Clear Sky Science · pl
Zestaw danych dialogowych: korpus konwersacyjny z adnotacjami mówcy i emocji
Dlaczego mówiące historie mają znaczenie
Kiedy czytamy opowiadanie, naturalnie śledzimy, kto mówi i jakie ma emocje. Komputery jednak mają trudności z tego typu subtelnymi, emocjonalnymi rozmowami. Artykuł przedstawia nowy zestaw danych, który pomaga maszynom rozumieć dialog w historii tak, jak robią to ludzie: nie tylko słowa, lecz także to, która postać przemawia i jaką emocję wyraża. Zasób powstał na podstawie tysięcy opowiadań dla dzieci i jest zaprojektowany, by napędzać bardziej naturalne, świadome emocji chatboty, systemy opowiadania historii i interaktywne książki mówione.
Przekształcanie opowieści w rozmowy
Autorzy zaczynają od 2 588 anglojęzycznych krótkich opowiadań dla dzieci zebranych z repozytorium online. Każde opowiadanie zawiera już listę głównych postaci, ale sam tekst jest napisany jako ciągła proza z fragmentami dialogów w cudzysłowach. Celem zespołu jest przekształcenie tej swobodnej formy w czysty scenariusz z liniami w stylu „Mówca (Emocja): Dialog”, tak aby każde wypowiedziane zdanie można było badać, modelować lub nawet odtworzyć przez komputerowy głos. Łącznie wyodrębniają ponad 27 000 linii dialogowych powiązanych z ponad 2 500 unikalnymi postaciami.
Ustalenie, kto powiedział co
Ustalenie, kto mówi w opowiadaniu, jest trudniejsze niż się wydaje. Autorzy często używają zaimków typu „ona” lub fraz takich jak „dziecko” zamiast powtarzać imiona. Aby to rozplątać, pipeline tymczasowo maskuje każdą cytowaną linię wypowiedzi, a następnie uruchamia narzędzie FastCoref, które śledzi zaimki i opisy do właściwej postaci. Po przywróceniu oryginalnego dialogu inne narzędzie, BookNLP, przypisuje każdą linię konkretnemu mówcy i oznacza postacie podstawowymi cechami, takimi jak płeć. Linie niemające cudzysłowów traktowane są jako narracja, wymawiana przez domyślnego „Narratora” i otrzymują neutralną etykietę emocjonalną, aby cała historia mogła być przedstawiona w formie scenariusza.
Nauczanie maszyn rozpoznawania emocji
Następnie badacze oznaczają ton emocjonalny każdej linii dialogowej. Trenują sieć neuronową na dużym zestawie danych z Twittera, gdzie krótkie teksty zostały oznaczone jednym z sześciu stanów emocjonalnych: radość, smutek, złość, strach, miłość i zaskoczenie. Model wykorzystuje dwukierunkowy GRU, rodzaj rekurencyjnej sieci neuronowej dobrze radzącej sobie z kolejnością słów w zdaniach. Po oczyszczeniu i tokenizacji tekstu model jest trenowany z dodatkowym uwzględnieniem rzadszych emocji, by zredukować uprzedzenia. Na wydzielonym zbiorze z Twittera osiąga około 94% dokładności ogólnej. Ten wytrenowany model stosuje się potem do dialogów z opowiadań, przypisując emocję każdej linii bez zmiany brzmienia, dzięki czemu oryginalny literacki styl zostaje zachowany.
Uchwycenie sedna każdej opowieści
Ponad to, kto mówi i jakie ma emocje, zestaw danych zapisuje też, o czym jest każde opowiadanie. W tym celu autorzy używają dużego modelu językowego (Mistral-7B) z ostro zaprojektowanym promptem, który prosi o dokładnie pięć słów kluczowych wyciągniętych z tekstu opowiadania. Te słowa kluczowe działają jako zwięzłe streszczenie — na przykład imiona, miejsca lub centralne przedmioty — i mogą być później użyte do „sterowania” generowaniem nowych historii. Ostatecznym rezultatem jest wielowarstwowa reprezentacja każdej historii: zestaw słów kluczowych, lista postaci i scenariusz, w którym każda linia ma przypisanego mówcę i etykietę emocjonalną. 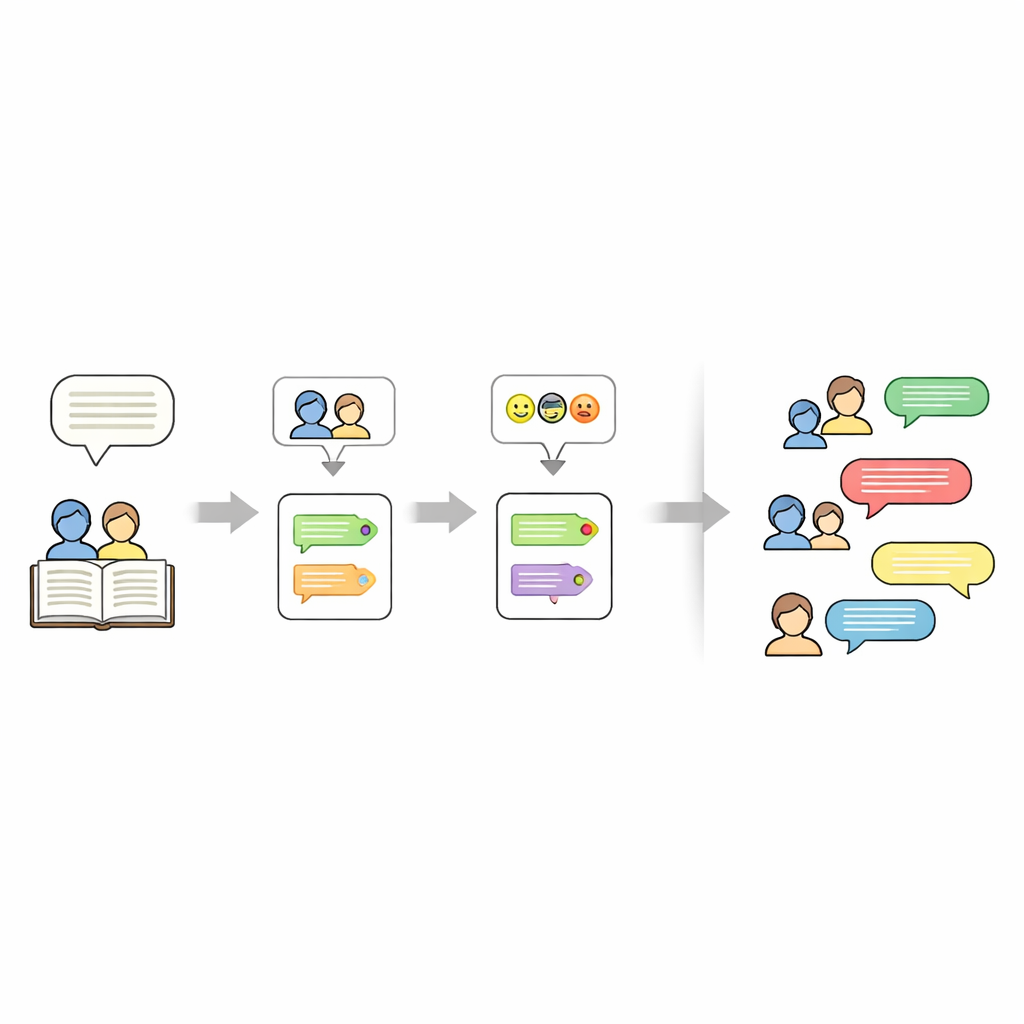
Testy dokładności i zastosowania w praktyce
Aby sprawdzić wiarygodność etykiet mówiących, zespół ręcznie przegląda setki linii dialogowych. Sam BookNLP poprawnie przypisuje około 73% wypowiedzi, ale w połączeniu z FastCoref dokładność wzrasta do około 90%, szczególnie w fragmentach z wieloma zaimkami. Analizują też, jak emocje przechodzą z jednej linii do następnej i znajdują realistyczne wzorce: na przykład radość często następuje po radości lub prowadzi do zaskoczenia, podczas gdy smutek częściej przechodzi w złość niż nagle zamienia się w radość. Wreszcie dopasowują model generatywny do tych danych, pokazując, że potrafi tworzyć nowe dialogi, które w dużym stopniu zachowują żądaną emocję lub słowa kluczowe historii, oraz sterują systemem syntezy mowy emocjonalnej, który słuchacze oceniają jako zarówno naturalny, jak i ekspresyjnie odpowiedni.
Co to oznacza dla przyszłych opowieści
Mówiąc prosto, praca ta przekształca zwykłe opowiadania dla dzieci w bogatą mapę tego, kto mówi, jakie ma emocje i o czym jest opowieść. Zamiast traktować tekst jako płaski strumień słów, zestaw danych pozwala komputerom śledzić postacie i zmieniające się emocje linia po linii. To czyni go potężnym elementem budulcowym dla przyszłych zastosowań — od audiobooków, które odtwarzają każdą postać we właściwym tonie, po narzędzia kreatywnego pisania i gry edukacyjne reagujące wyczuleniem na nastrój dziecka. Poprzez udostępnienie tej strukturalnej, świadomej emocji korpusu, autorzy dają badaczom nowy sposób badania i tworzenia naprawdę ekspresyjnych systemów narracyjnych.
Cytowanie: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Słowa kluczowe: dialog uwzględniający emocje, zestaw danych opowiadań, przypisanie mówiącego, synteza mowy emocjonalnej, Sztuczna inteligencja narracyjna