Clear Sky Science · en
Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus
Why talking stories matter
When we read a story, we instinctively keep track of who is speaking and how they feel. Computers, however, struggle with this kind of subtle, emotional conversation. This paper introduces a new dataset that helps machines understand story dialogue the way people do: not just the words, but which character is speaking and what emotion they are expressing. The resource is built from thousands of children’s stories and is designed to power more natural, emotionally aware chatbots, storytelling systems, and talking books.
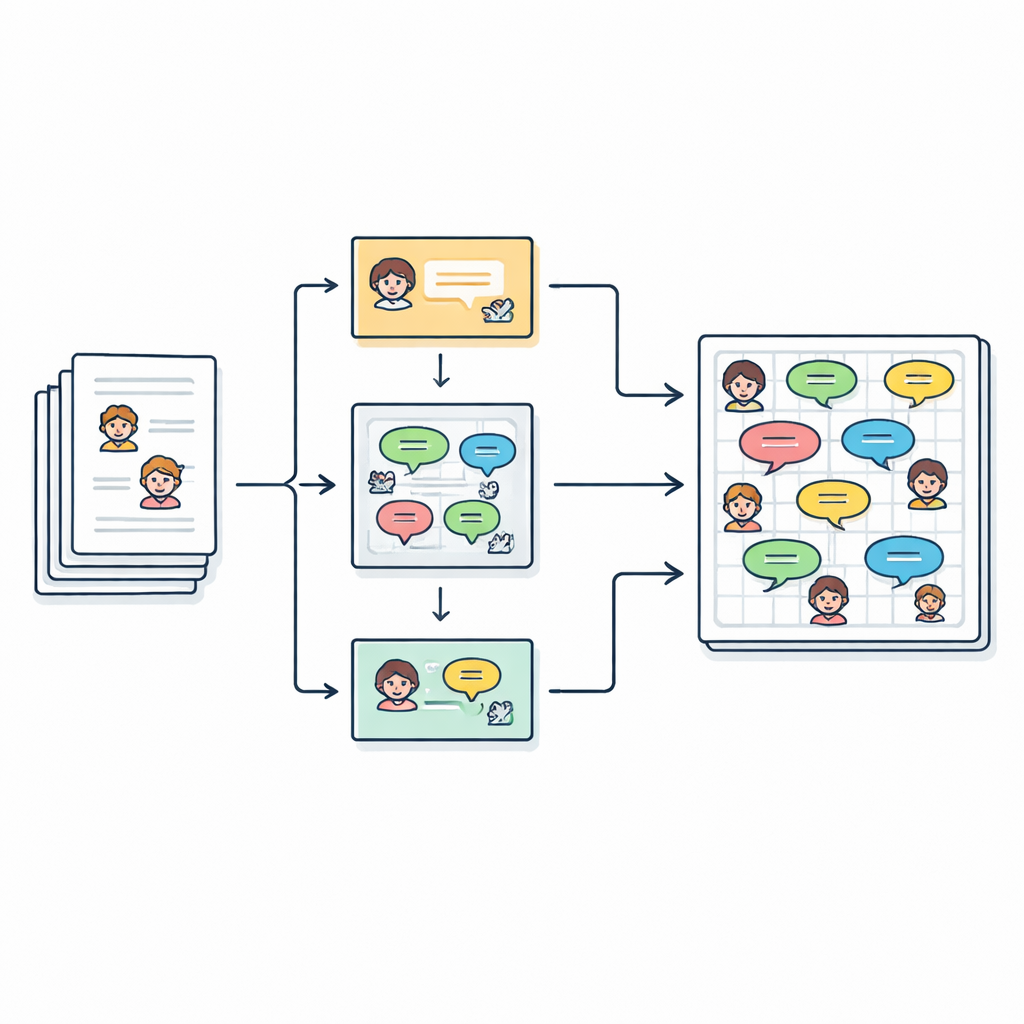
Turning stories into conversations
The authors start from 2,588 English children’s short stories collected from an online repository. Each story already lists its main characters, but the text itself is written as continuous prose, with bits of dialogue tucked inside quotation marks. The team’s goal is to turn this free-form writing into a clean script made of lines like “Speaker (Emotion): Dialogue,” so that every spoken sentence can be studied, modeled, or even performed by a computer voice. In total, they extract over 27,000 dialogue lines linked to more than 2,500 distinct characters.
Finding who said what
Working out who is speaking in a story is trickier than it sounds. Authors often use pronouns like “she” or phrases like “the child” instead of repeating names. To untangle this, the pipeline first temporarily masks each quoted line of speech, then runs a tool called FastCoref to trace pronouns and descriptions back to the right character. After restoring the original dialogue, another tool, BookNLP, assigns each line to a specific speaker and also tags characters with basic traits such as gender. Lines that are not in quotation marks are treated as narration, spoken by an implicit “Narrator” and given a neutral emotional label, so that the full story can be represented in script form.
Teaching machines to hear emotions
Next, the researchers label the emotional tone of every dialogue line. They train a neural network model on a large Twitter dataset where short texts have been tagged with one of six emotions: joy, sadness, anger, fear, love, and surprise. The model uses a bidirectional GRU, a kind of recurrent neural network that is good at handling word order in sentences. After cleaning and tokenizing the text, they train the model with extra weight on rarer emotions to reduce bias. On held-out Twitter data, it reaches about 94% accuracy overall. This trained model is then applied to the story dialogues, assigning an emotion to each line without changing the wording, so the original literary style is preserved.
Capturing the heart of each tale
Beyond who speaks and how they feel, the dataset also records what each story is about. For this, the authors use a large language model (Mistral-7B) with a carefully designed prompt that asks for exactly five keywords drawn from the story text. These keywords act as a compact summary—such as names, locations, or central objects—and can later be used to “steer” new story generations. The final result is a layered representation for every story: a set of keywords, a list of characters, and a script where each line has a speaker and an emotion tag. 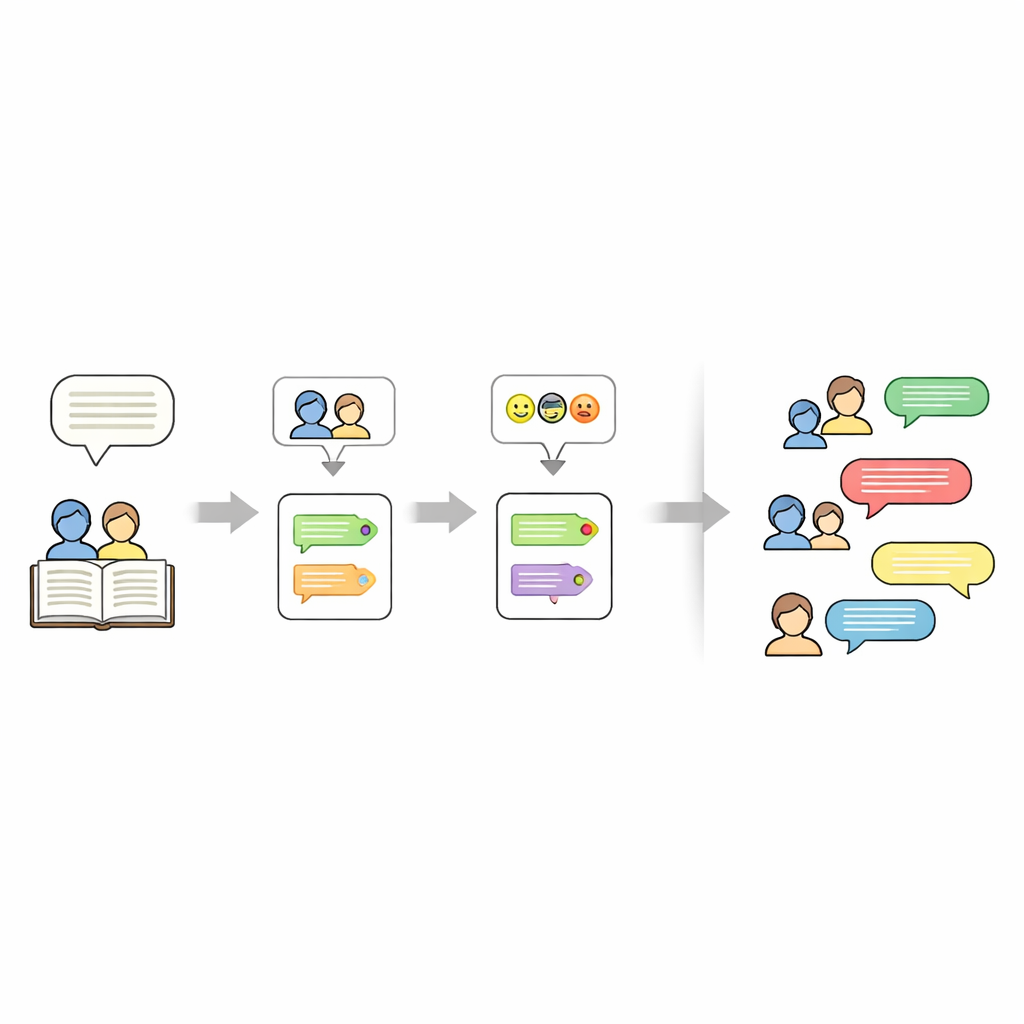
Testing accuracy and real-world use
To check how reliable the speaker labels are, the team manually reviews hundreds of dialogue lines. Using BookNLP alone correctly attributes about 73% of utterances, but when combined with FastCoref, accuracy jumps to around 90%, especially in passages with many pronouns. They also analyze how emotions flow from one line to the next and find realistic patterns: for example, joy often follows joy or leads to surprise, while sadness is more likely to move toward anger than instantly flip to joy. Finally, they fine-tune a generative language model on this data, showing it can produce new dialogue that largely preserves the requested emotion or story keywords, and they drive an emotional text-to-speech system that listeners rate as both natural and expressively appropriate.
What this means for future stories
In simple terms, this work turns ordinary children’s stories into a rich map of who is talking, how they feel, and what the tale is about. Instead of treating text as a flat stream of words, the dataset lets computers follow characters and their shifting emotions from line to line. This makes it a powerful building block for future applications, from audiobooks that perform each character with the right tone, to creative writing tools and educational games that respond sensitively to a child’s mood. By freely releasing this structured, emotionally aware corpus, the authors give researchers a new way to study and build truly expressive narrative systems.
Citation: Patil, U., Hanmante, S., Patil, S. et al. Narrative Dialogue Dataset: Speaker and Emotion Annotated Conversational Corpus. Sci Data 13, 507 (2026). https://doi.org/10.1038/s41597-026-06891-3
Keywords: emotion-aware dialogue, storytelling dataset, speaker attribution, emotional speech synthesis, narrative AI