Clear Sky Science · ja
物語会話データセット:話者と感情が注釈された会話コーパス
物語の会話が重要な理由
物語を読むとき、私たちは本能的に誰が話しているか、彼らがどんな感情かを追い続けます。しかしコンピュータは、このような微妙で感情を含む会話を扱うのが苦手です。本論文は、人間と同じように物語の対話を理解できるようにする新しいデータセットを紹介します。つまり単に言葉を扱うのではなく、どの登場人物が話しているか、どの感情を表しているかを含めて扱います。本資源は何千もの児童向け物語から構築されており、より自然で感情に配慮したチャットボット、物語生成システム、読み聞かせアプリの実現を目指しています。
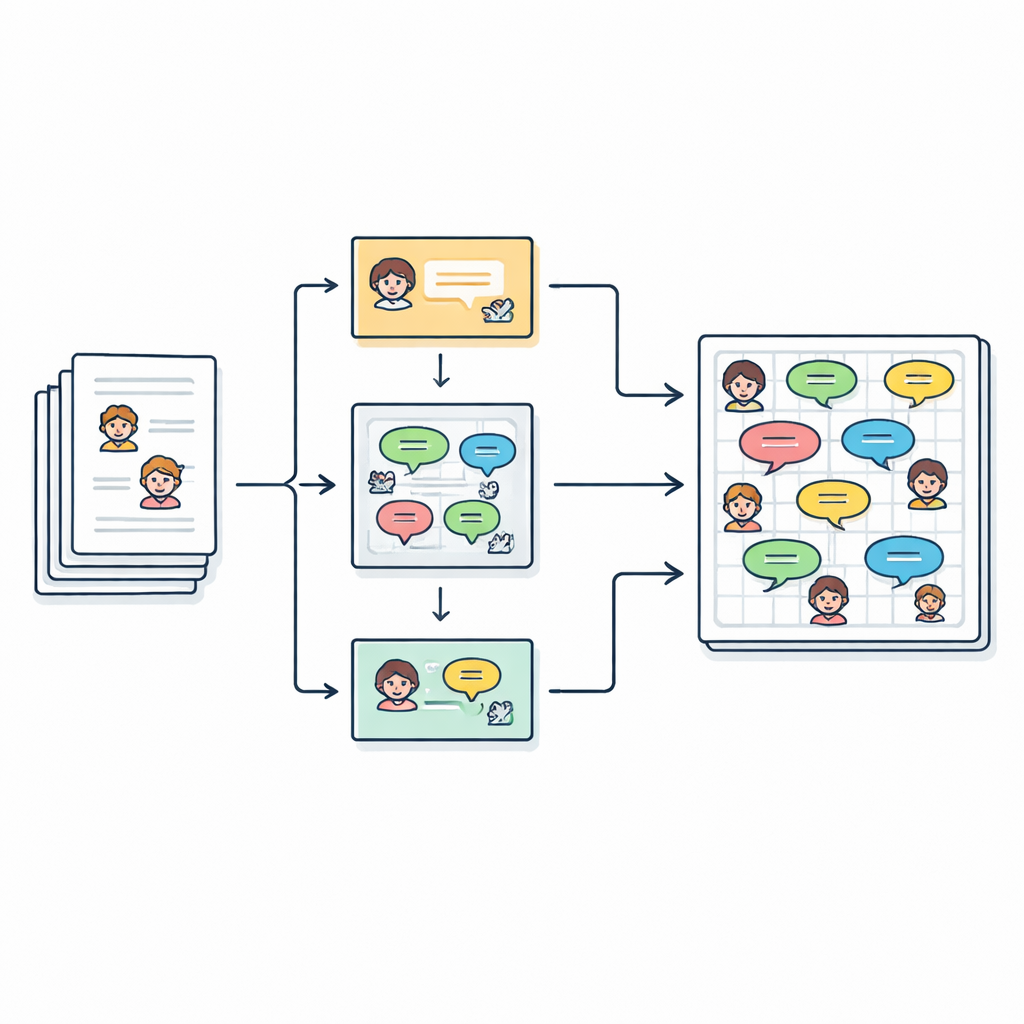
物語を会話に変換する
著者たちはオンラインリポジトリから収集した2,588編の英語の児童向け短編を出発点とします。各物語には主要登場人物が列挙されていますが、本文は連続した散文で書かれており、会話部分は引用符の中に挟まれています。チームの目的は、この自由形式の文章を「話者(感情):発話」のようなきれいな台本に変換することで、発話ごとに解析・モデル化・音声で再現できるようにすることです。最終的に、2,500人以上の異なる登場人物に結び付けられた27,000以上の対話行を抽出しています。
誰が何を言ったかを見つける
物語中で誰が話しているかを特定する作業は、一見よりも難しいです。著者はしばしば名前を繰り返さず「彼女」や「その子供」のような代名詞や描写を用います。これを解きほぐすために、パイプラインはまず引用された各発話行を一時的にマスクし、次にFastCorefというツールを使って代名詞や記述を正しい登場人物に追跡します。元の対話を復元した後、別のツールであるBookNLPが各行を特定の話者に割り当て、性別などの基本的な特徴もタグ付けします。引用符に囲まれていない行は語り部の叙述として扱われ、暗黙の「Narrator(語り手)」が発話し中立的な感情ラベルが付与され、物語全体を台本形式で表現できるようにします。
機械に感情を聞かせる学習
次に、研究者たちは各対話行の感情トーンをラベル付けします。彼らは短文が6つの感情(喜び、悲しみ、怒り、恐れ、愛、驚き)のいずれかでタグ付けされた大規模なTwitterデータセットでニューラルネットワークモデルを訓練します。モデルは双方向GRUを使用しており、文中の語順を扱うのに適した一種のリカレントニューラルネットワークです。テキストのクレンジングとトークナイズの後、希少な感情に対して追加の重みを与えてバイアスを軽減する形で学習させます。保持用のTwitterデータに対する評価では、全体で約94%の精度に達しています。この訓練済みモデルを物語の対話に適用して、文面を変えずに各行に感情を割り当てることで、元の文芸的な文体を保ったまま注釈を付与します。
物語の核心を捉える
誰が話すか、どのように感じるかに加え、データセットは各物語が何についてかも記録します。これには大規模言語モデル(Mistral-7B)を用い、物語本文からちょうど5つのキーワードを抽出するよう精緻に設計されたプロンプトを使います。これらのキーワードは名前、場所、中心となる物体などを含む簡潔な要約として機能し、後で新しい物語生成を「誘導(steer)」するために利用できます。最終成果物は物語ごとに階層化された表現です:キーワードの集合、登場人物の一覧、各行に話者と感情タグが付いた台本です。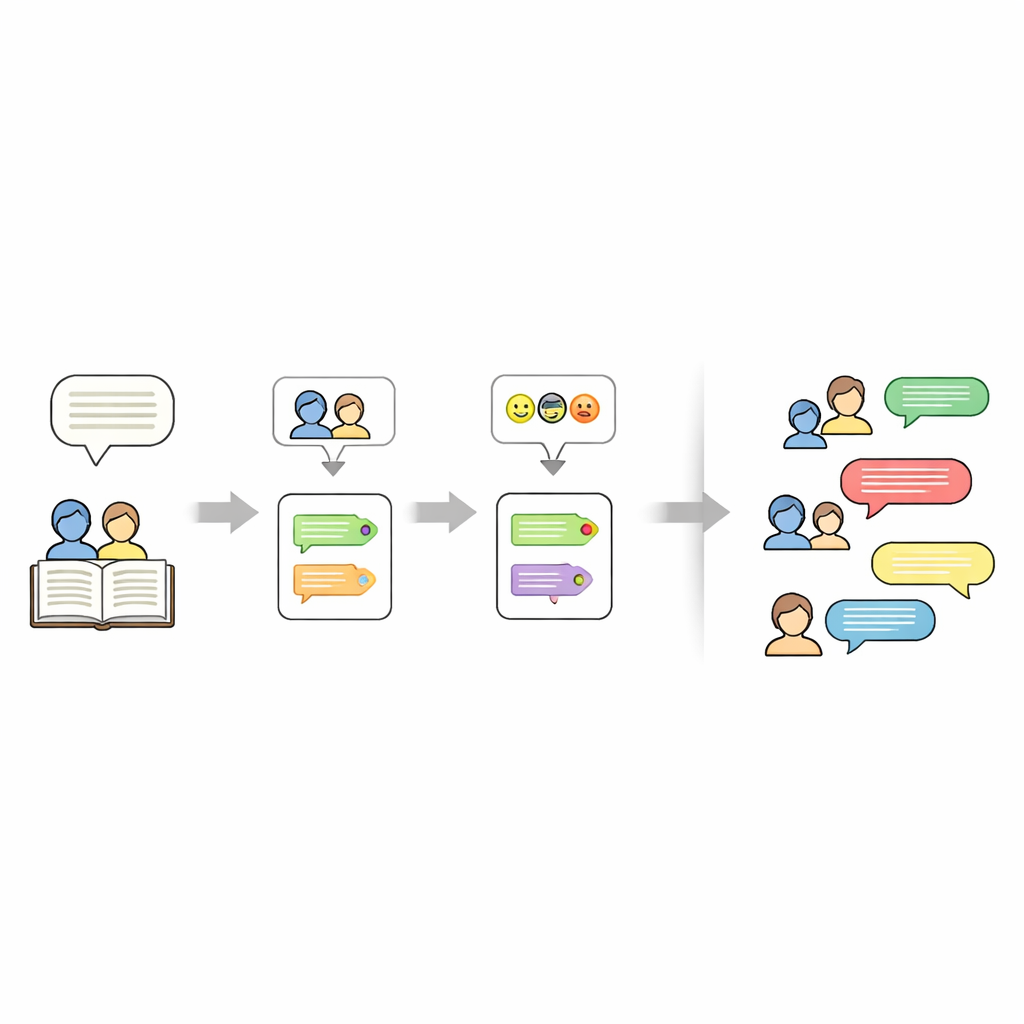
精度の検証と現実的応用
話者ラベルの信頼性を確認するため、チームは数百の対話行を手作業でレビューします。BookNLP単独では発話の約73%を正しく帰属させますが、FastCorefと組み合わせると特に代名詞が多い箇所で精度は約90%に跳ね上がります。彼らはまた、行から行への感情の流れを分析し、現実的なパターンを見出します。たとえば、喜びはしばしば喜びにつづいたり驚きにつながったりし、悲しみは瞬時に喜びに戻るよりも怒りへ移行する傾向があります。最後に、このデータで生成モデルをファインチューニングし、要求された感情や物語キーワードを概ね保持した新しい対話を生成できること、そして感情を反映したテキスト読み上げシステムを駆動すると聞き手が自然で表現豊かだと評価することを示します。
今後の物語に向けて
簡潔に言えば、本研究は普通の児童向け物語を、誰が話しているか、彼らがどのように感じているか、そして物語の主題が何かを示す豊かな地図へと変換します。テキストを平坦な語の流れとして扱うのではなく、データセットによってコンピュータは行ごとに登場人物とその変化する感情を追えるようになります。これは、各登場人物を適切な口調で演じるオーディオブックから、子どもの気分に敏感に反応する創作支援ツールや教育ゲームに至るまで、将来の応用の強力な基盤となります。構造化され感情に配慮したこのコーパスを自由に公開することで、著者たちは表現豊かな物語システムを研究・構築するための新しい道を研究者に提供します。
引用: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
キーワード: 感情対応型対話, 物語データセット, 話者帰属, 感情音声合成, 物語生成AI