions-Tag trägt. 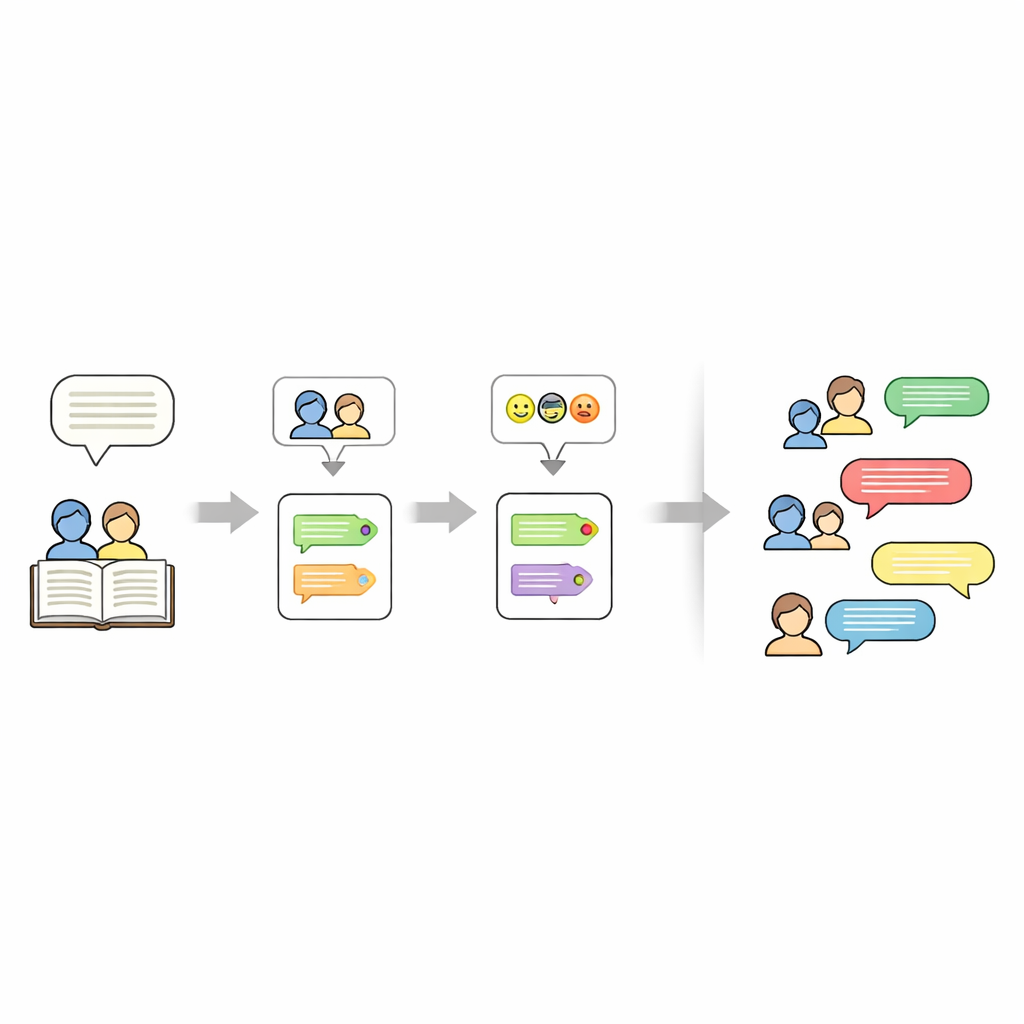
Testen der Genauigkeit und reale Anwendungen
Um die Zuverlässigkeit der Sprecherlabels zu prüfen, bewertet das Team Hunderte von Dialogzeilen manuell. BookNLP allein schreibt etwa 73 % der Äußerungen korrekt zu, aber kombiniert mit FastCoref steigt die Genauigkeit auf rund 90 %, besonders in Passagen mit vielen Pronomen. Sie analysieren außerdem, wie Emotionen von einer Zeile zur nächsten fließen, und finden realistische Muster: Beispielsweise folgt Freude häufig auf Freude oder führt zu Überraschung, während Traurigkeit eher in Wut übergeht als sofort zu Freude zu kippen. Schließlich fine-tunen sie ein generatives Sprachmodell mit diesen Daten und zeigen, dass es neue Dialoge erzeugen kann, die weitgehend die gewünschte Emotion oder die Story-Schlüsselwörter bewahren, und sie betreiben ein emotionales Text-zu-Sprache-System, das von Zuhörern als sowohl natürlich als auch expressiv passend bewertet wird.
Was das für künftige Geschichten bedeutet
Kurz gesagt verwandelt diese Arbeit gewöhnliche Kindergeschichten in eine reiche Karte darüber, wer spricht, wie sich Figuren fühlen und worum es in der Erzählung geht. Anstatt Text als flachen Strom von Wörtern zu behandeln, erlaubt der Datensatz Computern, Figuren und deren wechselnde Emotionen von Zeile zu Zeile zu verfolgen. Das macht ihn zu einem leistungsfähigen Baustein für zukünftige Anwendungen, von Hörbüchern, die jede Figur mit dem richtigen Ton darstellen, bis hin zu kreativen Schreibwerkzeugen und Lernspielen, die sensibel auf die Stimmung eines Kindes reagieren. Indem die Autorinnen und Autoren dieses strukturierte, emotional gebrandmarkte Korpus frei veröffentlichen, geben sie Forschenden ein neues Mittel an die Hand, wirklich ausdrucksstarke narrative Systeme zu untersuchen und zu entwickeln.
Zitation: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Schlüsselwörter: emotionssensibler Dialog, Erzählungs-Datensatz, Sprecherzuordnung, emotionale Sprachsynthese, narrative KI