Clear Sky Science · nl
Dataset Voor Narratieve Dialoog: Conversatiecorpus Met Spreker- en Emotieannotaties
Waarom pratende verhalen ertoe doen
Als we een verhaal lezen, houden we instinctief bij wie er spreekt en hoe die persoon zich voelt. Computers hebben daarentegen moeite met dit soort subtiele, emotionele conversaties. Dit artikel introduceert een nieuwe dataset die machines helpt verhaaldialoog te begrijpen zoals mensen dat doen: niet alleen de woorden, maar ook welke personage spreekt en welke emotie die uitdrukt. De bron is opgebouwd uit duizenden kinder-verhalen en is bedoeld om natuurlijkere, emotie-bewuste chatbots, vertelssystemen en pratende boeken mogelijk te maken.
Verhalen omzetten in gesprekken
De auteurs beginnen met 2.588 Engelstalige korte kinder-verhalen die ze uit een online verzameling haalden. Elk verhaal vermeldt al zijn hoofdpersonages, maar de tekst zelf is geschreven als doorlopende proza, met gedeelten dialoog tussen aanhalingstekens. Het doel van het team is deze vrije vorm om te zetten in een helder script met regels als “Spreker (Emotie): Dialoog,” zodat elke gesproken zin bestudeerd, gemodelleerd of zelfs uitgevoerd kan worden door een computerstem. In totaal extraheren ze meer dan 27.000 dialoogregels gekoppeld aan meer dan 2.500 onderscheiden personages.
Uitvinden wie wat zei
Uitzoeken wie er in een verhaal spreekt is lastiger dan het lijkt. Auteurs gebruiken vaak voornaamwoorden zoals “zij” of frasen als “het kind” in plaats van namen te herhalen. Om dit te ontwarren maskeert de pijplijn eerst tijdelijk elke geciteerde spraakregel, en gebruikt dan een tool genaamd FastCoref om voornaamwoorden en omschrijvingen terug te leiden naar het juiste personage. Na het herstellen van de oorspronkelijke dialoog wijst een andere tool, BookNLP, elke regel aan een specifieke spreker toe en tagt personages ook met basale eigenschappen zoals geslacht. Regels die niet tussen aanhalingstekens staan worden behandeld als vertelling, uitgesproken door een impliciete “Verteller” en krijgen een neutraal emotielabel, zodat het volledige verhaal in scriptvorm kan worden weergegeven.
Machines leren emoties te horen
Vervolgens labelen de onderzoekers de emotionele toon van elke dialoogregel. Ze trainen een neuraal netwerkmodel op een grote Twitter-dataset waarin korte teksten getagd zijn met een van zes emoties: vreugde, verdriet, woede, angst, liefde en verrassing. Het model gebruikt een bidirectionele GRU, een type recurrent neuraal netwerk dat goed omgaat met woordvolgorde in zinnen. Na het schoonmaken en tokenizen van de tekst trainen ze het model met extra gewicht op zeldzamere emoties om bias te verminderen. Op niet-gebruikte Twitter-gegevens haalt het ongeveer 94% nauwkeurigheid overall. Dit getrainde model wordt vervolgens toegepast op de verhaaldialogen en kent elke regel een emotie toe zonder de bewoording te veranderen, zodat de oorspronkelijke literaire stijl behouden blijft.
Het hart van elk verhaal vastleggen
Buiten wie spreekt en hoe die zich voelt, legt de dataset ook vast waar elk verhaal over gaat. Hiervoor gebruiken de auteurs een groot taalmodel (Mistral-7B) met een zorgvuldig ontworpen prompt die vraagt om precies vijf trefwoorden afkomstig uit de verhaaltekst. Deze trefwoorden fungeren als een compacte samenvatting—zoals namen, locaties of centrale objecten—en kunnen later worden gebruikt om nieuwe verhaalgeneraties te sturen. Het eindresultaat is een gelaagde representatie voor elk verhaal: een set trefwoorden, een lijst personages en een script waarbij elke regel een spreker- en emotietag heeft. 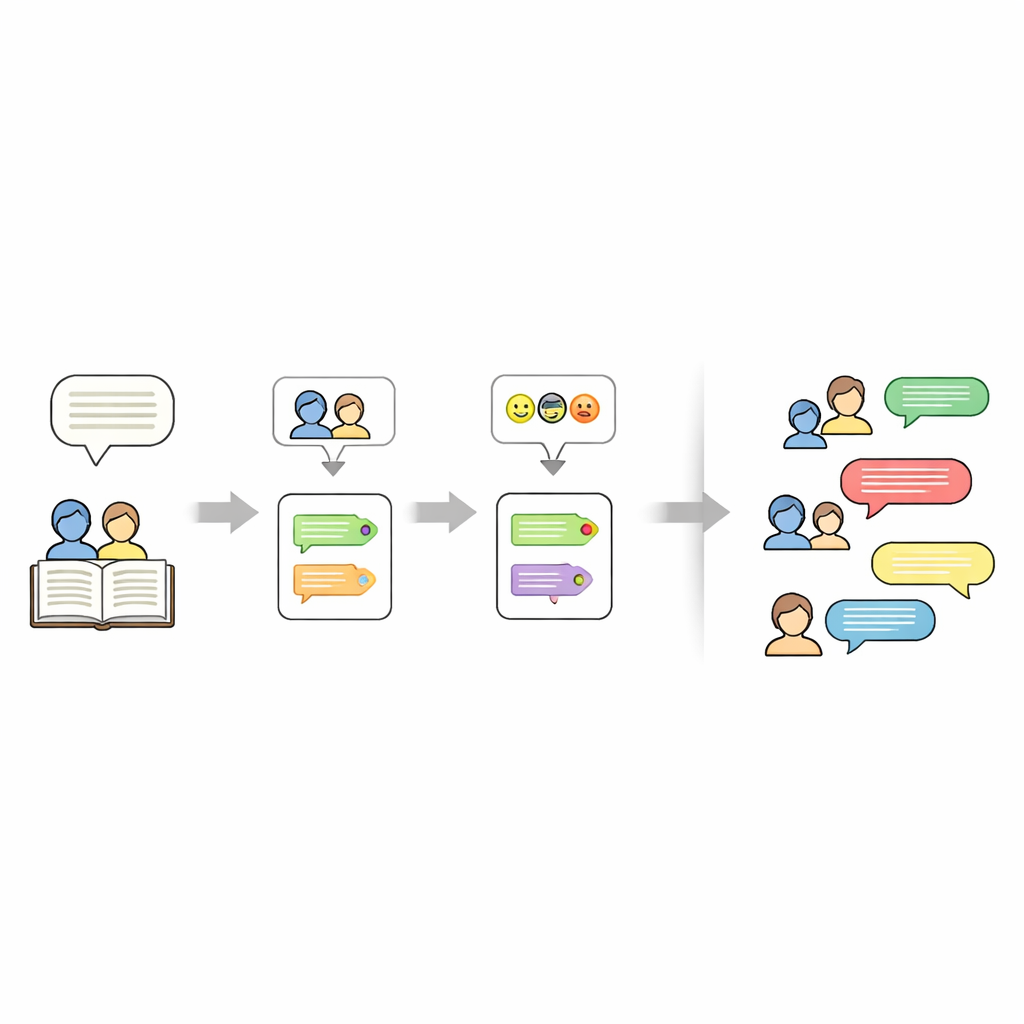
Testen van nauwkeurigheid en gebruik in de praktijk
Om te controleren hoe betrouwbaar de sprekerlabels zijn, beoordeelt het team handmatig honderden dialoogregels. Alleen met BookNLP worden ongeveer 73% van de uitspraken correct toegewezen, maar in combinatie met FastCoref stijgt de nauwkeurigheid naar rond de 90%, vooral in passages met veel voornaamwoorden. Ze analyseren ook hoe emoties van de ene regel naar de volgende vloeien en vinden realistische patronen: bijvoorbeeld dat vreugde vaak volgt op vreugde of leidt tot verrassing, terwijl verdriet eerder richting woede beweegt dan direct omslaat in vreugde. Ten slotte finetunen ze een generatief taalmodel op deze data, waarmee nieuwe dialogen worden gegenereerd die grotendeels de gevraagde emotie of verhaaltrefwoorden behouden, en gebruiken ze het om een emotionele tekst-naar-spraak-systeem aan te sturen dat luisteraars waarderen als zowel natuurlijk als expressief passend.
Wat dit betekent voor toekomstige verhalen
In simpele termen zet dit werk gewone kinderzegverhalen om in een rijke kaart van wie er spreekt, hoe ze zich voelen en waar het verhaal over gaat. In plaats van tekst te behandelen als een vlakke stroom woorden, stelt de dataset computers in staat personages en hun wisselende emoties regel voor regel te volgen. Dat maakt het een krachtig bouwblok voor toekomstige toepassingen, van luisterboeken die elk personage met de juiste toon opvoeren, tot creatieve schrijfhulpmiddelen en educatieve spellen die gevoelig reageren op de gemoedstoestand van een kind. Door dit gestructureerde, emotie-bewuste corpus vrij beschikbaar te maken, bieden de auteurs onderzoekers een nieuwe manier om werkelijk expressieve narratieve systemen te bestuderen en te bouwen.
Bronvermelding: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Trefwoorden: emotie-bewuste dialoog, dataset voor verhalen vertellen, spreker-toeschrijving, emotionele spraaksynthese, narratieve AI