Clear Sky Science · es
Conjunto de Datos de Diálogos Narrativos: Corpus Conversacional Anotado con Hablante y Emoción
Por qué importan las historias habladas
Cuando leemos una historia, de forma instintiva seguimos quién habla y cómo se siente. Sin embargo, los ordenadores tienen dificultades con ese tipo de conversación sutil y emocional. Este artículo presenta un nuevo conjunto de datos que ayuda a las máquinas a comprender el diálogo narrativo como lo hace la gente: no solo las palabras, sino qué personaje está hablando y qué emoción expresa. El recurso se construye a partir de miles de cuentos infantiles y está pensado para impulsar chatbots más naturales y con sensibilidad emocional, sistemas de narrativa y libros hablados.
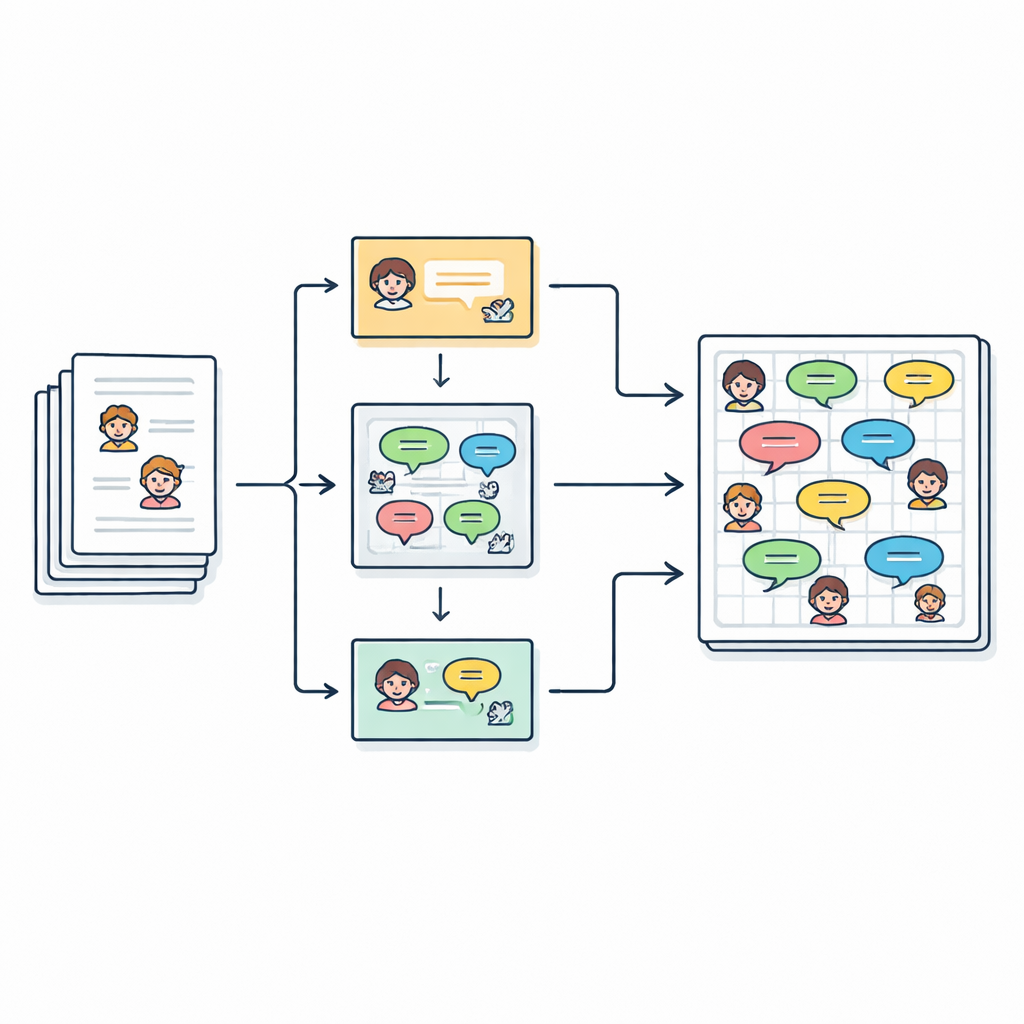
Convertir relatos en conversaciones
Los autores parten de 2.588 cuentos cortos en inglés para niños recogidos en un repositorio en línea. Cada historia ya lista a sus personajes principales, pero el texto está escrito como prosa continua, con fragmentos de diálogo entre comillas. El objetivo del equipo es transformar esta escritura libre en un guion limpio compuesto por líneas del tipo “Hablante (Emoción): Diálogo”, de modo que cada frase hablada pueda estudiarse, modelarse o incluso interpretarse por una voz computacional. En total, extraen más de 27.000 líneas de diálogo vinculadas a más de 2.500 personajes distintos.
Determinar quién dijo qué
Determinar quién habla en una historia es más complicado de lo que parece. Los autores suelen usar pronombres como “ella” o expresiones como “el niño” en lugar de repetir nombres. Para desenredar esto, la canalización enmascara temporalmente cada línea entrecomillada y luego ejecuta una herramienta llamada FastCoref para rastrear pronombres y descripciones hasta el personaje correcto. Tras restaurar el diálogo original, otra herramienta, BookNLP, asigna cada línea a un hablante específico y también etiqueta a los personajes con rasgos básicos como el género. Las líneas que no están entre comillas se tratan como narración, habladas por un “Narrador” implícito y se les asigna una etiqueta emocional neutra, de modo que la historia completa pueda representarse en forma de guion.
Enseñar a las máquinas a reconocer emociones
A continuación, los investigadores etiquetan el tono emocional de cada línea de diálogo. Entrenan un modelo neuronal con un gran conjunto de datos de Twitter donde textos cortos han sido marcados con una de seis emociones: alegría, tristeza, ira, miedo, amor y sorpresa. El modelo utiliza un GRU bidireccional, un tipo de red neuronal recurrente que maneja bien el orden de las palabras en las frases. Tras limpiar y tokenizar el texto, entrenan el modelo dando mayor peso a las emociones menos frecuentes para reducir sesgos. En datos de Twitter reservados alcanza alrededor del 94% de precisión global. Este modelo entrenado se aplica luego a los diálogos de los cuentos, asignando una emoción a cada línea sin cambiar la redacción, de modo que se preserva el estilo literario original.
Capturar el corazón de cada relato
Además de quién habla y cómo se siente, el conjunto de datos también registra de qué trata cada historia. Para ello, los autores usan un gran modelo de lenguaje (Mistral-7B) con un prompt cuidadosamente diseñado que pide exactamente cinco palabras clave extraídas del texto de la historia. Estas palabras clave actúan como un resumen compacto —nombres, lugares u objetos centrales— y pueden usarse después para “orientar” nuevas generaciones de relatos. El resultado final es una representación por capas de cada historia: un conjunto de palabras clave, una lista de personajes y un guion donde cada línea tiene un hablante y una etiqueta de emoción. 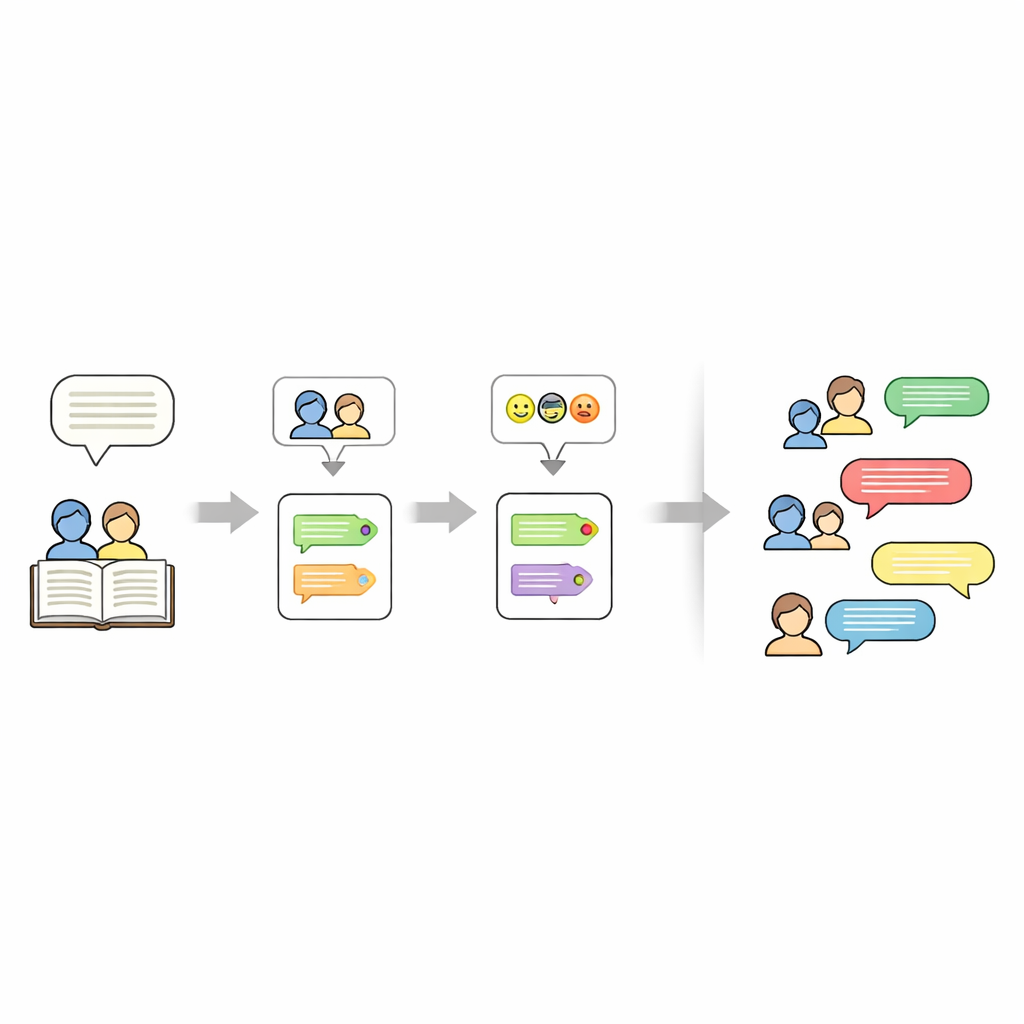
Probar la precisión y el uso en el mundo real
Para comprobar la fiabilidad de las etiquetas de hablante, el equipo revisa manualmente cientos de líneas de diálogo. Usando solo BookNLP se atribuye correctamente alrededor del 73% de las intervenciones, pero cuando se combina con FastCoref, la precisión salta hasta aproximadamente el 90%, especialmente en pasajes con muchos pronombres. También analizan cómo fluyen las emociones de una línea a la siguiente y encuentran patrones realistas: por ejemplo, la alegría suele seguir a la alegría o llevar a la sorpresa, mientras que la tristeza es más probable que evolucione hacia la ira que flipar instantáneamente a la alegría. Finalmente, afinan un modelo generativo de lenguaje con estos datos, demostrando que puede producir nuevo diálogo que en gran medida preserva la emoción o las palabras clave solicitadas, y alimentan un sistema de texto a voz emocional que los oyentes califican como natural y expresivamente apropiado.
Lo que esto significa para futuras historias
En términos sencillos, este trabajo convierte cuentos infantiles ordinarios en un mapa rico de quién habla, cómo se siente y de qué trata el relato. En lugar de tratar el texto como una secuencia plana de palabras, el conjunto de datos permite a las máquinas seguir a los personajes y sus emociones cambiantes de línea en línea. Esto lo convierte en un bloque de construcción potente para aplicaciones futuras, desde audiolibros que interpretan a cada personaje con el tono adecuado, hasta herramientas creativas de escritura y juegos educativos que responden con sensibilidad al estado de ánimo de un niño. Al publicar libremente este corpus estructurado y con conciencia emocional, los autores ofrecen a los investigadores una nueva manera de estudiar y construir sistemas narrativos verdaderamente expresivos.
Cita: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Palabras clave: diálogo con conciencia emocional, conjunto de datos de relatos, asignación de hablante, síntesis de voz emocional, IA narrativa